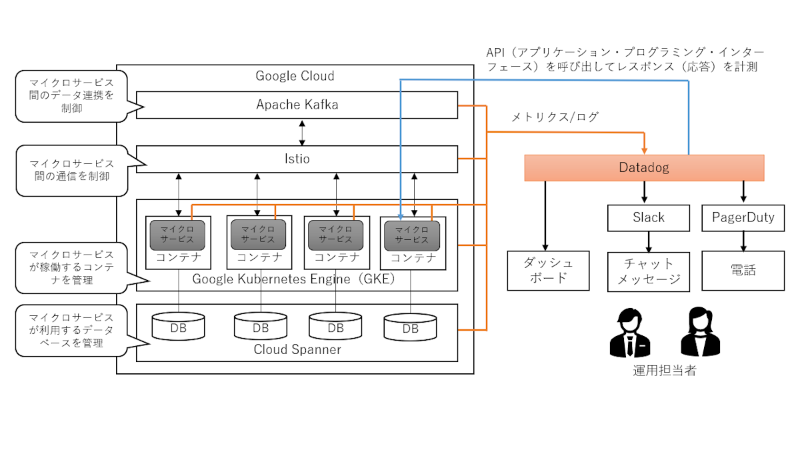
ログ@Datadog¶
はじめに¶
本サイトにつきまして、以下をご認識のほど宜しくお願いいたします。
01. 仕組み¶
バックエンド¶
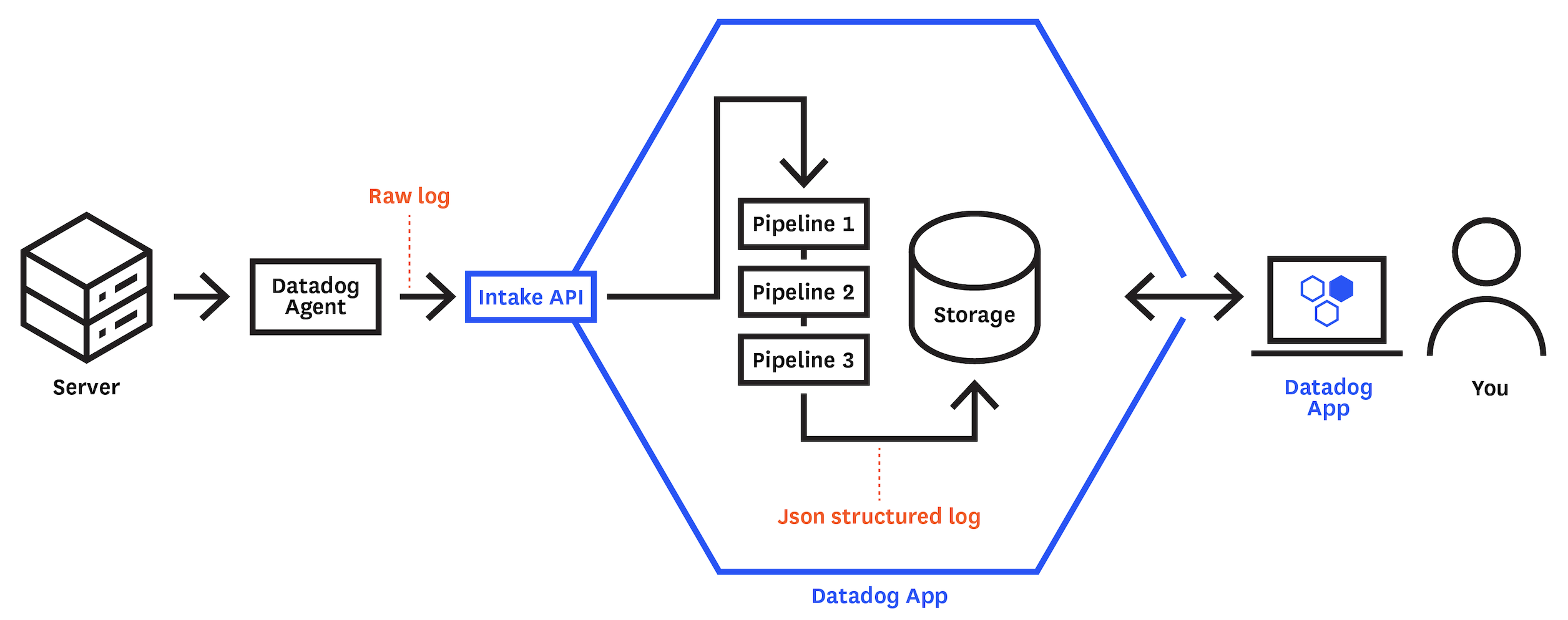
(1)-
サーバーの場合、稼働するdatadogエージェントが、datadog-APIにアプリケーションログを送信する。コンテナの場合、FluentBitが代わりにアプリケーションログを送信する。
(2)-
Datadogにて、ログはパイプラインで処理され、構造化ログになる。
(3)-
ユーザーは、ログの属性値を基に、ログを検索できるようになる。
フロントエンド¶
(1)-
ブラウザのコンソールに出力されるログを収集する。
(2)-
Datadogにて、ログはパイプラインで処理され、構造化ログになる。
(3)-
ユーザーは、ログの属性値を基に、ログを検索できるようになる。
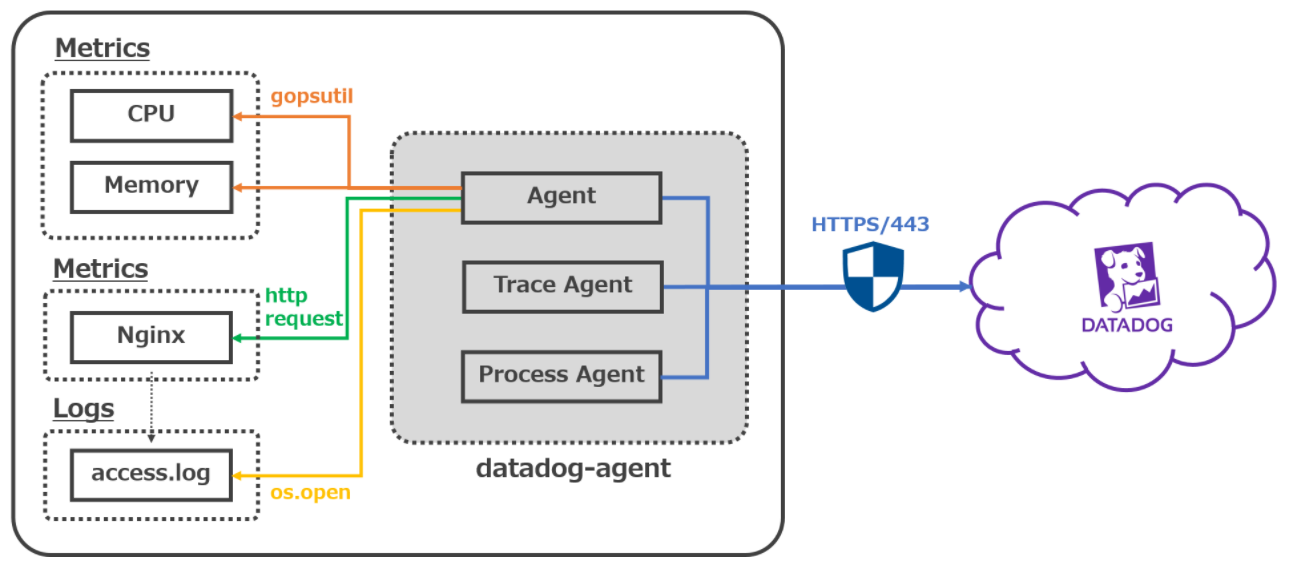
02. ログエージェント (サーバーの場合)¶
ログエージェントとは¶
デーモンであるdatadogエージェントに含まれている。
アプリケーションからログを収集し、Datadogに転送する。
セットアップ¶
▼ /etc/datadog-agent/datadog.yamlファイル¶
03. ログエージェント (AWS ECS Fargateの場合)¶
ログエージェントとは¶
サーバーの場合とは異なり、AWS ECS Fargateのdatadogエージェントはログを収集できない。
そのため、代わりにFireLensコンテナを使用する必要がある。
メトリクスと分散トレースであれば収集できる。
FireLensコンテナ¶
FluentBitを稼働させたコンテナのこと。
Datadogの代わりにログを収集する。
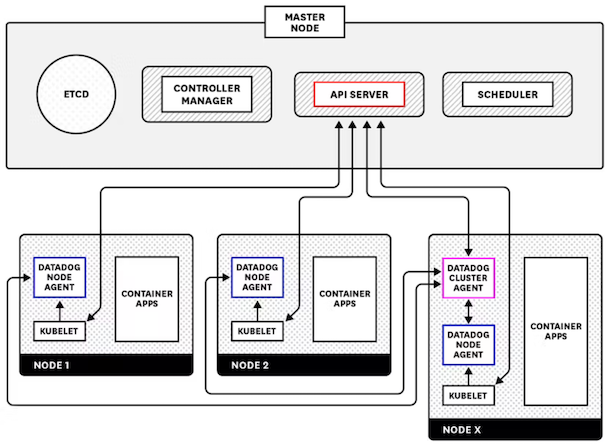
02-02. Cluster/Nodeエージェント (Kubernetesの場合)¶
Cluster/Nodeエージェントとは¶
▼ Kubernetesの場合¶
ClusterやワーカーNodeからメトリクスを受信し、コントロールプレーンNodeのkube-apiserverに転送する。
▼ Kubernetes + Istioの場合¶
記入中...
04. ブラウザのコンソールログの収集¶
ブラウザログSDK¶
▼ ブラウザログSDKとは¶
ブラウザ上のJavaScriptで実行され、console.errorメソッドの実行結果、キャッチされていない例外、ネットワークエラー、を含む構造化ログをDatadogに送信する。
▼ パラメーター¶
▼ 送信される構造化ログ¶
statusキー
{
"content":
{
"attributes":
{
"error": {"origin": "network", "stack": "Failed to load"},
"http":
{
"useragent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.93 Safari/537.36",
},
"network": {"client": {"ip": "18.180.199.160"}},
"service": "prd-foo-ssg",
"session_id": "*****",
`#コンソールログのステータス`
"status": "error",
"view": {"referrer": "", "url": "https://example.com/"},
},
"message": "XHR error POST https://async.jp",
"service": "prd-foo-ssg",
"tags":
[
"version:<バージョンタグ>",
"sdk_version:<バージョンタグ>",
"service:prd-foo-ssg",
"source:browser",
"env:prd",
],
},
"id": "*****",
}
セットアップ¶
▼ NPMの場合¶
*実装例*
Nuxt.jsの場合、エントリーポイントはnuxt.configファイルである。
プラグインとして実装し、これをエントリーポイントで読み込むようにする。
# .env.datadogファイル
# Datadogにおけるクライアントトークン
DATADOG_CLIENT_TOKEN=*****
# Datadogにおけるログのタグ値
DATADOG_ENV=prd
DATADOG_SERVICE=foo
DATADOG_VERSION=<バージョンタグ>
// nuxt.configファイル
import { Configuration } from '@nuxt/types'
import baseConfig from './nuxt.config'
// .env.datadogファイルの読み込む
dotenv.config({ path: resolve(process.cwd(), '.env.datadog') })
const {
DATADOG_CLIENT_TOKEN,
DATADOG_ENV,
DATADOG_SERVICE,
DATADOG_VERSION,
} = process.env
const nuxtConfig: Configuration = {
publicRuntimeConfig: {
datadog: {
// SSGで参照するためpublicに定義する
clientToken: DATADOG_CLIENT_TOKEN,
env: DATADOG_ENV,
service: DATADOG_SERVICE,
version: DATADOG_VERSION,
},
},
...
plugins: [
...(baseConfig.plugins || []),
// SSGのみで使用するため、clientモードとする。
{
src: '@/plugins/datadog/browserLogsForSsg',
mode: 'client'
},
],
...
}
// プラグインファイル
import {Plugin, Context} from "@nuxt/types";
import {datadogLogs} from "@datadog/browser-logs";
const browserLogsForSsgPlugin: Plugin = ({$config}: Context) => {
// 性能とログの重要性の観点から、開発環境のログを送信しないようにする
if (!$config.datadog.clientToken) {
return;
}
// 初期化
datadogLogs.init({
clientToken: $config.datadog.clientToken,
env: $config.datadog.env,
service: $config.datadog.service + "-ssg",
version: $config.datadog.version,
});
};
export default browserLogsForSsgPlugin;
05. ログの識別子¶
属性¶
▼ 予約済み属性¶
| 属性名 | 説明 | 補足 | 例 |
|---|---|---|---|
host |
ログの作成元のホスト名を示す。 | ログが作成元とは別の場所から受信した場合に役立つ。datadogコンテナの環境変数にて、DD_HOSTNAMEを使用してhost属性を設定する。これにより、ホストマップでホストを俯瞰できるようになるのみでなく、ログエクスプローラでホストタグが属性として付与される。他にAWSインテグレーションでは、送信元のロググループ名やバケット名が付与される。 |
・foo・ foo-backend・ foo-frontend・ foo-log-group・ foo-bucket |
source |
ログの作成元の名前を示す。 | ベンダー名を使用するとわかりやすい。 | ・laravel・ nginx・ redis |
status |
ログのレベルを示す。 | ||
service |
ログの作成元のアプリケーション名を示す。 | ログとAPM分散トレースを紐付けるため、両方に同じ名前を割り当てる必要がある。 | ・foo・ bar-backend・ baz-frontend |
trace_id |
ログを分散トレースやスパンと紐付けるIDを示す。 | ||
message |
ログメッセージを示す。 | 受信したログが非構造化ログの場合、これはDatadogの基底構造化ログのmessage属性に割り当てられる。一方で、構造化ログであった場合はmessage属性は使用されない。 |
▼ 標準属性¶
デフォルトで用意された属性。
▼ スタックトレース属性¶
スタックトレースログを構成する要素に付与される属性のこと。
| 属性名 | 説明 |
|---|---|
logger.name |
ログパッケージの名前を示す。 |
logger.thread_name |
スレッド名を示す。 |
error.stack |
スタックトレースログ全体を示す。 |
error.message |
スタックトレースログのメッセージ部分を示す。 |
error.kind |
エラーの種類 (Exception、OSErrorなど) を示す。 |
タグ¶
06. 収集されたログの送信¶
EC2におけるログの送信¶
▼ PHP Monologの場合¶
LogパッケージにMonologを採用している場合、/etc/datadog-agent/conf.d/php.dディレクトリ配下にconf.yamlファイルを作成する。ここに、Datadogにログを送信するための設定を実行する。
*実装例*
init_config:
instances:
## Log section
logs:
- type: file
path: "/path/to/laravel.log"
service: php
source: php
sourcecategory: sourcecode
AWS ECS Fargateにおけるログの送信¶
FireLensコンテナで稼働するFluentBitが、Datadogにログを送信する。
07. ログパイプライン¶
ログパイプラインとは¶
Datadogに送信されたログのメッセージから値を抽出し、構造化ログの各属性に割り当てる。
パイプラインのルールに当てはまらなかったされなかったログは、そのまま流入する。
属性ごとにファセットに対応しており、各ファセットの値判定ルールを基に、ログコンソール画面に表示される。
リマッパー系¶
▼ リマッパー¶
指定した属性/タグに割り当てられた値を、別の属性に割り当て直す。
再割り当て時に、元のデータ型を変更できる。
*例*
CloudWatchログから、以下のようなAPI Gatewayアクセスログの構造化ログを受信する例を考える。
{
"content":
{
"attributes":
{
"aws":
{
"awslogs":
{
"logGroup": "prd-foo-api-access-log",
"logStream": "be4fcfca38da39f3ad4190e2f325e5d8",
"owner": "123456789",
},
"function_version": "$LATEST",
"invoked_function_arn": "arn:aws:lambda:ap-northeast-1:<AWSアカウントID>:function:datadog-ForwarderStack-*****-Forwarder-*****",
},
"caller": "-",
"host": "prd-foo-api-access-log",
"httpMethod": "GET",
"id": "36472822677180929652719686832176844832038235205288853504",
"ip": "*.*.*.*",
"protocol": "HTTP/1.1",
"requestId": "4d0c0105-7c89-4384-8b3b-fcc63f701652",
"requestTime": "01/Jan/2021:12:00:00 +0000",
"resourcePath": "/users/{userId}",
"responseLength": "26",
"service": "apigateway",
"status": 200,
"timestamp": 1635497933028,
"user": "-",
},
"host": "prd-foo-api-access-log",
"service": "apigateway",
"tags":
[
"forwardername:datadog-forwarderstack-*****-forwarder-*****",
"source:apigateway",
"sourcecategory:aws",
"forwarder_memorysize:1024",
"forwarder_version:3.39.0",
],
"timestamp": "2021-01-01T12:00:00.000Z",
},
"id": "AQAAAXzLRfjkXhzqsgAAAABBWHpMUmxPM0FBQTFWVnRrNTVXbkx3QUE",
}
これに対して、リマッパーのルールを定義する。
例えば、リクエストに関する属性値をhttp属性内の各属性に割り当て直す。
{
"content":
{
"attributes":
{
"aws":
{
"awslogs":
{
"logGroup": "prd-foo-api-access-log",
"logStream": "be4fcfca38da39f3ad4190e2f325e5d8",
"owner": "123456789",
},
"function_version": "$LATEST",
"invoked_function_arn": "arn:aws:lambda:ap-northeast-1:<AWSアカウントID>:function:datadog-ForwarderStack-*****-Forwarder-*****",
},
"date_access": "01/Jan/2021:12:00:00 +0000",
"host": "prd-foo-api-access-log",
"http":
{
"auth": "-",
"ident": "-",
"method": "GET",
"request_id": "4d0c0105-7c89-4384-8b3b-fcc63f701652",
"status_category": "OK",
"status_code": 200,
"url": "/users/{userId}",
"url_details": {"path": "/users/{userId}"},
"version": "HTTP/1.1",
},
"id": "36472822677180929652719686832176844832038235205288853504",
"network": {"bytes_written": "26", "client": {"ip": "*.*.*.*"}},
"service": "apigateway",
"timestamp": 1635497933028,
},
"host": "prd-foo-api-access-log",
"service": "apigateway",
"tags":
[
"forwardername:datadog-forwarderstack-*****-forwarder-*****",
"source:apigateway",
"sourcecategory:aws",
"forwarder_memorysize:1024",
"forwarder_version:3.39.0",
],
"timestamp": "2021-01-01T12:00:00.000Z",
},
"id": "AQAAAXzLRfjkXhzqsgAAAABBWHpMUmxPM0FBQTFWVnRrNTVXbkx3QUE",
}
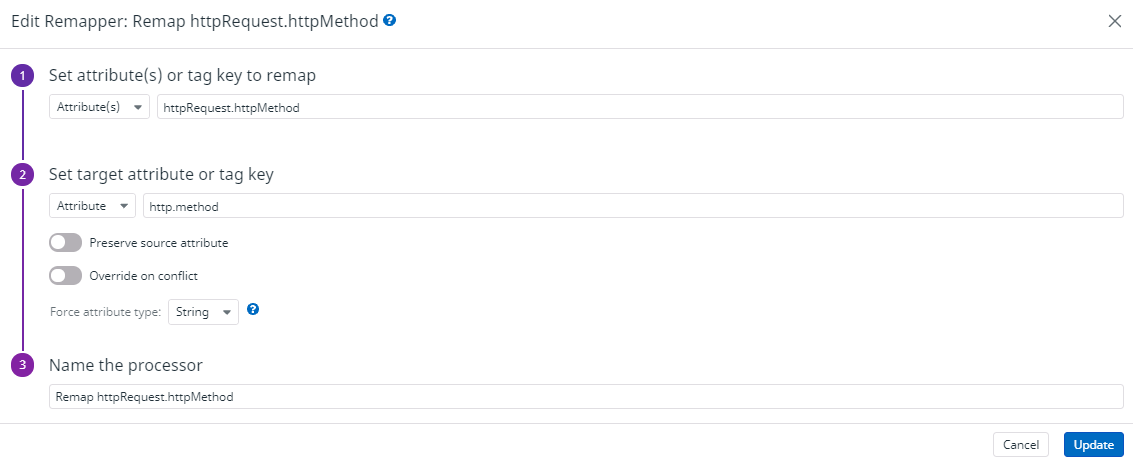
▼ ログステータスリマッパー¶
指定した属性/タグに割り当てられた値を、ルールを基に、ステータスファセットの各ステータス (INFO、WARNING、ERRORなど) として登録する。
ログコンソール画面にて、ステータスファセットとして表示される。
判定ルールについては、以下のリンクを参考にせよ。
▼ サービスリマッパー¶
指定した属性/タグに割り当てられた値を、サービスファセットのサービス名として登録する。

プロセッサー系¶
▼ カテゴリプロセッサー¶
検索条件に一致する属性を持つ構造化ログに対して、属性を新しく付与する。
*例*
Nginxから、以下のような非構造化ログを受信する例を考える。
*.*.*.* - - [01/Sep/2021:00:00:00 +0000] "GET /healthcheck HTTP/1.1" 200 17 "-" "ELB-HealthChecker/2.0"
以下のようなGrokパーサールールを定義する。
http.status_code属性にステータスコード値を割り当てる。
access.common %{_client_ip} %{_ident} %{_auth} \[%{_date_access}\] "(?>%{_method} |)%{_url}(?> %{_version}|)" %{_status_code} (?>%{_bytes_written}|-)
access.combined %{access.common} (%{number:duration:scale(1000000000)} )?"%{_referer}" "%{_user_agent}"( "%{_x_forwarded_for}")?.*
error.format %{date("yyyy/MM/dd HH:mm:ss"):date_access} \[%{word:level}\] %{data:error.message}(, %{data::keyvalue(": ",",")})?
これにより、構造化ログの各属性に値が割り当てられる。
{
"date_access": 12345,
"http":
{
"method": "GET",
"referer": "-",
"status_code": 200,
"url": "/healthcheck",
"useragent": "ELB-HealthChecker/2.0",
"version": "1.1",
},
"network": {"bytes_written": 17, "client": {"ip": "*.*.*.*"}},
}
これに対して、以下のようなカテゴリパーサーのルールを定義する。
http.status_code属性のステータスコード値に応じて、http.status_category属性にレベル値 (info、notice、warning、critical) に変換する。
ステータスコードとレベルの対応関係については、以下のリンクを参考にせよ。
INFO @http.status_code:[200 TO 299]
NOTICE @http.status_code:[300 TO 399]
WARNING @http.status_code:[400 TO 499]
CRITICAL @http.status_code:[500 TO 599]
これにより、構造化ログのhttp.status_category属性にログステータス値が割り当てられる。
補足として、http.status_category属性以外は元の構造化ログと同じため、省略している。
{"http": {status_category: "info"}, ...}
これに対して、ステータスリマッパーのルールを定義する。
http.status_category属性のログステータス値が、ステータスファセット (INFO、WARNING、ERRORなど) として登録されるようにする。
07-02. パーサー系¶
Grokパーサー¶
▼ Grokパーサーとは¶
パースルール (%{<マッチャー名>:<エクストラクト名>:<フィルター名>}) を使用して、message属性に割り当てられた非構造化ログを構造化し、構造化ログに付与する。また、Extractを使用すると、message属性以外に対してGrokパーサーを使用できるようになるため、構造化ログも扱えるようになる。
▼ パースルール¶
| 名前 | 説明 | 補足 |
|---|---|---|
| マッチャー名 | パース対象の文字列を検出できるマッチャー関数を設定する。それぞれマッチャーは、検出後に何らかの処理を実行する。 | ・https://docs.datadoghq.com/logs/log_configuration/parsing/?tab=matchers#matcher-and-filter |
| エクストラクト名 | 処理結果の出力先の属性を設定する。 | 出力先の属性が存在しない場合、これを新しく作成する。存在する場合は、既存の属性値を上書きする。 |
| フィルター名 | マッチャーの追加処理を実行するフィルター関数を設定する。 | ・https://docs.datadoghq.com/logs/log_configuration/parsing/?tab=filters#matcher-and-filter |
▼ 例1¶
Laravelから、以下のような非構造化ログを受信する例を考える。
[2021-01-01 00:00:00] staging.ERROR: ログのメッセージ
[2021-01-01 00:00:00] production.ERROR: ログのメッセージ
非構造化ログのため、ログは基底構造化ログのmessage属性に割り当てられる。
{
"content":
{
"attributes": {...},
"message": "[2021-01-01 00:00:00] staging.ERROR: ログのメッセージ",
"service": "prd-foo",
"tags": [...],
},
"id": "*****",
}
以下のようなGrokパーサールールを定義する。
dateマッチャーを使用して、またdate属性をエクストラクト先とする。
wordマッチャーを使用して、またlog_statusカスタム属性をエクストラクト先とする。
任意のルール名を設定できる。
dateマッチャーのタイムスタンプ形式の指定は以下を参考にせよ。
FooRule \[%{date("yyyy-MM-dd HH:mm:ss"):date}\]\s+(production|staging).%{word:log_status}\:.+
これにより、非構造化ログは以下の様に構造化され、構造化ログに付与される。
{
"date": 1630454400000, # エポック形式 (UNIX時間)
"log_status": "INFO",
}
▼ 例2¶
AWS WAFから以下のような構造化ログを受信する例を考える。
{
"timestamp": 1639459445119,
"formatVersion": 1,
"webaclId": "arn:aws:wafv2:ap-northeast-1:<AWSアカウントID>:regional/webacl/prd-foo-alb-waf/123456789",
"terminatingRuleId": "block-according-to-core-rule-set",
"action": "ALLOW",
"ruleGroupList":
[
{
"ruleGroupId": "AWS#AWSManagedRulesCommonRuleSet#Version_1.2",
"terminatingRule": null,
"nonTerminatingMatchingRules": [],
"excludedRules":
[
{
"exclusionType": "EXCLUDED_AS_COUNT",
"ruleId": "NoUserAgent_HEADER",
},
],
},
{
"ruleGroupId": "AWS#AWSManagedRulesSQLiRuleSet#Version_1.1",
"terminatingRule": null,
"nonTerminatingMatchingRules": [],
"excludedRules": null,
},
{
"ruleGroupId": "AWS#AWSManagedRulesPHPRuleSet#Version_1.1",
"terminatingRule": null,
"nonTerminatingMatchingRules": [],
"excludedRules": null,
},
{
"ruleGroupId": "AWS#AWSManagedRulesKnownBadInputsRuleSet#Version_1.1",
"terminatingRule": null,
"nonTerminatingMatchingRules": [],
"excludedRules": null,
},
],
"uri": "/foo",
"args": "",
"httpVersion": "HTTP/1.1",
"httpMethod": "GET",
}
以下のようなGrokパーサールールを定義する。
dataマッチャーを使用して、またwafacl_nameカスタム属性をエクストラクト先とする。
抽出する必要のない文字列は、ワイルドカード (.*) を指定する。
Rule .*\/webacl\/%{data:wafacl_name}\/.*
また、Extract機能の対象キーをwebaclId属性とする。
これにより、webaclId属性の非構造化ログは以下の様に構造化され、構造化ログに付与される。
{"wafacl_name": "prd-foo-alb-waf"}
Urlパーサー¶
▼ Urlパーサーとは¶
構造化ログのURL値からパスパラメーターやクエリパラメーターを検出し、詳細な属性として新しく付与する。
▼ 例1¶
とあるアプリケーションから、以下のような非構造化ログを受信する例を考える。
192.168.0.1 [2021-01-01 12:00:00] GET /users?paginate=10&fooId=1 200
非構造化ログのため、ログは基底構造化ログのmessage属性に割り当てられる。
{
"content":
{
"attributes": {...},
"message": "192.168.0.1 [2021-01-01 12:00:00] GET /users?paginate=10&fooId=1 200",
"service": "prd-foo",
"tags": [...],
},
"id": "*****",
}
以下のようなGrokパーサのルールを定義する。
各マッチャーでカスタム属性に値を割り当てる。
FooRule %{ipv4:network.client.ip}\s+\[%{date("yyyy-MM-dd HH:mm:ss"):date}\]\s+%{word:http.method}\s+%{notSpace:http.url}\s+%{integer:http.status_code}
これにより、構造化ログの各属性に値が割り当てられる。
{
"date": 1609502400000,
"http":
{"method": "GET", "status_code": 200, "url": "/users?paginate=10&fooId=1"},
"network": {"client": {"ip": "192.168.0.1"}},
}
これに対して、Urlパーサのルールを定義する。
http.url属性からパスパラメーターやクエリパラメーターを検出し、http.url_details属性として新しく付与する。
{
"date": 1609502400000,
"http":
{
"method": "GET",
"status_code": 200,
"url": "/users?paginate=10&fooId=1",
"url_details":
{"path": "/users", "queryString": {"fooId": 1, "paginate": 10}},
},
"network": {"client": {"ip": "192.168.0.1"}},
}
▼ 例2¶
CloudWatchログから、以下のようなAPI Gatewayアクセスログの構造化ログを受信する例を考える。
{
"content":
{
"attributes":
{
"aws":
{
"awslogs":
{
"logGroup": "prd-foo-api-access-log",
"logStream": "*****",
"owner": "123456789",
},
"function_version": "$LATEST",
"invoked_function_arn": "arn:aws:lambda:ap-northeast-1:<AWSアカウントID>:function:datadog-ForwarderStack-*****-Forwarder-*****",
},
"caller": "-",
"host": "prd-foo-api-access-log",
"httpMethod": "GET",
"id": "*****",
"ip": "*.*.*.*",
"protocol": "HTTP/1.1",
"requestId": "*****",
"requestTime": "01/Jan/2021:12:00:00 +0000",
"resourcePath": "/users/{userId}",
"responseLength": "26",
"service": "apigateway",
"status": 200,
"timestamp": 1635497933028,
"user": "-",
},
"host": "prd-foo-api-access-log",
"service": "apigateway",
"tags":
[
"forwardername:datadog-forwarderstack-*****-forwarder-*****",
"source:apigateway",
"sourcecategory:aws",
"forwarder_memorysize:1024",
"forwarder_version:3.39.0",
],
"timestamp": "2021-01-01T12:00:00.000Z",
},
"id": "*****",
}
これに対して、以下のようなカテゴリパーサーのルールを定義する。各Lambdaのaws.invoked_function_arn属性のARNに応じて、service属性にサービス値 (foo-apigateway、bar-apigateway、baz-apigateway) を付与する。この属性を使用する理由は、様々なAWSリソースの構造化ログが持っているためである (owner属性でも良い。ただし、おそらくS3からログを収集する場合はこれがない?) 。元の構造化ログにすでにservice属性があるため、この値が上書きされる。
foo-apigateway @aws.invoked_function_arn:"arn:aws:lambda:ap-northeast-1:<AWSアカウントID>:function:datadog-ForwarderStack-*****-Forwarder-*****"
bar-apigateway @aws.invoked_function_arn:"arn:aws:lambda:ap-northeast-1:<AWSアカウントID>:function:datadog-ForwarderStack-*****-Forwarder-*****"
baz-apigateway @aws.invoked_function_arn:"arn:aws:lambda:ap-northeast-1:<AWSアカウントID>:function:datadog-ForwarderStack-*****-Forwarder-*****"
これにより、構造化ログのservice属性にサービス値が割り当てられる。
補足として、service属性以外は元の構造化ログと同じため、省略している。
{
"content": {
...
"service": "foo-apigateway"
...
}
}
これに対して、サービスリマッパーのルールを定義する。
service属性のサービス値が、サービスファセットとして登録されるようにする。
ユーザーエージェントパーサー¶
▼ ユーザーエージェントパーサーとは¶
ユーザーエージェントの文字列を解析し、詳細な項目ごとに分解した構造化ログとして出力する。
▼ 例1¶
Nginxから、以下のような非構造化ログを受信する例を考える。
*.*.*.* - - [01/Sep/2021:00:00:00 +0000] "GET /healthcheck HTTP/1.1" 200 17 "-" "ELB-HealthChecker/2.0"
これに対して、以下のようなGrokパーサーのルールを定義する。
http.useragent属性にユーザーエージェント値を割り当てる。
access.common %{_client_ip} %{_ident} %{_auth} \[%{_date_access}\] "(?>%{_method} |)%{_url}(?> %{_version}|)" %{_status_code} (?>%{_bytes_written}|-)
access.combined %{access.common} (%{number:duration:scale(1000000000)} )?"%{_referer}" "%{_user_agent}"( "%{_x_forwarded_for}")?.*
error.format %{date("yyyy/MM/dd HH:mm:ss"):date_access} \[%{word:level}\] %{data:error.message}(, %{data::keyvalue(": ",",")})?
これにより、構造化ログの各属性に値が割り当てられる。
{
"date_access": 12345,
"http":
{
"method": "GET",
"referer": "-",
"status_code": 200,
"url": "/healthcheck",
"useragent": "ELB-HealthChecker/2.0",
"version": "1.1",
},
"network": {"bytes_written": 17, "client": {"ip": "*.*.*.*"}},
}
これに対して、ユーザーエージェントパーサーのルールを定義する。
http.useragent属性の値を分解し、useragent_details属性に振り分けるようにする。
これにより、構造化ログの各属性に値が割り当てられる。
{
...
"useragent_details": {
"browser": {
"family": "Chrome"
},
"device": {
"category": "Other",
"family": "Other"
},
"os": {
"family": "Linux"
}
}
...
}
ストリングビルダープロセッサー¶
▼ ストリングビルダープロセッサーとは¶
構造化ログの属性にアクセスし、ルールを基に属性値を出力し、新しい文字列を作成する。
配列値のキー名にアクセスするようにルールを定義した場合、そのキーの全ての値をカンマ区切りで出力できる。
また、配列状のオブジェクトのキー名にアクセスするようにルールを定義した場合、各オブジェクトの同キーの値をカンマ区切りで出力できる。
▼ 例1¶
ログパイプラインを経て、以下のような構造化ログが作成されているとする。
{
"date": 1609502400000,
"http":
{
"method": "GET",
"status_code": 200,
"url": "/users?paginate=10&fooId=1",
"url_details":
{"path": "/users", "queryString": {"fooId": 1, "paginate": 10}},
},
"network": {"client": {"ip": "192.168.0.1"}},
}
これに対して、ストリングビルダープロセッサーのルールを定義する。
構造化ログのhttp.urlの値を出力して完全なURLを作成し、これをhttp.url_full属性として新しく付与する。
https://example.com%{http.url}
これにより、以下の構造化ログが得られる。
{
"date": 1609502400000,
"http": {"url_full": "https://example.com/users?paginate=10&fooId=1"},
...,
}
07-03. 設定ポリシー¶
名前¶
▼ パイプライン¶
| 規則 | 例 | 用途 |
|---|---|---|
<マイクロサービス名>-pipeline |
order-pipeline |
orderマイクロサービスのログを処理する。 |
▼ プロセッサー系¶
| 規則 | 例 | 用途 |
|---|---|---|
<プロセッサーに合わせた動詞> <属性へのアクセス> |
Categorize http.status_code |
http.status_code属性にアクセスし、値に応じてカテゴリプロセッサーを実行する。 |
▼ パーサー系¶
| 規則 | パーサーの種類 | 例 | 用途 |
|---|---|---|---|
Parse <属性へのアクセス名> |
Grokパーサー以外 | Parse http.url |
http.url属性にアクセスし、パーサーを実行する。 |
Parse <タグ名> <ログの種類> |
Grokパーサー | ・Parse php-fpm access logs・ Parse php-fpm error logs |
指定したタグの付いたログに対してGrokパーサーを実行する。 |
▼ リマッパー系¶
| 規則 | 例 | 用途 |
|---|---|---|
Remap <属性へのアクセス名> |
Remap http.status_category |
http.status_category属性にアクセスし、属性のリマップを実行する。 |
粒度¶
▼ service流入パターン¶
serviceタグで流入させたログをsourceタグで振り分ける場合を示す。
log-pipeline
├── foo-pipeline # service:foo でログ流入
| ├── 共通処理
│ ├── laravel-pipeline # source:laravel のログを処理
│ ├── php-fpm-pipeline # source:laravel のログのうち、PHP-FPMのもののみを処理
| └── 共通処理
│
├── bar-pipeline
| └── gin-pipeline # source:gin のログを処理
|
...
▼ source流入パターン¶
sourceタグで流入させたログをserviceタグで振り分ける場合を示す。
log-pipeline
├── aws-waf-pipeline # source:waf でログ流入
| ├── 共通処理
│ ├── foo-pipeline # service:foo のログを処理
│ ├── bar-pipeline # service:bar のログを処理
| └── 共通処理
│
...
データ型¶
▼ リマッパーによる定義¶
リマッパーでは、Force attribute typeの項目で、再配置する属性のデータ型を指定できる。
ログコンソールでフィルタリングする時に、ファセットで設定したデータ型と実際のデータ型が一致しないとフィルタリングできない。
そのため、リマッパーを使用する時は明示的にデータ型を設定する。
パーサーに関して¶
▼ Grokパーサーのルールにコメント¶
ベストプラクティス通り、Grokパーサーではコメントでログサンプルを示すようにする。
ログの種類が1つしかない場合は任意であるが、ログの種類が複数あり、それぞれを解析するルールも複数ある場合は必ずコメントする。
# [2022-01-20 19:02:48] production.INFO: ...
autoFilledRule1 ...
# [2022-01-21 20:17:26] production.INFO: ...
autoFilledRule2 ...
# [2021-09-01 00:00:00] staging.INFO: ...
autoFilledRule3 ...
▼ ヘルパールールを使用する¶
ヘルパールールを使用すると、正規表現ルールを共通化し、複数のルールで使いまわせる。
07-04. パイプラインの前後処理¶
事前処理¶
▼ プリプロセッサー¶
予約済み属性 (message、timestamp、status、host、service) に基づいて、ログを構造化する。
例えば、受信したログが非構造化ログの場合、これはDatadogの基底構造化ログのmessage属性に割り当てられる。
一方で、構造化ログであった場合はmessage属性は使用されない。
事後処理¶
▼ 標準属性¶
標準属性を新しく付与する。
▼ Live Tail¶
ログパイプライン処理後のログをリアルタイムで確認できる。
▼ ログのメトリクス¶
パイプラインで処理を終えたログに関して、属性/タグに基づくメトリクスを作成する。
メトリクスを作成しておくと、ログのレポートとして使用できる。
▼ インデックス¶
パイプラインで処理を終えたログをグループ化し、ログの破棄ルールや保管期間をグループごとに定義できる。
インデックスを使用すれば、Datadogのログ保管のネックになる保管料金を抑えられる。
▼ アーカイブ¶
▼ セキュリティルール¶
08. ログエクスプローラ¶
ログクエリ¶
▼ ログクエリとは¶
構造化ログの属性名と値を基に、ログを絞り込める。
▼ オートコンプリート¶
入力欄右のアイコンで切り替える。
検索条件として属性名と値を補完入力できる。
オートコンプリートをの使用時は、小文字で入力した属性名の頭文字が画面上で大文字に変換される。
*例*
『service:foo』をオートコンプリートで入力する。

▼ 非オートコンプリート¶
入力欄右のアイコンで切り替える。
検索条件として属性名と値をそのまま入力する。
*例*
『service:foo』を非オートコンプリートで入力する。

▼ 文法¶
| ユースケース | 例 |
|---|---|
| 一致するものを抽出する。 | service:foo |
| 一致するものを除外する。 | -service:foo |
ファセット¶
▼ ファセットとは¶
属性/タグの値を基に、ログをグルーピングしたもの。
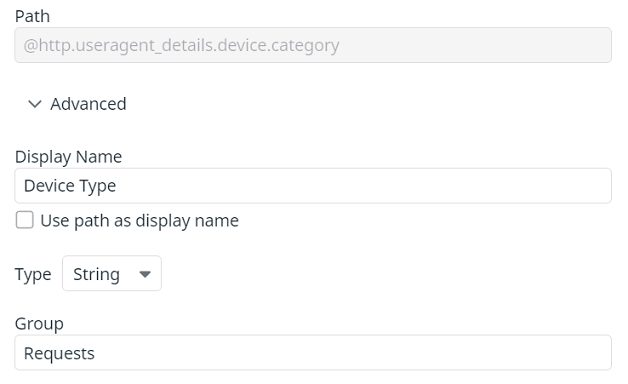
▼ 属性のファセット化¶
Pathの値に属性までのアクセスを『@』から入力すると、ログの属性がファセットの値に登録される。
▼ タグのファセット化¶
Pathの値にタグ名をそのまま入力すると、タグがファセットの値に登録される。