descheduler@ハードウェアリソース管理系¶
はじめに¶
本サイトにつきまして、以下をご認識のほど宜しくお願いいたします。
01. descheduler¶
アーキテクチャ¶
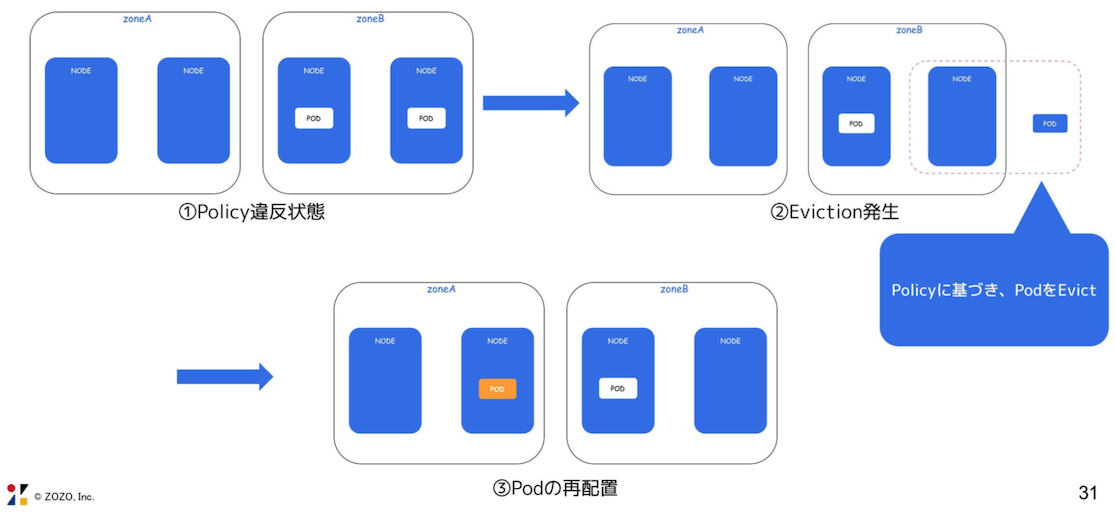
descheduler は、ポリシーに応じて不適切な Node から Pod を退避させる。
その後、kube-scheduler がより適切な Node に Pod を再スケジューリングさせる。
$ kubectl get events -n foo
# deschedulerがPodを退避させる
35m Normal LowNodeUtilization pod/foo-5c844554c5-6nk2r pod evicted from ip-*-*-*-*.ap-northeast-1.compute.internal node by sigs.k8s.io/descheduler
35m Normal Killing pod/foo-5c844554c5-6nk2r Stopping container foo
# kube-schedulerがPodを再スケジューリングさせる
35m Normal Scheduled pod/foo-5c844554c5-vgdjl Successfully assigned foo-5c844554c5-vgdjl to ip-*-*-*-*.ap-northeast-1.compute.internal
35m Normal Pulled pod/foo-5c844554c5-vgdjl Container image "public.ecr.aws/docker/library/foo:*.*.*" already present on machine
35m Normal Created pod/foo-5c844554c5-vgdjl Created container foo
35m Normal Started pod/foo-5c844554c5-vgdjl Started container foo
35m Normal SuccessfulCreate replicaset/foo-5c844554c5 Created pod: foo-5c844554c5-vgdjl
kube-schedulerだけでは足りない理由¶
Node のハードウェアリソースの消費量が動的に高まった場合、kube-scheduler は不適切な Node から Pod を退避し、別の Node へ再スケジューリングできない。
他の Node で障害が起こり、別の Node に Pod が退避した場合、その後 Node が回復したとしても、Pod が元の Node に戻ることはない。
kubectl rollout restart コマンドを実行してもよいが、descheduler を使用すればこれを自動化できる。
descheduler を CronJob として定期的に起動させ、Pod を自動的に退避させる。
このことからもわかるように、障害回復後すぐに descheduler が起動するわけではなく、CronJob の実行を待つ必要がある。
01-02¶
マニフェストの種類¶
descheduler は、Job (descheduler) 、ConfigMap などのマニフェストから構成されている。
Job¶
ここでは、CronJob 配下で定義したとする。
Descheduler の実行頻度が高すぎると可用性が低下するため、システムの特徴に合わせて実行頻度を設定する。
例えば、深夜帯に利用者が少なくなるのであれば、毎日深夜に 1 回だけ実行する。
apiVersion: batch/v1
kind: CronJob
metadata:
labels:
app.kubernetes.io/name: descheduler
name: descheduler
namespace: descheduler
spec:
# 毎日 00:00 (JST) にdeschedulerを実行する
# Amazon EKSはUTCでタイムゾーンを設定しているため、9時間分ずらす必要がある
schedule: "0 15 * * *"
# その他の例
# 12:00 と 24:00 (JST) にdeschedulerを実行する
# schedule: "0 3,15 * * *"
concurrencyPolicy: Forbid
successfulJobsHistoryLimit: 1
failedJobsHistoryLimit: 1
jobTemplate:
spec:
template:
metadata:
annotations:
# ConfigMapの変更に応じて、Jobを更新する。
checksum/configmap: *****
labels:
app.kubernetes.io/name: descheduler
name: descheduler
spec:
containers:
- name: descheduler
image: registry.k8s.io/descheduler/descheduler:latest
command:
- /bin/descheduler
args:
- '--policy-config-file'
- /policy-dir/policy.yaml
- '--v'
- '3'
volumeMounts:
- mountPath: /policy-dir
name: policy-volume
# ポリシーの設定ファイルを読み込む
volumes:
- configMap:
name: descheduler
name: policy-volume
ConfigMap¶
DeschedulerPolicy のマニフェストを設定する。
apiVersion: v1
kind: ConfigMap
metadata:
labels:
app.kubernetes.io/name: descheduler
name: descheduler
namespace: descheduler
data:
policy.yaml: |
apiVersion: "descheduler/v1alpha1"
kind: "DeschedulerPolicy"
evictLocalStoragePods: "true"
strategies:
HighNodeUtilization:
enabled: "true"
LowNodeUtilization:
enabled: "true"
params:
nodeResourceUtilizationThresholds:
targetThresholds:
cpu: 50
memory: 50
pods: 50
thresholds:
cpu: 20
memory: 20
pods: 20
PodLifeTime:
enabled: "true"
RemoveDuplicates:
enabled: "true"
RemoveFailedPods:
enabled: "true"
RemovePodsHavingTooManyRestarts:
enabled: "true"
RemovePodsViolatingInterPodAntiAffinity:
enabled: "true"
RemovePodsViolatingNodeAffinity:
enabled: "true"
params:
nodeAffinityType:
- requiredDuringSchedulingIgnoredDuringExecution
RemovePodsViolatingNodeTaints:
enabled: "true"
RemovePodsViolatingTopologySpreadConstraint:
enabled: "true"
02. DeschedulerPolicy¶
DeschedulerPolicyとは¶
退避の対象とする Pod の選定ルールを設定する。
DeschedulerPolicy¶
▼ LowNodeUtilization¶
Node のハードウェアリソース使用量 (例:CPU、メモリなど) や Pod 数が指定したターゲット閾値 (targetThresholds) を超過した場合に、この Node 上の Pod を退避させる。
さらに、kube-scheduler を使用して、使用量が閾値 (thresholds) を超過していない Node に Pod をスケジューリングさせる。
注意点として、ターゲット閾値と閾値が近いと、Node 間で Pod が退避 (descheduler) と再スケジューリング (kube-scheduler) を繰り返す状態になってしまう。
Node のハードウェアリソース使用量と Pod 数がターゲット閾値と閾値の間にある場合、つまりターゲット閾値を超過する Node が存在せず、閾値よりも低い Node が存在しない場合、descheduler は何もしない。
apiVersion: descheduler/v1alpha1
kind: DeschedulerPolicy
strategies:
LowNodeUtilization:
enabled: "true"
params:
nodeResourceUtilizationThresholds:
# ターゲット閾値 (この値を超過したNodeからPodを退避させる)
targetThresholds:
cpu: 70
memory: 70
pods: 70
# 閾値 (kube-schedulerを使用して、この値を超過していないNodeにPodを再スケジューリングさせる)
thresholds:
cpu: 20
memory: 20
pods: 20
▼ RemoveDuplicates¶
Workload (例:Deployment、DaemonSet、StatefulSet、Job など) の配下にある Pod が同じ Node 上でスケーリングされている場合に、この Pod を Node から退避させる。
該当する Node がない場合、退避させない。
apiVersion: descheduler/v1alpha1
kind: DeschedulerPolicy
strategies:
RemoveDuplicates:
enabled: "true"
▼ RemoveFailed¶
Failed ステータスな Pod は、そのままでは削除されない。
そのため、Failed ステータスな Pod がある場合は、この Pod を Node から削除する。
apiVersion: descheduler/v1alpha1
kind: DeschedulerPolicy
strategies:
RemoveFailedPods:
enabled: "true"
params:
failedPods:
minPodLifetimeSeconds: 3600
# Failedステータスになった理由でフィルタリングする
reasons:
- NodeAffinity
includingInitContainers: "true"
▼ RemovePodsHavingTooManyRestarts¶
再起動を繰り返している Pod がある場合に、この Pod を Node から退避させる。
再起動の回数の閾値を設定できる。
apiVersion: descheduler/v1alpha1
kind: DeschedulerPolicy
strategies:
RemovePodsHavingTooManyRestarts:
enabled: "true"
params:
podsHavingTooManyRestarts:
podRestartThreshold: 100
includingInitContainers: "true"
▼ RemovePodsViolatingNodeAffinity¶
.spec.nodeAffinity キーの設定に違反している Pod がある場合に、この Pod を Node から退避させる。
apiVersion: descheduler/v1alpha1
kind: DeschedulerPolicy
strategies:
RemovePodsViolatingNodeAffinity:
enabled: "true"
▼ RemovePodsViolatingInterPodAntiAffinity¶
.spec.affinity.podAffinity キーの設定に違反している Pod がある場合に、この Pod を Node から退避させる。
apiVersion: descheduler/v1alpha1
kind: DeschedulerPolicy
strategies:
RemovePodsViolatingInterPodAntiAffinity:
enabled: "true"
▼ RemovePodsViolatingNodeTaints¶
taints の設定に違反している Pod がある場合に、この Pod を Node から退避させる。
▼ RemovePodsViolatingTopologySpreadConstraint¶
TopologySpreadConstraints の設定に違反している Pod がある場合に、この Pod を Node から退避させる。
apiVersion: descheduler/v1alpha1
kind: DeschedulerPolicy
strategies:
RemovePodsViolatingTopologySpreadConstraint:
enabled: "true"
params:
podsHavingTooManyRestarts:
podRestartThreshold: 100
includingInitContainers: "true"
グローバルオプション¶
▼ nodeFit¶
Pod を退避させる前に、他の Node が Pod を再スケジューリングできる条件 (nodeSelector、tolerations、nodeAffinity など) であるかを検証する。