metrics-server@ハードウェアリソース管理系¶
はじめに¶
本サイトにつきまして、以下をご認識のほど宜しくお願いいたします。
01. metrics-serverの仕組み¶
アーキテクチャ¶
metrics-server は、拡張 API サーバー、ローカルストレージ、スクレイパー、といったコンポーネントから構成される。
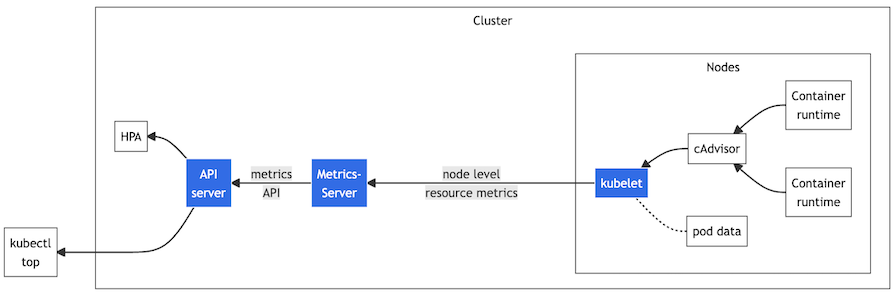
Pod と Node のメトリクスの元になるデータポイントを収集し、kubectl top コマンドでこれを取得できる。
また必須ではないが、HorizontalPodAutoscaler と VerticalPodAutoscaler を作成すれば、Pod の自動水平スケーリングや自動垂直スケーリングを実行できる。
Kubernetes の Node と Pod (それ以外の Kubernetes リソースは対象外) のメトリクスの元になるデータポイントを収集しつつ、収集したデータポイントを拡張 API サーバーで公開する。
似た名前のツールに kube-metrics-server があるが、こちらは Exporter として稼働する。
(1)-
クライアント (
kubectl topコマンド実行者、HorizontalPodAutoscaler、VerticalPodAutoscaler) が metrics-server の API からメトリクスを参照しようとする。 (2)-
クライアントは、kube-apiserver にリクエストが送信する。
(3)-
kube-apiserver は、metrics-server のプロキシ (APIService) にリクストをフォワーディングする。
(4)-
APIService は、クライアントにメトリクスを返信する。
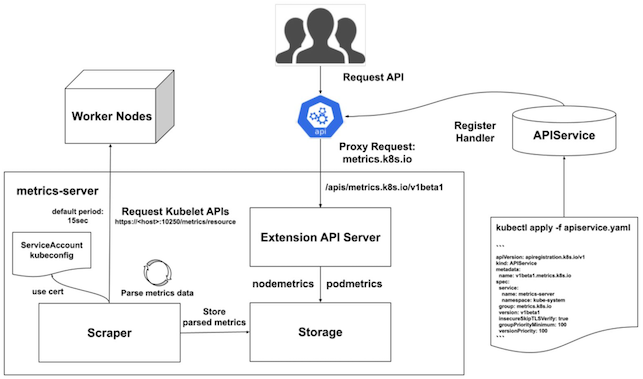
拡張APIサーバー¶
▼ 拡張APIサーバーとは¶
拡張 API サーバーは、Service と APIService を介して、クライアント (kubectl top コマンド実行者、HorizontalPodAutoscaler、VerticalPodAutoscaler) からのリクエストを受信し、メトリクスの元になるデータポイントを含むレスポンスを返信する。
データポイントはローカルストレージに保管している。
ローカルストレージ¶
ローカルストレージは、クライアント (kubectl top コマンド実行者、HorizontalPodAutoscaler、VerticalPodAutoscaler) 宛先となっている Pod や Node のメトリクスの元になるデータポイントを保管する。
スクレイパー¶
スクレイパーは、kubelet のデーモンから Pod や Node からメトリクスの元になるデータポイントを定期的に収集し、ローカルストレージに保管する。
kubelet のデーモンはデータポイント収集用エンドポイント (例:/metrics/resource、/stats など) を持ち、これがスクレイパーの収集対象になる。
そのため、Pod や Node にデータポイント収集用エンドポイント (例:/metrics) を設ける必要はない。
01-02. マニフェスト¶
Deployment配下のPod¶
記入中...
apiVersion: apps/v1
kind: Pod
metadata:
name: metrics-server
namespace: kube-system
spec:
containers:
# コンテナの起動に時間がかかるので待機する
- name: metrics-server
image: registry.k8s.io/metrics-server/metrics-server:v0.6.3
imagePullPolicy: IfNotPresent
args:
- --cert-dir=/tmp
- --secure-port=4443
- --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname
- --kubelet-use-node-status-port
# データポイントの収集間隔を設定する。間隔が短すぎると、kube-apiserverに負荷がかかる
# https://github.com/kubernetes-sigs/metrics-server/blob/master/FAQ.md#how-often-metrics-are-scraped
- --metric-resolution=15s
# Minikubeでは、kubelet-insecure-tlsオプションを有効化する
# @see https://speakerdeck.com/y_sera15/metrics-serverwosekiyuanatlsdedepuroisitemita?slide=5
- --kubelet-insecure-tls
resources:
requests:
cpu: 100m
memory: 200Mi
ports:
- name: https
containerPort: 4443
protocol: TCP
readinessProbe:
httpGet:
path: /readyz
port: https
scheme: HTTPS
periodSeconds: 10
failureThreshold: 3
initialDelaySeconds: 20
livenessProbe:
httpGet:
path: /livez
port: https
scheme: HTTPS
periodSeconds: 10
failureThreshold: 3
# metrics-serverの準備完了を待たずにReadinessProbeヘルスチェックを実施しないように、初回のヘルスチェックを開始するまでの待機時間を延長する
# https://github.com/kubernetes-sigs/metrics-server/issues/1056#issuecomment-1288198994
initialDelaySeconds: 80
securityContext:
readOnlyRootFilesystem: "true"
runAsNonRoot: "true"
runAsUser: 1000
volumeMounts:
- mountPath: /tmp
name: tmp-dir
priorityClassName: system-cluster-critical
serviceAccountName: metrics-server
volumes:
- emptyDir: {}
name: tmp-dir
APIService¶
記入中...
apiVersion: apiregistration.k8s.io/v1
kind: APIService
metadata:
labels:
k8s-app: metrics-server
name: v1beta1.metrics.k8s.io
spec:
group: metrics.k8s.io
groupPriorityMinimum: 100
insecureSkipTLSVerify: "true"
service:
name: metrics-server
namespace: kube-system
version: v1beta1
versionPriority: 100
02. kubectl top コマンド¶
node¶
▼ nodeとは¶
Node のハードウェアリソースの消費量を取得する。
# Nodeのメトリクスを取得
$ kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
foo-node 174m 2% 8604Mi 30%
bar-node 2917m 82% 16455Mi 57%
baz-node 352m 4% 9430Mi 33%
また、クライアントが HorizontalPodAutoscaler や VerticalPodAutoscaler の場合は、kube-apiserver を介して拡張 API サーバーから Node や Pod のメトリクスを取得する。そして、Pod をオートスケーリングする。
▼ デバッグ¶
metrics-server が正常に動作していない場合、Node のハードウェアリソースの消費量が <unknown> になる。
$ kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
master-1 192m 2% 10874Mi 68%
node-1 582m 7% 9792Mi 61%
node-2 <unknown> <unknown> <unknown> <unknown>
pod¶
▼ podとは¶
Pod のハードウェアリソースの消費量を取得する。
$ kubectl top pod -n foo-namespace
NAME CPU(cores) MEMORY(bytes)
foo-pod 5m 104Mi
▼ --containers¶
Pod のコンテナに関して、ハードウェアリソースの消費量を取得する。
コンテナの Kubernetes リソース使用量を足した値が、Pod 内で使用するリソース消費量になる。
$ kubectl top pod --container -n foo-namespace
POD NAME CPU(cores) MEMORY(bytes)
foo-pod foo-container 1m 19Mi
foo-pod istio-proxy 5m 85Mi
▼ デバッグ¶
metrics-server が正常に動作していない場合、Pod のハードウェアリソースの消費量が <unknown> になる。
$ kubectl top pod
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
foo-pod <unknown> <unknown> <unknown> <unknown>
03. Podの自動水平スケーリング/自動垂直スケーリング¶
HorizontalPodAutoscaler¶
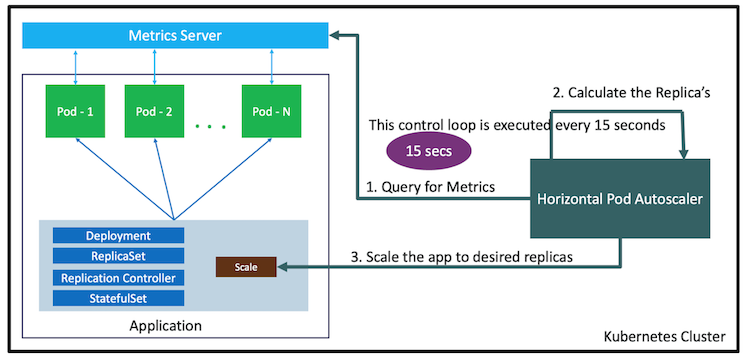
▼ HorizontalPodAutoscalerとは¶
Deployment、StatefulSet、ReplicaSet の単位で Pod の自動水平スケーリングを実行する。
metrics-server から取得した Pod に関するメトリクス値とターゲット値を比較し、kubelet を介して、Pod をスケールアウト/スケールインさせる。
設定されたターゲットを超過しているようであればスケールアウトし、反対に下回っていればスケールインする。
HorizontalPodAutoscaler を使用するためには、metrics-server も別途インストールしておく必要がある。
▼ 最大Pod数の求め方¶
オートスケーリング時の現在の Pod 数は、次の計算式で算出される。
算出結果に基づいて、スケールアウト/スケールインが実行される。
(必要な最大Pod数)
= (現在のPod数) x (現在のPodのCPU平均使用率) ÷ (現在のPodのCPU使用率のターゲット値)
例えば、『現在のPod数 = 5』『現在のPodのCPU平均使用率 = 90』『現在のPodのCPU使用率のターゲット値 = 70』だとすると、『必要な最大Pod数 = 7』となる。
算出結果と比較して、現在の Pod 数不足しているため、スケールアウトが実行される。
▼ デバッグ¶
Deployment 配下の Pod で、.spec.containers[*]resources キーに要求量を設定すると、HorizontalPodAutoscaler が要求量に対する使用量 (Target 列) を取得できるようになる。
一方でこれを取得できていない場合、設定がないか、metrics-server が正常に動作していない可能性がある。
$ kubectl get hpa -A
NAMESPACE NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
foo foo-deployment Deployment/foo-deployment <unknown>/80% 1 1 1 391d
bar bar-deployment Deployment/bar-deployment <unknown>/80% 1 1 1 391d
baz baz-deployment Deployment/baz-deployment <unknown>/80% 1 1 1 391d
▼ レプリカ数との衝突¶
最初、Deployment の spec.replicas キーに合わせて Pod が作成され、次に HorizontalPodAutoscaler の .spec.minReplicas キーが優先される。
この挙動は混乱につながるため、HorizontalPodAutoscaler を使用する場合、Deployment の spec.replicas キーの設定を削除しておくことが推奨である。
▼ メトリクスでのPodの増減¶
メトリクス上では、既存の Pod が削除されて、新しい Pod が作成されていることを確認できる。
VerticalPodAutoscaler¶
▼ VerticalPodAutoscalerとは¶
Pod の垂直スケーリングを実行する。
▼ Podの再作成のない垂直スケーリング¶
執筆時点 (2022/12/31) の仕様では、Pod を垂直スケーリングする場合に、Pod の再作成が必要になる。
これを解決するために、いくつかの方法が提案されている。
| 方法 | 説明 |
|---|---|
| マニフェストの新しい設定値の追加 | マニフェストに、垂直スケーリング時のルールに関する設定値 (例:.spec.containers[*].resources[*].resizePolicy キー) を追加する。 |
| eBPFによるインプレース変更 | ハードウェアリソースの不足が検知されたときに、eBPFを使用して、Podのマニフェストを変更するJSONPatch処理をフックする。 |