Kubernetesリソース@Kubernetes¶
はじめに¶
本サイトにつきまして、以下をご認識のほど宜しくお願いいたします。
01. Kubernetesリソースとオブジェクト¶
Kubernetesリソース¶
Kubernetes 上でアプリケーションを稼働させる概念のこと。
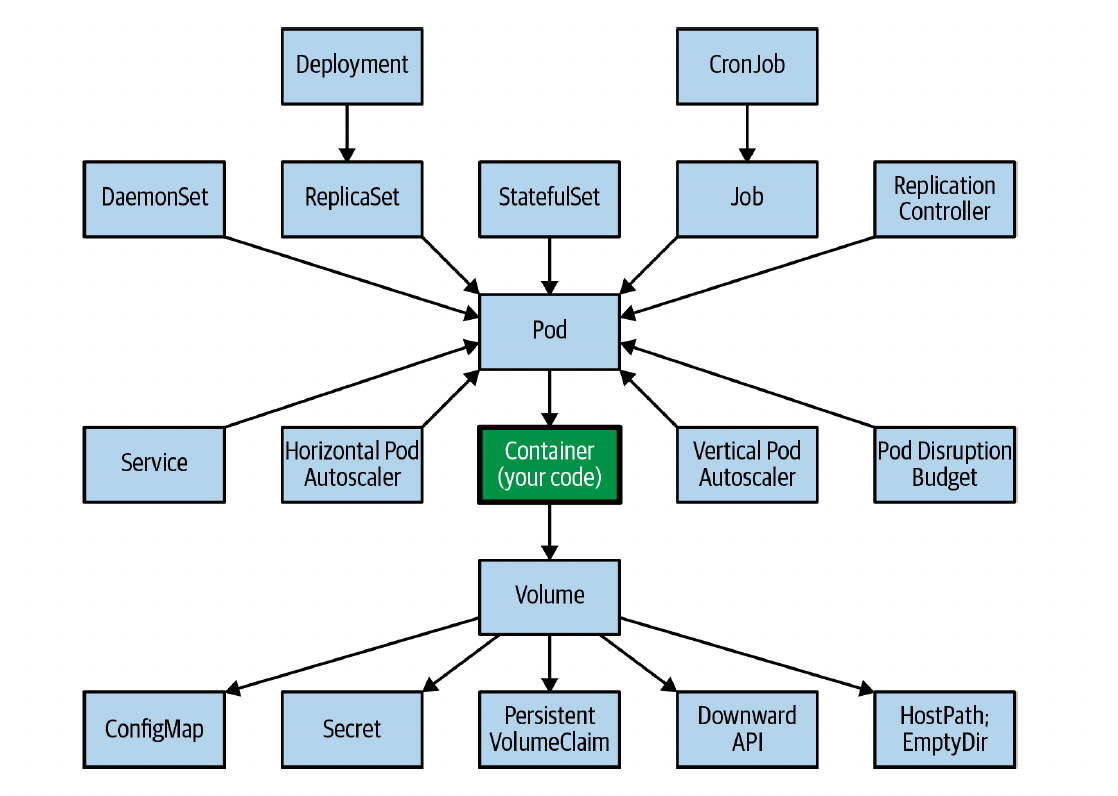
Kubernetesオブジェクト¶
マニフェストによって量産された Kubernetes リソースのインスタンスのこと。
スコープ¶
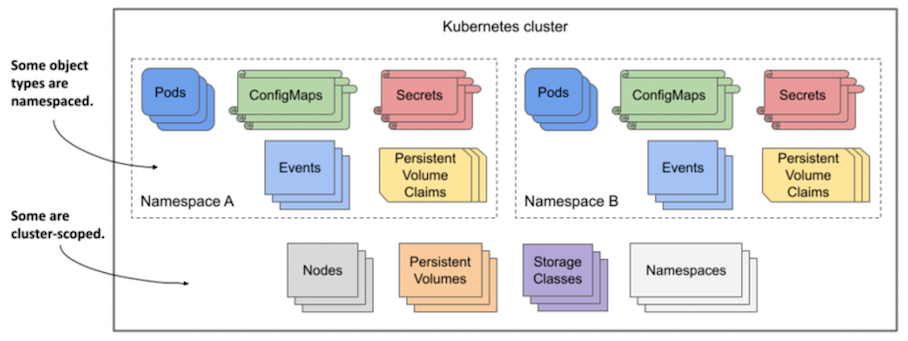
所属する Namespace 内のみにリクエストを送信できる Namespaced スコープな Kubernetes リソースと、Cluster 全体にリクエストを送信できる Cluster スコープな Kubernetes リソースがある。
02. Workload系リソース¶
Workload系リソースとは¶
コンテナの実行に関する機能を提供する。
DaemonSet¶
▼ DaemonSetとは¶
Node 上の Pod の個数を維持管理する。
Pod の負荷に合わせて Pod の自動水平スケーリングを実行しない (HorizontalPodAutoscaler が必要である) 。
ただし ReplicaSet とは異なり、Node 内で Pod を 1 つだけ維持管理する。
Node で 1 つだけ稼働させる必要のあるプロセス (例:kube-proxy、CNI、FluentBit、datadog エージェント、cAdvisor エージェント、Prometheus の一部の Exporter など) のために使用される。
こういったプロセスが稼働するコンテナは、Node 内のすべてのコンテナからデータを収集し、可観測性のためのデータセットを整備する。
▼ Pod数の固定¶
DaemonSet は、Node 内で Pod を 1 つだけ維持管理する。
そのため、例えば Cluster ネットワーク内に複数の Node が存在していて、いずれかの Node が停止したとしても、稼働中の Node 内の Pod を増やすことはない。
▼ DaemonSet配下のPodへの通信¶
- NodePort Service
- ClusterIP Service
- Pod での hostPort
- など...
Deployment¶
▼ Deploymentとは¶
ReplicaSet を操作し、Cluster ネットワーク内の Pod のレプリカ数を維持管理する。
Pod の負荷に合わせて Pod の自動水平スケーリングを実行しない (HorizontalPodAutoscaler が必要である) 。
ただし StatefulSet とは異なり、ストレートレス (例:アプリ) なコンテナを含む Pod を冗長化することに適する。
▼ ReplicaSetの置き換えが起こる条件¶
Deployment では、以下の設定値の変更で、ReplicaSet の置き換えが起こる。
| 条件 | 説明 |
|---|---|
.spec.replicas キーの変更 |
レプリカ数 (.spec.replicas キー) の変更の場合は、Deploymentは既存のReplicaSetをそのままにし、Podのレプリカ数のみを変更する。 |
.spec.template キー配下の任意の変更 |
PodTemplate (.spec.template キー) を変更した場合、Deploymentは新しいReplicaSetを作成し、これを古いReplicaSetと置き換える。 |
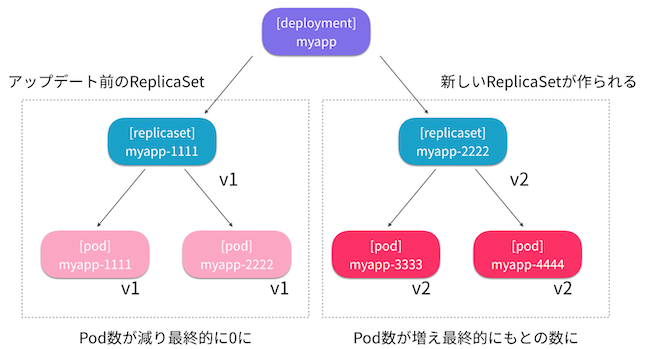
▼ Podのレプリカ数の維持¶
Deployment は、Cluster 内の Pod のレプリカ数を指定された数だけ維持する。
そのため、例えば Cluster 内に複数の Node が存在していて、いずれかの Node が停止した場合、稼働中の Node 内でレプリカ数を維持するように Pod 数を増やす。
Job¶
▼ Jobとは¶
単発的なバッチ処理を定義したい場合、Job を使用する。
もう一度実行したい場合は、Job を削除する必要がある。
複数の Pod を作成 (SuccessfulCreate) し、指定された数の Pod を正常に削除 (SuccessfulDelete) する。
デフォルトでは、ログの確認のために Pod は削除されず、Job が削除されて初めて Pod も削除される。
.spec.ttlSecondsAfterFinished キーを使用すると、Pod のみを自動削除できるようになる。
定期的に実行する場合、CronJob のテンプレートとして定義する。
- https://kubernetes.io/docs/concepts/workloads/controllers/job/
- https://qiita.com/MahoTakara/items/82853097a1911671a704
- https://dev.appswingby.com/kubernetes/kubernetes-%E3%81%A7-job%E3%82%92%E8%87%AA%E5%8B%95%E5%89%8A%E9%99%A4%E3%81%99%E3%82%8Bttlsecondsafterfinished%E3%81%8Cv1-21%E3%81%A7beta%E3%81%AB%E3%81%AA%E3%81%A3%E3%81%A6%E3%81%84%E3%81%9F%E4%BB%B6/
- https://faun.pub/batch-and-cron-jobs-in-kubernetes-cbd29c35fd8
▼ DBマイグレーション¶
Job を使用して、DB にマイグレーションを実行する。
GitOps ツール (例:ArgoCD など) によっては、アノテーションを使用して Apply 前に Job をフックさせられる。
ArgoCD の場合、DBマイグレーション ---> ArgoCD Sync開始 ---> アプリ起動 ---> ArgoCD Sync完了 という流れになる。
apiVersion: batch/v1
kind: Job
metadata:
namespace: foo
name: foo-migration-job
spec:
backoffLimit: 0
template:
spec:
containers:
- name: foo-app
image: foo-app:1.0.0
command: ["<マイグレーションを実行するためのコマンド>"]
envFrom:
- secretRef:
# DBの接続情報 (ホスト、ユーザー名、パスワード) はSecretに設定しておく。
name: foo-secret
restartPolicy: Never
ただし、アプリケーションの起動直前に DB マイグレーションを実行してしまってもよい。
その場合、ArgoCD Sync開始 ---> DBマイグレーション ---> アプリ起動 ---> Sync完了 という流れになる。
FROM node:22.11.0-bullseye-slim as base
...
# Nodeアプリケーションの起動直前にDBマイグレーションを実行してしまう
ENTRYPOINT ["npx prisma migrate deploy", "npm run start"]
もし手動でマイグレーションを実行する運用であれば、kubectl exec コマンドで接続した後に、マイグレーションコマンドを実行する。
$ kubectl exec -it <Pod名> -- bash
/usr/local/src/foo/node_modules/.bin/prisma migrate deploy
CronJob¶
▼ CronJobとは¶
定期的なバッチ処理を定義したい場合、CronJob を使用する。
CronJob 配下の Job は、決まった時間にならないと実行されない。
任意の時間に実行するためには、CronJob を指定し、これの配下で一時的に Job を作成する。
$ kubectl create job test-job --from=cronjob/foo-cron-job -n foo
ただし、動作確認後は CronJob に Job を作らせたいので、その Job は削除する。
$ kubectl delete job test-job -n foo
Node¶
▼ Nodeとは¶
Kubernetes リソースを配置するサーバーのこと。
▼ ライフサイクルフェーズ¶
kubelet は、Node のライフサイクルフェーズを設定する。
| フェーズ名 | 説明 |
|---|---|
| Ready | NodeがPodをスケジューリング可能な状態であることを表す。 |
| NotReady | NodeがPodをスケジューリング不可能な状態であることを表す。 |
▼ イベント¶
| イベント名 | 説明 |
|---|---|
| NodeHasSufficientMemory | |
| NodeHasSufficientPID | |
| NodeNotReady | |
| NodeReady | |
| Starting | |
| SystemOOM | Podの要求するメモリ量が多すぎて、Nodeのメモリ不足が起こったことを表す。Podのメモリで上限 (limits) = 下限 (requests) のように設定する (Guaranteed QoS) と、SystemOOMを避けられる。 |
Pod¶
▼ Podとは¶
コンテナの最小グループ単位のこと。
Pod を単位として、コンテナ起動/停止や水平スケールアウト/スケールインを実行する。
*例*
PHP-FPM コンテナと Nginx コンテナを稼働させる場合、これら同じ Pod 内に配置する。
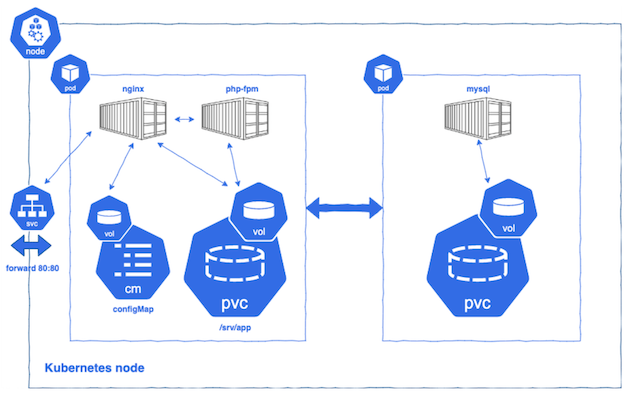
▼ 例外的なコントロールプレーンNode上のPod¶
脆弱性の観点で、デフォルトではコントロールプレーン Node に Pod はスケジューリングされない。
これは、コントロールプレーン Node には Taint (node-role.kubernetes.io/master:NoSchedule) が設定されているためである。
一方で、Node にはこれがないため、Pod をスケジューリングさせられる。
# コントロールプレーンNodeの場合
$ kubectl describe node <コントロールプレーンNode名> | grep -i taint
Taints: node-role.kubernetes.io/master:NoSchedule # スケジューリングさせないTaint
# ワーカーNodeの場合
$ kubectl describe node <ワーカーNode名> | grep -i taint
Taints: <none>
ただし、セルフマネージドなコントロールプレーン Node を採用している場合に、すべてのコントロールプレーン Node で Taint を解除すれば、Pod を起動させられる。
コントロールプレーン Node がマネージドではない環境 (オンプレミス環境、ベアメタル環境など) では、コントロールプレーン Node に DaemonSet による Pod をスケジューリングさせることがある。
$ kubectl taint node --all node-role.kubernetes.io/master:NoSchedule-
▼ Podのライフサイクルフェーズ¶
Pod は、マニフェストの .status.phase キーにライフサイクルのフェーズを持つ。
status:
phase: Running
| フェーズ名 | 説明 | 補足 |
|---|---|---|
| Completed | Pod内のすべてのコンテナが正常に終了した。 | Job配下のPodでよく見られるフェーズである。 |
| ContainerCreating | Pod内にInitContainerがない場合の理由である。コンテナイメージをプルし、コンテナを作成している。 | |
| CrashLoopBackOff | Podが、一連のフェーズ (Running フェーズ、Waiting フェーズ、Failed フェーズ) を繰り返している。 |
|
| CreateContainerError | Pod内のコンテナの作成に失敗した。 | |
| ErrImagePull | Pod内のコンテナイメージのプルに失敗した。 | |
| Error | Pod内のいずれかのコンテナが異常に終了した。 | Job配下のPodの場合はErrorになっても、次のPodが作成される。Jobの .spec.ttlSecondsAfterFinished キーを設定していなければ、ErrorのPodがしばらく残り続けるが、もし新しいPodがCompletedになれば問題ない。 |
| Failed | Pod内のすべてのコンテナの起動が完了し、その後に異常に停止した。 | |
| ImagePullBackOff | Pod内のコンテナイメージのプルに失敗した。 | |
| OOMKilled | Podのメモリの空きサイズが足らず、コンテナが強制的に終了された。 | |
| Pending | PodがNodeにスケジューリングされたが、Pod内のすべてのコンテナの起動がまだ完了していない。 | |
| PodInitializing | Pod内にInitContainerがある場合の理由である。コンテナイメージをプルし、コンテナを作成している。 | |
| PostStartHookError | PodのPostStartフックに失敗した。 | |
| Running | Pod内のすべてのコンテナの起動が完了し、実行中である。 | コンテナの起動が完了すれば Running フェーズになるが、コンテナ内でビルトインサーバーを起動するようなアプリケーション (例:フレームワークのビルトインサーバー機能) の場合は、Running フェーズであっても Ready コンディションではないことに注意する。 |
| Succeed | Pod内のすべてのコンテナの起動が完了し、その後に正常に停止した。 | |
| Unknown | NodeとPodの間の通信に異常があり、NodeがPodから情報を取得できなかった。 |
▼ Podのコンディション¶
Pod のライフサイクルのフェーズは、.status.conditions キーにコンディション持つ。
status:
phase: Running
conditions:
- lastProbeTime: null
lastTransitionTime: "2022-12-01T18:00:06Z"
status: "True"
type: Initialized
- lastProbeTime: null
lastTransitionTime: "2022-12-01T18:00:49Z"
status: "True"
type: Ready
- lastProbeTime: null
lastTransitionTime: "2022-12-01T18:00:49Z"
status: "True"
type: ContainersReady
- lastProbeTime: null
lastTransitionTime: "2022-12-01T18:00:02Z"
status: "True"
type: PodScheduled
例えば Running フェーズであっても、Ready コンディションになっていない可能性がある。
そのため、Pod が正常であると見なすためには、『Running フェーズ』かつ『Ready コンディション』である必要がある。
| 各フェーズのコンディション名 | 説明 |
|---|---|
| PodScheduled | NodeへのPodのスケジューリングが完了した。 |
| ContainersReady | すべてのコンテナの起動が完了し、加えてコンテナ内のアプリケーションやミドルウェアの準備が完了している。 |
| Initialized | すべての init コンテナの起動が完了した。 |
| Ready | Pod全体の準備が完了した。 |
▼ Podの最後のフェーズの理由¶
Pod は、.status.reason キーに、最後のフェーズの理由を値として持つ。
status:
phase: Failed
reason: Evicted
| 理由 | 説明 |
|---|---|
| Completed | コンテナが正常に終了した。InitContainerの実行後に見られる。 |
| Evicted | Nodeのハードウェアリソース不足のため、Podが退避対象となった。Evicted が理由の場合、Failed フェーズが最後となる。 |
| Unknown | 原因が不明である。 |
▼ CrashLoopBackOffのデバッグ¶
Pod が CrashLoopBackOff になっている場合、以下を確認するとよい。
kubectl logsコマンドで、該当のコンテナのエラーログを確認する。kubectl describe nodesコマンドで、Pod をスケジューリングさせている Node を指定し、該当の Pod が CPU とメモリの要求量に異常がないかを確認する。kubectl describe podsコマンドで、該当の Pod が CrashLoopBackOff になる原因を確認する。Containers の LastState の項目で、メッセージを確認できる。これは、kubectl logsコマンドと同じ内容である。
▼ Podを安全に削除する方法¶
Pod の終了プロセスが始まると、以下の一連のプロセスも開始する。
- Workload (例:Deployment、DaemonSet、StatefulSet、Job など) が古い Pod を切り離す。
- Service と kube-proxy が古い Pod の宛先情報を削除する。
- コンテナを停止する。
これらのプロセスはそれぞれ独立して実施され、ユーザーは制御できない。
例えば、Service と kube-proxy が Pod の宛先情報を削除する前に Pod が削除してしまうと、Service から Pod への接続を途中で切断することになってしまう。
また、コンテナを停止する前に Pod を終了してしまうと、コンテナを強制的に終了することになり、ログにエラーが出力されてしまう。
そのため、Service と kube-proxy の処理後に Pod を終了できるように、ユーザーが Pod の .spec.containers[*].lifecycle.preStop キーに任意の秒数を設定し、コンテナに待機処理 (例:sleep コマンド) を実行させる必要がある。
また、コンテナの正常な終了後に Pod を終了できるように、.spec.terminationGracePeriodSeconds キーに任意の秒数を設定し、Pod の終了に伴う一連のプロセスの完了を待機する必要がある。
これらの適切な秒数は、ユーザーがそのシステムに応じて調節するしかない。
.spec.terminationGracePeriodSeconds キーを長めに設定し、.spec.containers[*].lifecycle.preStop キーの秒数も含めて、すべてが完了したうえで Pod を終了可能にする。
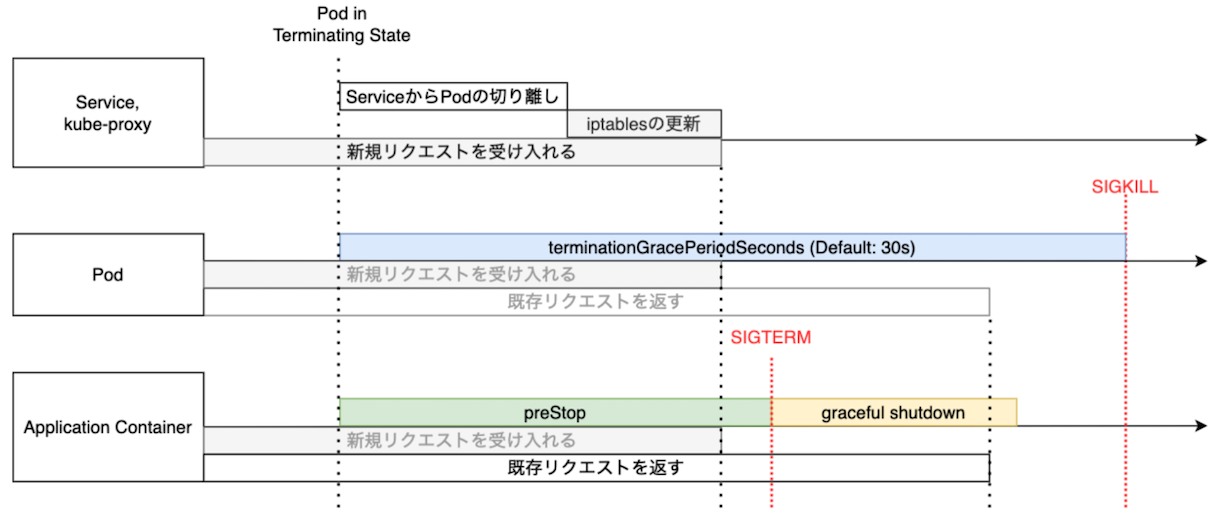
(1)-
クライアントは、
kubectlコマンドを使用して、Pod を終了するリクエストを kube-apiserver に送信する。 (2)-
Pod のマニフェストに
deletionTimestampキーが追加され、Pod がTerminatingフェーズとなり、削除プロセスを開始する。 (3)-
Pod の
.spec.terminationGracePeriodSecondsキーに応じて、Pod の終了プロセス完了の待機時間を開始する。 (4)-
最初に preStop フックが起動し、
.spec.containers[*].lifecycle.preStopキーで設定した待機処理をコンテナが実行する。 (5)-
Deployment が Pod を切り離す。また、Service と kube-proxy が Pod の宛先情報を削除する。
(6)-
.spec.containers[*].lifecycle.preStopキーによるコンテナの待機処理が終了する。 (7)-
待機処理が終了したため、kubelet は、コンテナランタイムを経由して、Pod 内のコンテナに
SIGTERMシグナルを送信する。これにより、コンテナの停止処理が開始する。
(8)-
.spec.terminationGracePeriodSecondsキーによる Pod の終了プロセス完了の待機時間が終了する。この段階でもコンテナが停止していない場合は、コンテナに
SIGKILLシグナルが送信され、コンテナを強制的に終了することになる。 (9)-
Pod が削除される。この段階で Deployment や、Service と kube-proxy の処理が完了していない場合は、接続を途中で強制的に切断することになる。
▼ ハードウェアリソースの割り当て¶
その Pod に割り当てられたハードウェアリソース (CPU、メモリ) を、Pod 内のコンテナが分け合って使用する。
| 単位 | 例 |
|---|---|
m:millicores |
1 コア = 1000 ユニット = 1000m |
Mi:mebibyte |
1Mi = 1.04858MB |
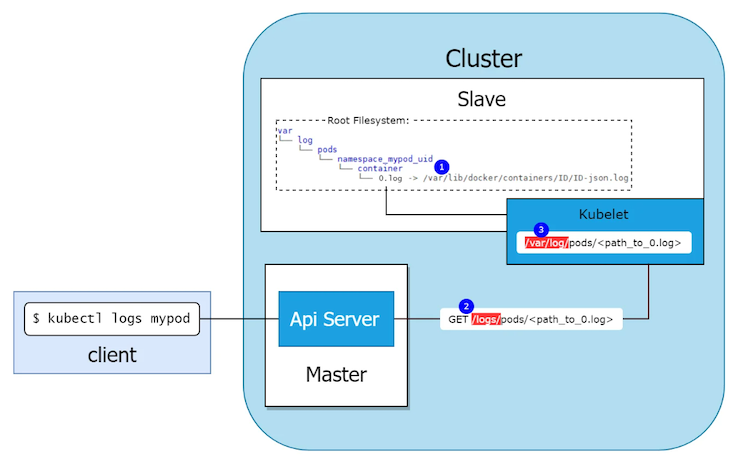
▼ クライアントがPod内のログを参照できる仕組み¶
(1)-
Node 上の kubelet とコンテナランタイムは、
/var/log/ディレクトリのlogファイルにログを書き込む。 (2)-
クライアント (特に
kubectlコマンド実行者) がkubectl logsコマンドを実行する。 (3)-
kube-apiserver が、
/logs/pods/<ログへのパス>エンドポイントにリクエストを送信する。 (4)-
kubelet はリクエストを受信し、Node の
/var/logディレクトリのlogファイルを読み込む。コンテナランタイムは、コンテナの標準出力または標準エラー出力に出力したログを
/var/log/containerディレクトリ配下に保管する。/var/log/containerディレクトリのログは、Pod全体のログを/var/log/pods/<Namespace名>_<Pod名>_<UID>/<コンテナ名>/<数字>.logファイルのシンボリックになっている。なお、削除されたPodのログは、引き続き
/var/log/podsディレクトリ配下に保管されている。
- https://www.creationline.com/lab/29281
- https://kubernetes.io/docs/concepts/cluster-administration/logging/#log-location-node
- https://tech.studyplus.co.jp/entry/2020/03/23/094119
- https://qiita.com/daitak/items/679785bd0724cb1f4971#%E3%83%AD%E3%82%B0%E3%83%87%E3%82%A3%E3%83%AC%E3%82%AF%E3%83%88%E3%83%AA%E9%9A%8E%E5%B1%A4%E3%83%95%E3%82%A1%E3%82%A4%E3%83%AB%E5%90%8D
- https://dunkshoot.hatenablog.com/entry/kubernetes_container_log
補足として、DaemonSet として稼働する Fluentd は、Node の /var/log ディレクトリを読み込むことにより、Pod 内のコンテナのログを収集する。
▼ 待ち受けるポート番号の確認¶
Pod 内のコンテナ内で netstat コマンドを実行することにより、コンテナが待ち受けるポート番号を確認できる。
$ kubectl exec foo-istiod -n istio-system -- netstat -tulpn
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 127.0.0.1:9876 0.0.0.0:* LISTEN 1/pilot-discovery
tcp6 0 0 :::15017 :::* LISTEN 1/pilot-discovery
tcp6 0 0 :::8080 :::* LISTEN 1/pilot-discovery
tcp6 0 0 :::15010 :::* LISTEN 1/pilot-discovery
tcp6 0 0 :::15012 :::* LISTEN 1/pilot-discovery
tcp6 0 0 :::15014 :::* LISTEN 1/pilot-discovery
▼ バルーンPod (OverProvisioning Pod)¶
『OverProvisioning Pod』ともいう。
Node にバルーン Pod をスケジューリングさせ、Node に常に余剰なリソース (例:CPU/メモリの容量) を確保できる。
バルーン Pod の優先度は最低にしておく。
バルーン Pod は優先度が低いため、他の Pod を Node に優先してスケジューリングできる。
apiVersion: apps/v1
kind: Deployment
metadata:
name: foo-balloon
spec:
# ゾーンが3つあるため、ゾーン間で移動するようにレプリカ数を3つにする
replicas: 3
selector:
matchLabels:
app: balloon
template:
metadata:
labels:
app: balloon
spec:
containers:
- args:
- infinity
command:
- sleep
image: ubuntu
name: ubuntu
resources:
requests:
cpu: 1000m
memory: 2048Mi
priorityClassName: foo-balloon
terminationGracePeriodSeconds: 10
# Podを同じゾーンにスケジューリングさせない
topologySpreadConstraints:
- labelSelector:
matchLabels:
app: balloon
maxSkew: 1
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: DoNotSchedule
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: foo-balloon
preemptionPolicy: Never
value: -10
description: Priority class for balloon
ReplicaSet¶
▼ ReplicaSetとは¶
Node 上の Pod 数を維持管理する。
Pod の負荷に合わせて Pod の自動水平スケーリングを実行しない (HorizontalPodAutoscaler が必要である) 。
DaemonSet とは異なり、Pod を指定した個数に維持管理できる。
ReplicaSet を直接的に操作するのではなく、Deployment 使用してこれを行うことが推奨される。
▼ PodTemplate¶
Pod の鋳型として動作する。
ReplicaSet は、PodTemplate を用いて Pod のレプリカを作成する。
StatefulSet¶
▼ StatefulSetとは¶
ReplicaSet を操作し、Pod の個数を維持管理する。
Pod の負荷に合わせて Pod を自動水平スケーリングを実行しない (HorizontalPodAutoscaler が必要である) 。
Deployment とは異なり、ストレートフルなコンテナ (例:DB コンテナ) を含む Pod を扱える。
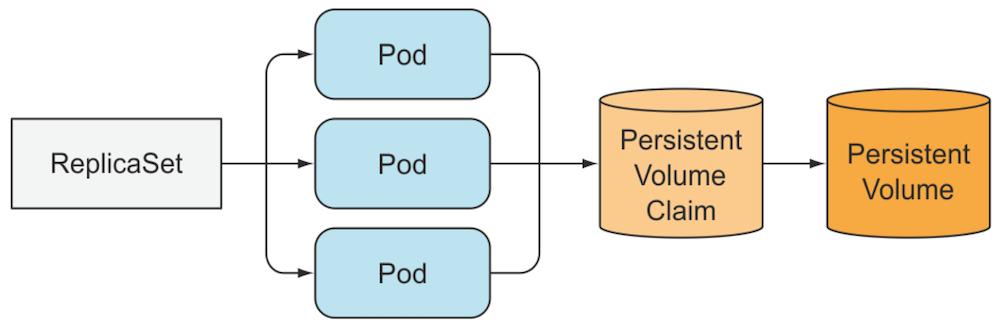
Pod が削除されても PersistentVolumeClaims は削除されないため、新しい Pod にも同じ PersistentVolume を継続的にマウントできる。
▼ ライフサイクル¶
StatefulSet は、Deployment や ReplicaSet とは異なり、同時に Pod を作成しない。
作成中の Pod が Ready 状態になってから、次の Pod を作成し始める。
そのため Deployment や ReplicaSet と比べて、すべての Pod が揃うのに時間がかかる。
DeploymentとStatefulSetとの違い¶
▼ 設定値¶
StatefulSet では、一部の設定変更が禁止されている。
The StatefulSet "foo-pod" is invalid: spec: Forbidden: updates to statefulset spec for fields other than 'replicas', 'template', 'updateStrategy' and 'minReadySeconds' are forbidden
▼ PersistentVolume¶
Deployment 配下の Pod は、すべてが同じ PersistentVolumeClaim を共有する。
そのため、Pod に紐づく PersistentVolume は同じになる。
一方で StatefulSet 配下の Pod は、別々の PersistentVolumeClaim を使用する。
そのため、Pod に紐づく PersistentVolume は別々になる。
Pod が別の Node に再スケジューリングされても、Pod に同じ PersistentVolume をマウントできる。
Pod が削除されても PersistentVolumeClaims は削除されないため、新しい Pod も同じ PersistentVolume をマウントできる。
03. ネットワーク系リソース¶
ネットワーク系リソースとは¶
Cluster 内のネットワークを制御する。
EndpointSlice¶
▼ EndpointSliceとは¶
各 Service 配下に存在する。Service でルーティング先の Pod の宛先情報を分割して管理し、Pod の増減に合わせて、Pod の宛先情報を追加/削除する。
kube-proxy によるサービス検出のために、Pod の宛先情報を提供する。
Kubernetes の v1.6 より前は Endpoints が使用されていた。
しかし、Endpoints では Pod の宛先情報を一括管理しなければならず、これを分割して管理できるように、Endpoints の代わりとして EndpointSlice が導入された。

Gateway¶
▼ Gatewayとは¶
Gateway は、L4/L7 プロトコルの通信の受信ルールを定義し、また L4/L7 ロードバランサーとして通信をルーティングする。
▼ Ingressとの違い¶
L7 プロトコルの受信ルールしか定義できない Ingress とは異なり、L4 プロトコルの受信ルールも定義できる。
また、Gateway 自体が L4/L7 ロードバランサーとしても機能する。
GatewayClass¶
▼ GatewayClassとは¶
Gateway の実体として使用するツールを指定する。
Ingress¶
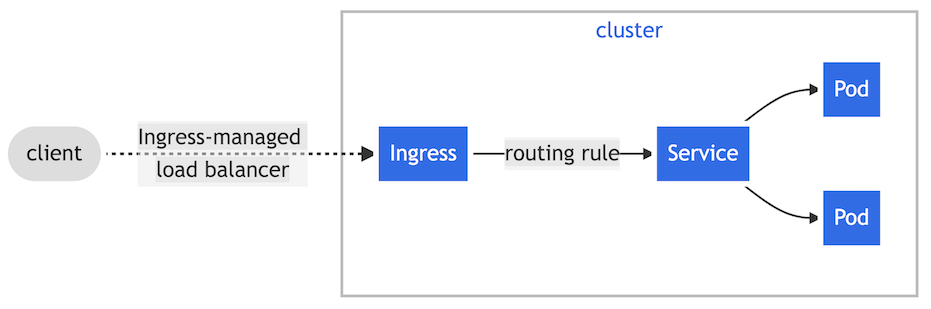
▼ Ingressとは¶
Ingress は、L7 プロトコルの通信の受信ルールを定義する。
Ingress を使用する場合、宛先の Service は、Cluster IP Service とする。
NodePort Service や LoadBalancer Service と同様に、外部からのリクエストを受信する方法の 1 つである。
- https://kubernetes.io/docs/concepts/services-networking/ingress/#what-is-ingress
- https://thinkit.co.jp/article/18263
- https://chidakiyo.hatenablog.com/entry/2018/09/10/Kubernetes_NodePort_vs_LoadBalancer_vs_Ingress%3F_When_should_I_use_what%3F_%28Kubernetes_NodePort_%E3%81%A8_LoadBalancer_%E3%81%A8_Ingress_%E3%81%AE%E3%81%A9%E3%82%8C%E3%82%92%E4%BD%BF%E3%81%86
- https://www.netone.co.jp/knowledge-center/netone-blog/20210715-01/
▼ Gatewayとの違い¶
L7 プロトコルの通信のみを処理できる。
また、Ingress それ自体はルールのみを持ち、Ingress Controller がロードバランサーとして機能する。
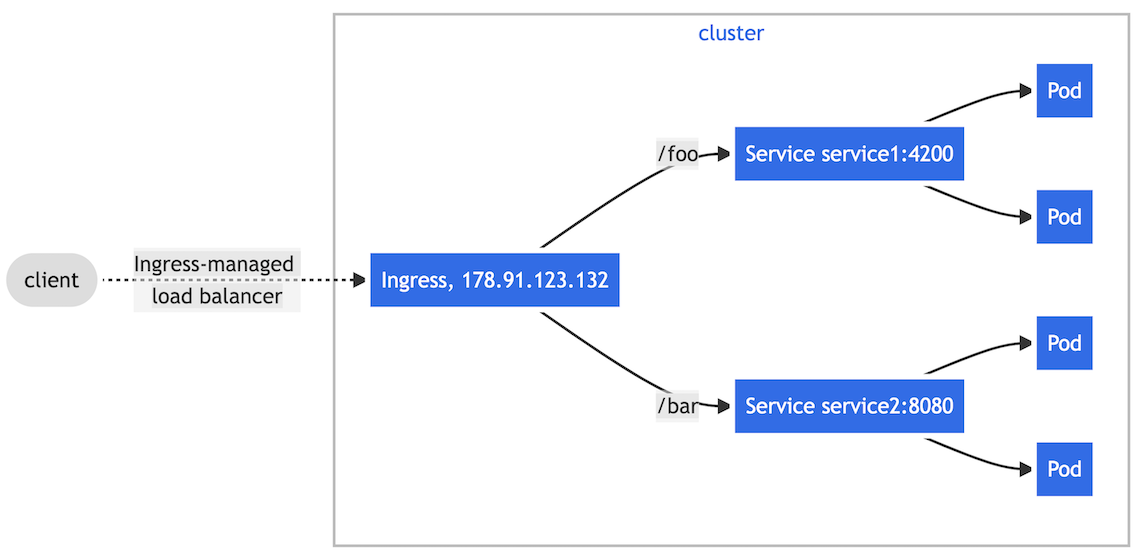
▼ パスベースルーティング¶
パスの値に基づいて、Service にルーティングする。
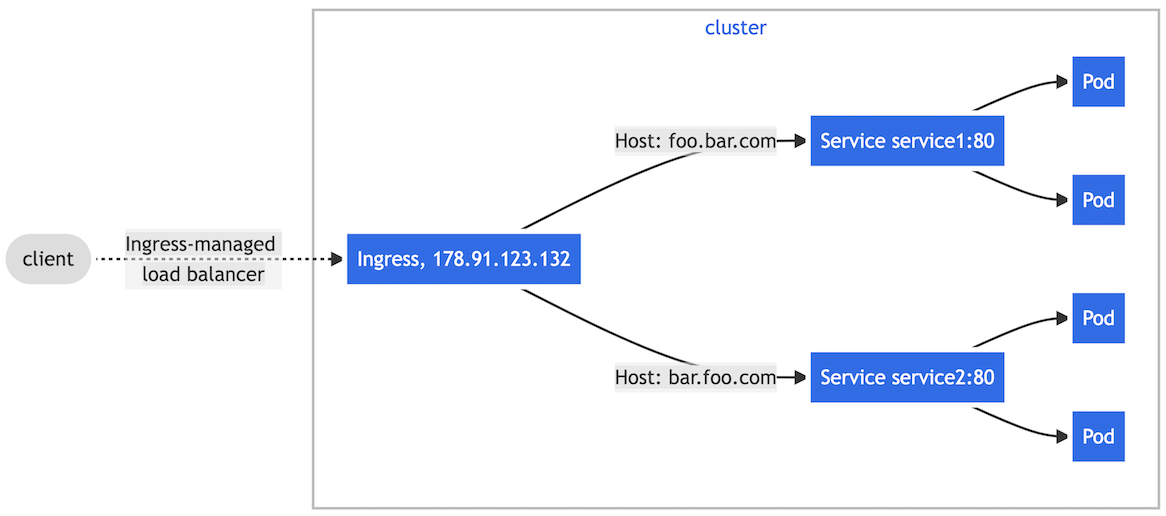
▼ ホストベースルーティング¶
Host ヘッダー値に基づいて、Service にルーティングする。
本番環境では、ドメインを指定した各種ダッシュボードにリクエストを送信できる必要がある。
IngressClass¶
▼ IngressClassとは¶
Ingress Controller の実体として使用するツールを指定する。
Ingress Controller¶
▼ Ingress Controllerとは¶
Ingress Controller は、L7 ロードバランサーとして Pod に通信をルーティングする。
Node 外から通信を受信し、Ingress で定義したルールに応じて、単一/複数の Service へルーティングする。
クラウドプロバイダー (例:AWS) では、Ingress Controller 状況下で Ingress を作成すると、Ingress の設定値に応じた L7 ロードバランサー (例:AWS ALB と AWS ターゲットグループ) を自動的にプロビジョニングする。
ただし、クラウドプロバイダーによっては、Ingress Controller と ClusterIP Service を中継するカスタムリソース (例:AWS TargetGroupBindings など) を提供している場合がある。
この場合、クラウドプロバイダーのリソースと Kubernetes が疎結合になり、責務の境界を明確化できる。
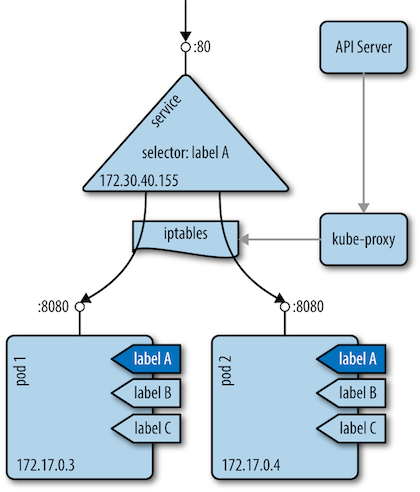
Service¶
▼ Serviceとは¶
Service は、L4 ロードバランサーとして Pod に通信をルーティングする。
kube-proxy が更新した iptables を使用し、また負荷分散方式によるルーティング先 Pod の決定に基づいて、Pod に通信をルーティングする。
DaemonSet や Job で使用する例は少ないが、Pod さえあればすべての Workload (例:Deployment、DaemonSet、StatefulSet、Job など) で Service を使用できる。
マイクロサービスアーキテクチャのコンポーネントである『Service』とは区別する。
▼ ClusterIP Service¶
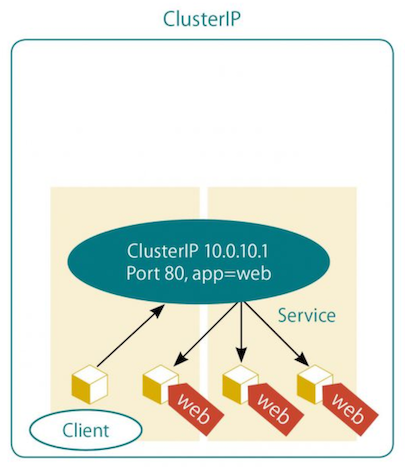
L4 ロードバランサーとして、Service に対する通信を、Cluster-IP を経由して Pod にルーティングする。
Cluster-IP は Service の .spec.clusterIP キーを指定しない限りランダムで決まる。また、Pod の /etc/resolv.conf ファイルに記載される。
Pod 内に複数のコンテナがある場合、各コンテナに同じ内容の /etc/resolv.conf ファイルが配置される。
$ kubectl exec -it <Pod名> -c <コンテナ名> -- bash
[root@<Pod名>] $ cat /etc/resolv.conf
nameserver *.*.*.* # ClusterネットワークのIPアドレス
search default.svc.cluster.local svc.cluster.local cluster.local
options ndots:5 # 名前解決時のローカルドメインの優先度
Cluster-IP は Node 外から宛先として指定できないため、通信に Ingress を必要とする。
パブリックネットワーク
⬇⬆️︎
# L7ロードバランサー
Ingress Controller (例:Nginx Ingress Controller、AWS Load Balancer Controllerなど)
⬇⬆️︎
# L4ロードバランサー
ClusterIP Service
⬇⬆️︎
Pod
Ingress がないと Cluster ネットワーク内からのみしかアクセスできず、安全である。
一方でもし Ingress を使用する場合、LoadBalancer Service と同様にして (レイヤーは異なるが) 、Pod の IP アドレスを宛先とする L7 ロードバランサー (例:AWS ALB と AWS ターゲットグループ) を自動的にプロビジョニングする。
そのため、クラウドプロバイダーのリソースと Kubernetes リソースが密結合になり、責務の境界が曖昧になってしまう。
- https://www.imagazine.co.jp/%e5%ae%9f%e8%b7%b5-kubernetes%e3%80%80%e3%80%80%ef%bd%9e%e3%82%b3%e3%83%b3%e3%83%86%e3%83%8a%e7%ae%a1%e7%90%86%e3%81%ae%e3%82%b9%e3%82%bf%e3%83%b3%e3%83%80%e3%83%bc%e3%83%89%e3%83%84%e3%83%bc%e3%83%ab/
- https://thinkit.co.jp/article/18263
- https://qiita.com/tkusumi/items/da474798c5c9be88d9c5#%E8%83%8C%E6%99%AF
▼ NodePort Service¶
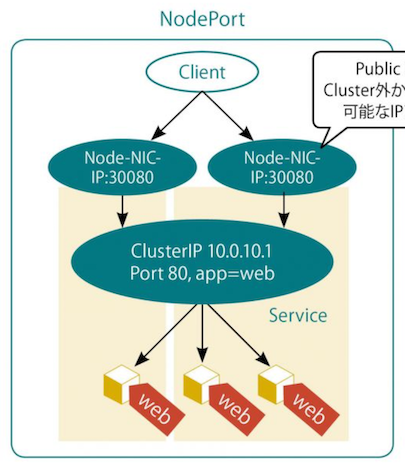
L4 ロードバランサーとして、Service に対する通信を、Node の NIC の宛先情報 (IP アドレス、ポート番号) 、Cluster-IP を経由して Pod にルーティングする。
Node の NIC の宛先情報は、Node 外から宛先 IP アドレスとして指定できるため、通信に Ingress を必要としない。
パブリックネットワーク
⬇⬆️︎
# L4ロードバランサー
NodePort Service
⬇⬆️︎
Pod
パブリックプロバイダーの LB (例:AWS ALB) を別に配置してもよい (この LB は、Ingress Controller 由来ではない) 。
パブリックネットワーク
⬇⬆️︎
Amazon Route 53
⬇⬆️︎
# L7ロードバランサー
AWS ALB
⬇⬆️︎
# L4ロードバランサー
NodePort Service
⬇⬆️︎
Pod
ただし、NodePort Service は内部的に Cluster-IP を使っている。
そのため、Ingress を作成すると NodePort Service の Cluster-IP を経由して Pod にルーティングする。
この場合、Node の IP アドレスと Ingress の両方が Node の通信の入り口となり、入口が無闇に増えるため、やめたほうがよい。
パブリックネットワーク
⬇⬆️︎
# L7ロードバランサー
Ingress Controller (例:Nginx Ingress Controller、AWS Load Balancer Controller)
⬇⬆️︎
# L4ロードバランサー
ClusterIP Service (実体はNodePort Service)
⬇⬆️︎
Pod
Node の NIC の宛先情報は、Node の作成方法 (例:Amazon EC2、Google Cloud GCE、VMWare) に応じて、確認方法が異なる。
Service のポート番号と紐づく Node の NIC のポート番号はデフォルトではランダムであるため、Node の NIC のポート番号を固定する必要がある。
1 個の Node のポート番号につき、1 個の Service としか紐付けられず、Service が増えていってしまうため、実際の運用にやや不向きである。
この場合、クラウドプロバイダーのリソースと Kubernetes が疎結合になり、責務の境界を明確化できる。
例えば、ポート番号は種類に応じて 200 番の間隔で分類する。
################################################
# L7ロードバランサーによるヘルスチェックの流入口
################################################
apiVersion: v1
kind: Service
metadata:
name: health-check
spec:
type: NodePort
ports:
- name: http-health-check
port: 15021
targetPort: 15021
nodePort: 31000
---
################################################
# Fooに関する流入口
# port: 8000~8199
# targetPort: 8000~8199
# nodePort: 30000~30199
################################################
apiVersion: v1
kind: Service
metadata:
name: foo
spec:
type: NodePort
ports:
- name: http-foo
port: 8000
targetPort: 8000
nodePort: 30000
---
################################################
# Barに関する流入口
# port: 8200~8399
# targetPort: 8200~8399
# nodePort: 30200~30399
################################################
apiVersion: v1
kind: Service
metadata:
name: bar
spec:
type: NodePort
ports:
- name: http-bar
port: 8200
targetPort: 8200
nodePort: 30200
▼ LoadBalancer Service¶
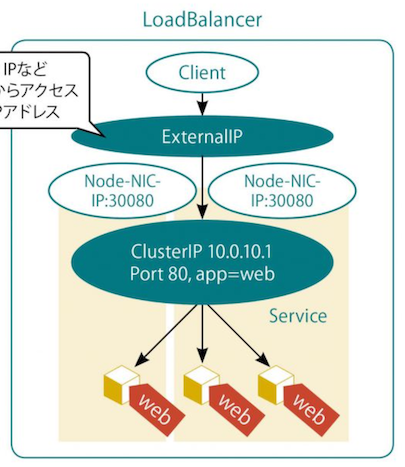
L4 ロードバランサーとして、Service に対する通信を、External-IP、Node の NIC の宛先情報 (IP アドレス、ポート番号)、Cluster-IP を経由して Pod にルーティングする。
External-IP は Node 外から宛先 IP アドレスとして指定できる。
そのため、通信に Ingress を必要としないが、外部のロードバランサーのみが宛先 IP アドレスを指定できる。
パブリックネットワーク
⬇⬆️︎
Amazon Route 53
⬇⬆️︎
# L4ロードバランサー
LoadBalancer ServiceによるAWS NLB
⬇⬆️︎
Pod
クラウドプロバイダー (例:AWS) では、LoadBalancer Service を作成すると、External-IP を宛先とする L4 ロードバランサー (例:AWS NLB と AWS ターゲットグループ) を自動的にプロビジョニングする。
クラウドプロバイダーのリソースと Kubernetes リソースが密結合になり、責務の境界が曖昧になってしまう。
なお、注意点として、Ingress Controller は L7 ロードバランサーを自動的にプロビジョニングする。
- https://www.imagazine.co.jp/%e5%ae%9f%e8%b7%b5-kubernetes%e3%80%80%e3%80%80%ef%bd%9e%e3%82%b3%e3%83%b3%e3%83%86%e3%83%8a%e7%ae%a1%e7%90%86%e3%81%ae%e3%82%b9%e3%82%bf%e3%83%b3%e3%83%80%e3%83%bc%e3%83%89%e3%83%84%e3%83%bc%e3%83%ab/
- https://medium.com/google-cloud/kubernetes-nodeport-vs-loadbalancer-vs-ingress-when-should-i-use-what-922f010849e0
- https://thinkit.co.jp/article/18263
- https://www.ios-net.co.jp/blog/20230621-1179/
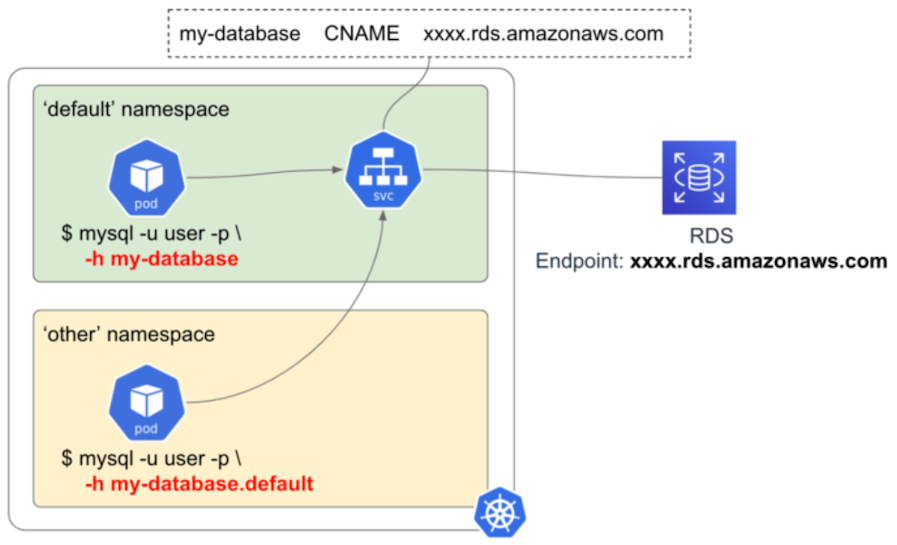
▼ ExternalName Service¶
Cluster 内 DNS 名と Cluster 外 CNAME レコードを対応づけ、Service に対する通信を対象にルーティングする。
例えば、foo-db-service という ExternalName Service を作成したとする。
この場合、foo-db-service.default.svc.cluster.local を指定すると、指定した CNAME レコードに問い合わせる。
マイクロサービスが外部のドメインに直接リクエストを送信できるが、これを Service のドメインに抽象化できる。
▼ Headless Service¶
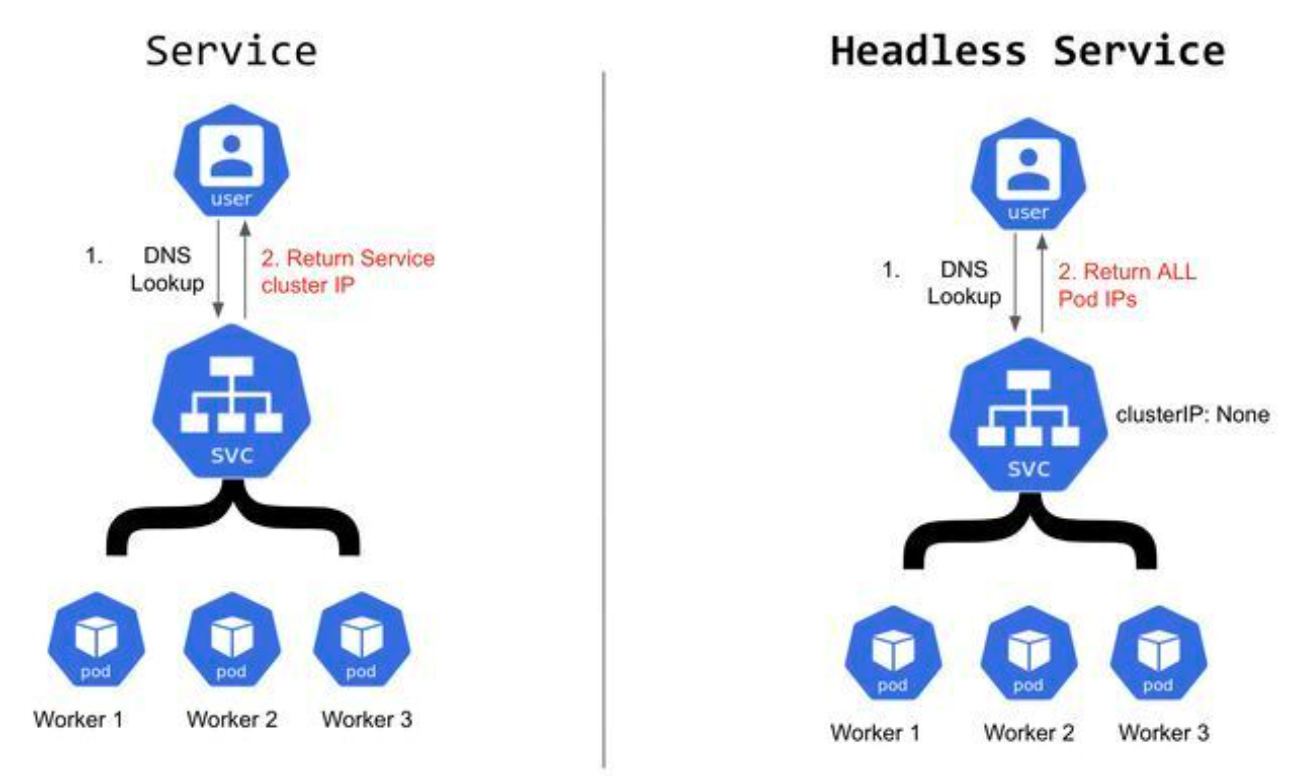
Headless Service 以外の Service は、負荷分散方式により、配下のいずれかの Pod の IP アドレスを返却する。
その一方で、Headless Service は配下のすべての Pod の IP アドレスを同時に返却する。
DNS サーバーは Headless Service から IP アドレスを取得し、
$ dig <Serviceの完全修飾ドメイン名>
;; QUESTION SECTION:
;<Serviceの完全修飾ドメイン名>. IN A
;; ANSWER SECTION:
<Serviceの完全修飾ドメイン名>. 30 IN A 10.8.0.30
<Serviceの完全修飾ドメイン名>. 30 IN A 10.8.1.34
<Serviceの完全修飾ドメイン名>. 30 IN A 10.8.2.55
なお、Headless Service から StatefulSet にルーティングする場合は、唯一、Pod で直接的に名前解決できるようになる。
$ dig <Pod名>.<Serviceの完全修飾ドメイン名>
;; QUESTION SECTION:
;<Pod名>.<Serviceの完全修飾ドメイン名>. IN A
;; ANSWER SECTION:
<Pod名>.<Serviceの完全修飾ドメイン名>. 30 IN A 10.8.0.30
03-04. Serviceの仕組み¶
パケットの処理方法¶
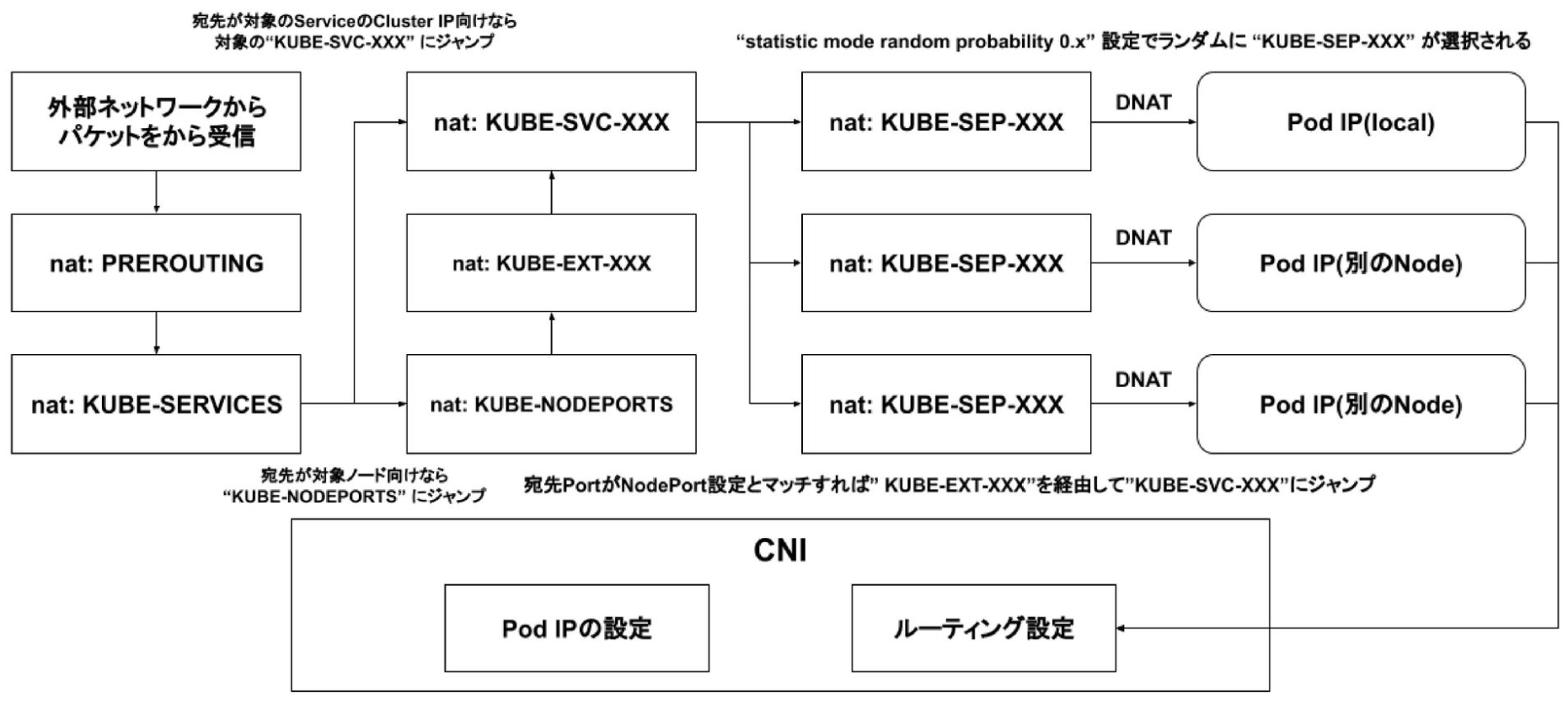
Service は、パケットの L4 に関するヘッダーの持つ情報を見て、Pod に L4 ロードバランシングする。
Service が Pod と紐づいたり、切り離したりした後、kube-procy が iptables を変更する。
受信したリクエストをパケットとして処理していく流れを見ていく。
(1)-
ここでは、ClusterIP Service を例に挙げる。
10.0.0.10というIPアドレスを持つClusterIP Serviceがいるとする。
$ kubectl get svc kube-dns -n kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kube-dns ClusterIP 10.0.0.10 <none> 53/UDP,53/TCP 12d
(2)-
kube-proxy で iptables を確認すると、受信したリクエストをパケットとして処理していく流れを確認できる。
KUBE-SERVICESターゲット配下にはKUBE-SVCターゲットがいる。KUBE-SVCターゲットは、ClusterIP Serviceである。
$ kubectl exec -it kube-proxy-wf7qw -n kube-system -- iptables -nL -t nat --line-numbers
Chain KUBE-SERVICES (2 references)
num target prot opt source destination
...
5 KUBE-MARK-MASQ udp -- !172.16.10.0/24 10.0.0.10 /* kube-system/kube-dns:dns cluster IP */ udp dpt:53
# Serviceにルーティングするための設定
6 KUBE-SVC-TCOU7JCQXEZGVUNU udp -- 0.0.0.0/0 10.0.0.10 /* kube-system/kube-dns:dns cluster IP */ udp dpt:53
...
(2)-
KUBE-SVCターゲット配下にはKUBE-SEPターゲットがいる。statistic mode random probabilityに応じて、パケットをKUBE-SEPのターゲットいずれかに振り分ける。
# KUBE-SVC
Chain KUBE-SVC-TCOU7JCQXEZGVUNU (1 references)
num target prot opt source destination
1 KUBE-SEP-K7EZDDI5TWNJA7RX all -- 0.0.0.0/0 0.0.0.0/0 /* kube-system/kube-dns:dns */ statistic mode random probability 0.50000000000
2 KUBE-SEP-JTVLMQFBDVPXUWUS all -- 0.0.0.0/0 0.0.0.0/0 /* kube-system/kube-dns:dns */
(3) KUBE-SEP のターゲットに応じて、異なる DNAT ターゲットを持つ。
`DNAT`ターゲットは、Podである。
kube-proxyはDNAT処理を実行し、パケットの宛先IPアドレス (ServiceのIPアドレス) をPodのIPアドレスに変換する。
ここでは、パケットの宛先IPアドレスを`172.16.10.9`と`172.16.10.42`に変換する。
Chain KUBE-SEP-K7EZDDI5TWNJA7RX (1 references)
num target prot opt source destination
1 KUBE-MARK-MASQ all -- 172.16.10.42 0.0.0.0/0 /* kube-system/kube-dns:dns */
2 DNAT udp -- 0.0.0.0/0 0.0.0.0/0 /* kube-system/kube-dns:dns */ udp to:172.16.10.42:53
Chain KUBE-SEP-JTVLMQFBDVPXUWUS (1 references)
num target prot opt source destination
1 KUBE-MARK-MASQ all -- 172.16.10.9 0.0.0.0/0 /* kube-system/kube-dns:dns */
2 DNAT udp -- 0.0.0.0/0 0.0.0.0/0 /* kube-system/kube-dns:dns */ udp to:172.16.10.9:53
(4) 宛先の Pod の IP アドレスを確認すると、DNAT 処理の変換後の IP アドレスと一致している。
$ kubectl get po -n kube-system -o wide -l k8s-app=kube-dns
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
coredns-69c47794-6xnlq 1/1 Running 0 18h 172.16.10.9 aks-nodepool1-19344272-vmss000000 <none> <none>
coredns-69c47794-cgn9k 1/1 Running 0 7d9h 172.16.10.42 aks-nodepool1-19344272-vmss000001 <none> <none>
Headless Serviceのユースケース¶
▼ ライターPodとリーダーPodのクラスタリングする場合¶
StatefulSet で MySQL をクラスタリングした場合、ライターPod とリーダーPod がいる。
アプリケーションはライターPod とリーダーPod の両方の IP アドレスを認識し、いずれに永続化するべきかを判断する必要がある。
この場合、すべての Pod の IP アドレスを返却する Headless Service が適している。
▼ Pod間でデータ同期が必要な場合¶
StatefulSet で Keycloak をクラスタリングした場合、JGroups は Infinispan クラスターインスタンス間でセッションデータを同期する。
JGroups がすべての Infinispan クラスターインスタンス間でセッションデータを同期できるように、Infinispan を内蔵したすべての Keycloak Pod を認識できるようにする必要がある。
04. Clusterリソース¶
Clusterリソースとは¶
Cluster 全体に渡る機能を提供する。
Namespace¶
▼ Namespaceとは¶
各 Kubernetes リソースの影響範囲を制御するための領域のこと。
Namespace が異なれば、.metadata.labels キーに同じ値 (例:同じ名前など) を設定できる。
▼ 初期Namespace¶
| 名前 | 説明 |
|---|---|
default |
任意のKubernetesリソースを配置する。 |
kube-node-lease |
Kubernetesリソースのうちで、特にLeaseを配置する。 |
kube-public |
すべてのkube-apiserverクライアント (kubectl クライアント、Kubernetesリソース) に公開してもよいKubernetesリソースを配置する。 |
kube-system |
Kubernetesが自動的に作成したKubernetesリソースを配置する。ユーザーが設定する必要はない。 |
▼ NamespaceがTerminatingのままになる¶
以下の方法で対処する。
05. 設定系リソース¶
設定系リソースとは¶
コンテナで使用する変数、ファイル、ボリュームに関する機能を提供する。
ConfigMap¶
▼ ConfigMapとは¶
コンテナで使用する機密ではない変数やファイルをマップ型で保持できる。
改行することにより、設定ファイルも値に格納できる。
▼ 機密ではない変数の例¶
| 変数 | 何のために使用するのか |
|---|---|
| DBホスト名 | コンテナがDBに接続するときに、DBのホスト名として使用する。 |
| DBポート番号 | コンテナがDBに接続するときに、DBのポート番号として使用する。 |
| DBタイムアウト | コンテナがDBに接続するときに、タイムアウト時間として使用する。 |
| DB接続リトライ数 | コンテナがDBに接続するときに、リトライの回数として使用する。 |
| タイムゾーン | コンテナ内のタイムゾーンとして使用する。 |
| ... | ... |
Secret¶
▼ Secretとは¶
コンテナで使用する機密な変数やファイルをキーバリュー型で永続化する。
永続化されている間は base64 方式でエンコードされており、デコードしたうえで、変数やファイルとして対象の Pod に出力する。
▼ 機密ではない変数の例¶
| 変数 | 何のために使用するのか |
|---|---|
| DBユーザー名 | コンテナがDBに接続するときに、DBユーザーのユーザー名として使用する。 |
| DBパスワード | コンテナがDBに接続するときに、DBユーザーのパスワードとして使用する。 |
| ... | ... |
▼ コンテナイメージプルのパラメーターとして¶
Pod の起動時に、kubectl コマンドが実行され、コンテナイメージをプルする。
Secret に永続化された値を復号し、kubectl コマンドにパラメーターとして出力できる。
▼ コンテナの環境変数として¶
永続化された値を復号し、Pod 内のコンテナに環境変数として出力できる。
06. ストレージ系リソース¶
ストレージ系リソースの種類¶
Kubernetes で作成できるストレージは、作成場所で種類を分けられる。
| ストレージの種類 | Volume | PersistentVolume |
|---|---|---|
| Pod内ストレージ | EmptyDir | なし |
| Node内ストレージ | HostPath | HostPath、Local |
| Node外ストレージ | Node外ストレージ | Node外ストレージ |
PersistentVolume¶
▼ PersistentVolumeとは¶
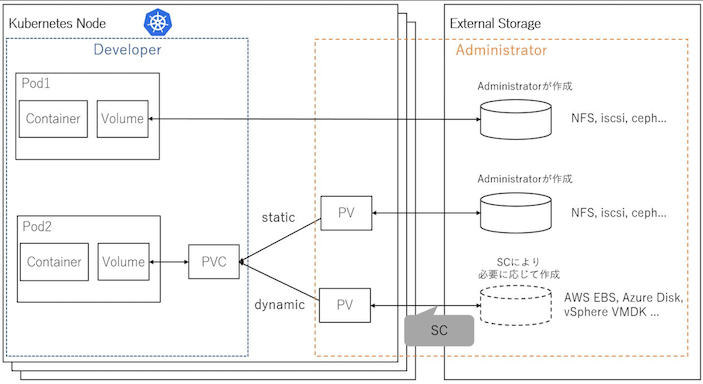
Node 上のストレージ上に Volume を作成する。
Node 上の Pod 間で Volume を共有でき、同一 Pod 内のコンテナ間でも Volume を共有できる。
Pod が PersistentVolume を使用するためには、PersistentVolumeClaim に PersistentVolume を要求させておき、Pod でこの PersistentVolumeClaim を指定する必要がある。
アプリケーションのディレクトリ名を変更した場合は、PersistentVolume を再作成しないと、アプリケーション内のディレクトリの読み出しでパスを解決できない場合がある。
Docker の Volume とは独立した機能であることに注意する。
▼ PersistentVolumeの使用率の確認方法 (CrashLoopBackOffでない場合)¶
Pod 内で df コマンドを実行することにより、PersistentVolume の使用率を確認できる。
出力結果で、ファイルシステム全体の使用率を確認する。
$ kubectl exec -n prometheus foo-pod -- df -hT
ただし、CrashLoopBackOff などが理由で、コンテナがそもそも起動しない場合、この方法で確認できない。
また、Grafana の kubernetes-mixins には、起動中の Pod の PersistentVolume の使用率を可視化できるダッシュボードがある。
▼ PersistentVolumeの使用率の確認方法 (CrashLoopBackOffの場合)¶
ここでは、Prometheus を例に挙げる。
(1)-
Prometheus の Pod に紐づく PersistentVolume は、最大 200Gi を要求していることがわかる。
$ kubectl get pvc foo-prometheus-pvc -n prometheus
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
foo-prometheus-pvc Bound pvc-***** 200Gi RWO gp3-encrypted 181d
(2)-
Node 内 (Amazon EKS の EC2 ワーカーNode の場合) で、Pod に紐づく PersistentVolume がマウントされているディレクトリを確認する。
$ ls -la /var/lib/kubelet/plugins/kubernetes.io/aws-ebs/mounts/aws/<リージョン>/vol-*****/prometheus-db/
-rw-r--r-- 1 ec2-user 2000 0 Jun 24 17:07 00004931
-rw-r--r-- 1 ec2-user 2000 0 Jun 24 17:09 00004932
-rw-r--r-- 1 ec2-user 2000 0 Jun 24 17:12 00004933
...
drwxrwsr-x 2 ec2-user 2000 4096 Jun 20 18:00 checkpoint.00002873.tmp
drwxrwsr-x 2 ec2-user 2000 4096 Jun 21 02:00 checkpoint.00002898
drwxrwsr-x 2 ec2-user 2000 4096 Jun 21 04:00 checkpoint.00002911.tmp
(3)-
dfコマンドでストレージの使用率を確認する。Node にマウントされているデータサイズを確認すると、197G となっている。PersistentVolume に対してデータサイズが大きすぎる。
$ df -h /var/lib/kubelet/plugins/kubernetes.io/aws-ebs/mounts/aws/ap-northeast-1a/vol-*****/prometheus-db/
Filesystem Size Used Avail Use% Mounted on
/dev/nvme8n1 197G 197G 0 100% /var/lib/kubelet/plugins/kubernetes.io/aws-ebs/mounts/aws/ap-northeast-1a/vol-*****
▼ HostPath (本番環境で非推奨)¶
Node のストレージ上に Volume を作成し、これをコンテナにバインドマウントする。
機能としては、Volume の一種である Pod による HostPath と同じである。
マルチ Node はサポートしていないため、本番環境では非推奨である。
▼ Local (本番環境で推奨)¶
Node 上に Volume を作成し、これをコンテナにバインドマウントする。
マルチ Node をサポートしている (明言されているわけではく、HostPath との明確な違いがよくわからない) 。
▼ Node外ストレージツールのVolume¶
Node 外ストレージツール (例:AWS EBS、NFS、iSCSI、Ceph など) が提供する Volume をコンテナにマウントする。
StorageClass と PersistentVolumeClaim を経由して、PersistentVolume と Node 外ストレージツールを紐付け、Volume としてコンテナにマウントする。
また、Node 外ストレージを使用する場合には、CSI ドライバーも必要である。
Volume¶
▼ Volumeとは¶
Node 外ストレージツール (例:AWS EBS、NFS、iSCSI、Ceph など) をそのまま Kubernetes の Volume として使用する。
Pod の .spec.volumes キーで指定する。
# Podに接続する
$ kubectl exec -it <Pod名> -c <コンテナ名> -- bash
# ストレージを表示する
[root@<Pod名>:/var/www/html] $ df -h
Filesystem Size Used Avail Use% Mounted on
overlay 59G 36G 20G 65% /
tmpfs 64M 0 64M 0% /dev
tmpfs 3.9G 0 3.9G 0% /sys/fs/cgroup
/dev/vda1 59G 36G 20G 65% /etc/hosts
shm 64M 0 64M 0% /dev/shm
overlay 59G 36G 20G 65% /var/www/foo # 作成したボリューム
tmpfs 7.8G 12K 7.8G 1% /run/secrets/kubernetes.io/serviceaccount
tmpfs 3.9G 0 3.9G 0% /proc/acpi
tmpfs 3.9G 0 3.9G 0% /sys/firmware
Pod が持つ Volume の一覧は、kubectl describe コマンドで確認できる。
$ kubectl describe pod
...
Volumes:
foo-volume:
Type: EmptyDir (a temporary directory that shares a pod's lifetime)
Medium:
SizeLimit: <unset>
bar-volume:
Type: EmptyDir (a temporary directory that shares a pod's lifetime)
Medium:
SizeLimit: <unset>
baz-volume:
Type: ConfigMap (a volume populated by a ConfigMap)
Name: baz-cm
Optional: false
▼ DockerのVolumeとの違い¶
Docker のボリュームとは独立した機能であることに注意する。
▼ HostPath (本番環境で非推奨)¶
Node 上の既存のストレージ上に Volume を作成し、コンテナにバインドマウントする。
バインドマウントは Node と Pod 内のコンテナ間で実行され、同一 Node 上の Pod 間でこの Volume を共有でき、同一 Pod 内のコンテナ間でも Volume を共有できる。
また、Pod が削除されてもこの Volume は削除されない。
HostPath は非推奨である。
# Node内でdockerコマンドを実行
$ docker inspect <コンテナID>
{
...
"HostConfig": {
"Binds": [
"/data:/var/www/foo",
"/var/lib/kubelet/pods/<PodのUUID>/volumes/kubernetes.io~projected/kube-api-access-*****:/var/run/secrets/kubernetes.io/serviceaccount:ro",
"/var/lib/kubelet/pods/<PodのUUID>/etc-hosts:/etc/hosts",
"/var/lib/kubelet/pods/<PodのUUID>/containers/foo/*****:/dev/termination-log"
],
...
},
...
"Mounts": [
...
{
"Type": "bind", # バインドマウントが使用されている。
"Source": "/data",
"Destination": "/var/www/foo",
"Mode": "",
"RW": "true",
"Propagation": "rprivate"
},
...
]
}
▼ EmptyDir¶
Pod の既存のストレージ上に Volume (/var/lib/kubelet/pods/<PodのUUID>/volumes/kubernetes.io~empty-dir/ ディレクトリ) を作成し、コンテナにボリュームマウントする。
ディレクトリの中身は、Node の Node 外ストレージやメモリ上 (上限は Node のメモリの 50%) に保管できる。
同一 Node 上の Pod 間でこの Volume を共有できず、同一 Pod 内のコンテナ間では Volume を共有できる。
また、Pod が削除されるとこの Volume も同時に削除されてしまう。
保持期間を設定できるツール (例:Prometheus、VictoriaMetrics、Grafana Mimir など) にて、Pod の Volume を EmptyDir としている場合、Pod を保持期間より先に削除すると、保持期間を待たずに Volume を削除することになってしまう。
▼ Node外ストレージツールのVolume¶
Node 外ストレージツール (例:AWS EBS、NFS、iSCSI、Ceph など) が提供する Volume をコンテナにマウントする。
同一 Node 上の Pod 間でこの Volume を共有でき、同一 Pod 内のコンテナ間でも Volume を共有できる。
また、Pod が削除されてもこの Volume は削除されない。
▼ Volumeの代わりにPersistentVolumeを使用する¶
Pod の .spec.volumes キーで PersistentVolumeClaim を宣言すれば、Volume の代わりに PersistentVolume を使用できる。
06-02. ストレージ要求系¶
PersistentVolumeClaim¶
▼ PersistentVolumeClaimとは¶
設定された条件に基づいて、Kubernetes で作成済みの PersistentVolume を要求し、指定した Kubernetes リソースに割り当てる。
▼ 削除できない¶
PersistentVolumeClaim を削除しようとすると、.metadata.finalizers キー配下に kubernetes.io/pvc-protection 値が設定され、削除できなくなることがある。
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
finalizers:
- kubernetes.io/pvc-protection
name: foo-persistent-volume-claim
spec: ...
この場合、kubectl edit コマンドなどで .metadata.finalizers キーを空配列に編集と、削除できるようになる。
$ kubectl edit pvc <PersistentVolumeClaim名>
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
finalizers: []
name: foo-persistent-volume-claim
spec: ...
▼ node affinity conflict¶
PersistentVolumeClaim は、annotation キー配下の volume.kubernetes.io/selected-node キーで、紐づく PersistentVolume が配置されている Node 名を指定している。
PersistentVolumeClaim は、条件に応じて PersistentVolume を探す。
しかし、PersistentVolumeClaim が volume.kubernetes.io/selected-node キーで指定する Node と、Pod をスケジューリングさせている Node が異なる AZ であると、以下のエラーになってしまう。
N node(s) had volume node affinity conflict, N node(s) didn't match Pod's node affinity/selector
これが起こる原因はさまざまある (例:Node の再作成時に Pod のある Node の AZ が変わる、AWS のスポットインスタンスで特定の AZ にしか Node が作成されない)。
*解決例*
ここでは、Node の再作成で Pod のある Node の AZ が変わった場合の解決策を記載する。
AWS のスポットインスタンスで特定の AZ にしか Node が作成されない問題では対処できない。
例えば、もともと a ゾーンにいる Pod が Node の再作成で再スケジューリングされ、c ゾーンになったとする。
しかし、Pod に紐づく PersistentVolumeClaim はもともとの a ゾーンの Node の PersistentVolume を指定したままになっており、c ゾーンの Pod は a ゾーンの PersistentVolume を指定できないため、volume node affinity conflict になる。
以下の手順で、PersistentVolumeClaim とこれを指定する Pod の両方を再作成し、PersistentVolumeClaim は Pod と同じゾーンの PersistentVolume を指定可能にする。
注意点として、何らかの理由 (例:スポットインスタンス) で、特定の AZ に Node を配置できない場合、この手順では解決できない。
(1)-
起動できない Pod をいずれの Node でスケジューリングさせようとしているのか確認する。
$ kubectl describe pod <Pod名> -o wide | grep Node:
(2)-
Node のあるゾーンを確認する。
$ kubectl describe node <PodのあるNode名> | grep topology.kubernetes.io
(3)-
PersistentVolumeClaim の
volume.kubernetes.io/selected-nodeキーで、Pod がいずれの Node の PersistentVolume を指定しているかを確認する。このNode名をメモしておく。
$ kubectl describe pvc <PVC名> -n prometheus | grep selected-node
(4)-
Node のあるゾーンを確認する。
$ kubectl describe node ip-*-*-*-*.ap-northeast-1.compute.internal | grep zone
(5)-
(1)と(4)の手順で確認した Node のゾーンが異なるゾーンであることを確認する。
(6)-
PersistentVolumeClaim を削除する。
この時PersistentVolumeは削除されないため、保管データは削除されない。
(7)-
StatefulSet 自体を再作成する。
(8)-
StatefulSet が PersistentVolumeClaim を新しく作成する。
(9)-
PersistentVolumeClaim が、Pod と同じゾーンの PersistentVolume を指定できるようになる。
▼ サイズを拡張する¶
PersitentVolumeClaim の値が変われば、使用する PersistentVolume を変えられる。
--cascade オプションで Pod を残して StatefulSet を
$ kubectl patch prometheus foo --patch '{"spec": {"paused": "true", "storage": {"volumeClaimTemplate": {"spec": {"resources": {"requests": {"storage":"10Gi"}}}}}}}' --type merge
$ kubectl delete statefulset -l operator.prometheus.io/name=foo-operator --cascade=orphan
StorageClass¶
▼ StorageClassとは¶
Node 外ストレージツール (例:AWS EBS、Azure Disk など) を要求し、これを Volume として PersistentVolumeClaim に提供する。
そのため、PersistentVolume も合わせて作成する必要がある。
StorageClass を使用する場合は、PersistentVolumeClaim ではなく StorageClass 側で reclaimPolicy キーとして設定する。
▼ AWS EBSを要求する場合¶
reclaimPolicy が Delete になっている PersistentVolumeClaim を削除すれば、StorageClass が AWS EBS もよしなに削除してくれる。
07. 認証系リソース¶
CertificateSigningRequest¶
▼ CertificateSigningRequestとは¶
認証局に対するサーバー証明書の要求 (openssl x509 コマンド) を宣言的に設定する。
別途、秘密鍵から証明書署名要求を作成し、これをパラメーターとして設定する必要がある。
ServiceAccount¶
▼ ServiceAccountとは¶
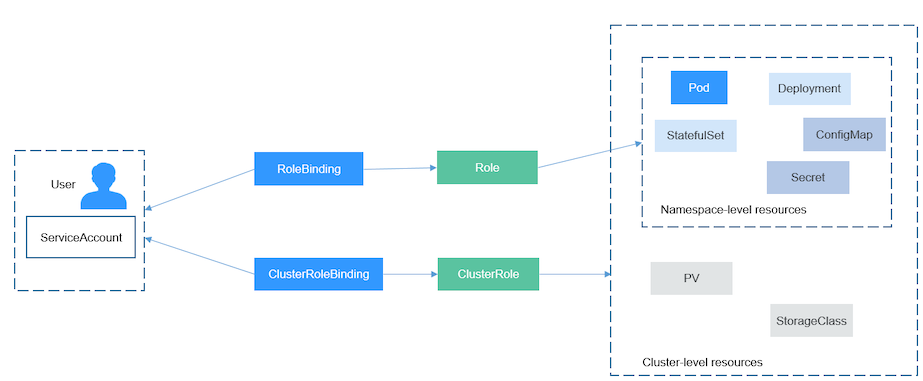
kube-apiserver が、クライアント側を認証可能にする。
kube-apiserver が、Kubernetes リソース (特に Pod) を認証可能にする。
別途、RoleBinding や ClusterRoleBinding を使用して Kubernetes リソースに認可スコープを設定する必要がある。
Pod で ServiceAccount の指定がない場合、service-account-admission-controller は Pod に ServiceAccount を自動的に設定する。
▼ ServiceAccountのユーザー名¶
特に ServiceAccount には、より正確な定義のユーザー名がある。
ServiceAccount のユーザー名は、system:serviceaccount:<Namespace名>:<ServiceAccount名> で定義されている。
これは、RoleBinding や ClusterBinding の定義時に使用できる。
▼ service-account-controller¶
各 Namespace 内に default という ServiceAccount を自動的に作成する。
これは、default の Namespace とは無関係である。
▼ token-controller¶
ServiceAccount 用の Secret の作成をポーリングし、Secret にトークン文字列を追加する。
一方で、Secret の削除をポーリングし、ServiceAccount から Secret の指定を削除する。
また、ServiceAccount の削除をポーリングし、token-controller は Secret のトークン文字列を自動的に削除する。
▼ service-account-admission-controller¶
AdmissionWebhook の仕組みのなかで、Pod の作成時に Volume 上の /var/run/secrets/kubernetes.io/serviceaccount ディレクトリをコンテナにマウントする。
トークンの文字列は、/var/run/secrets/kubernetes.io/serviceaccount/token ファイルに記載されている。
UserAccount¶
▼ UserAccountとは¶
kube-apiserver が、クライアント側を認証可能にする。
kube-apiserver が、クライアントを認証可能にする。別途、RoleBinding や ClusterRoleBinding を使用して、クライアントに認可スコープを設定する必要がある。
クライアントの認証に必要なクライアント証明書は、kubeconfig ファイルに登録する必要がある。
User/Group¶
クラウド上のユーザーやグループを Kubernetes 上で使用する場合、User/Group で指定する。
08. 認可系リソース¶
Role、ClusterRole¶
▼ Role¶
Namespaced スコープな Kubernetes リソースやカスタムリソース (Namespace を設定できる Kubernetes リソース) に関する認可スコープを設定する。
▼ ClusterRoleとは¶
Cluster スコープな Kubernetes リソースやカスタムリソース (Namespace を設定できない Kubernetes リソース) に関する認可スコープを設定する。
▼ RBAC:Role-based access control¶
Role、ClusterRole を使用して認可スコープを制御する仕組みのこと。
RoleBinding¶
▼ ClusterRoleBinding¶
ClusterRole を、UserAccount / ServiceAccount / Group に紐付ける。
注意点として、ClusterRole のみの紐付けに使用できる。
▼ RoleBinding¶
Role や ClusterRole を、UserAccount / ServiceAccount / Group に紐付ける。
注意点として、Role と ClusterRole の両方の紐付けに使用できる。
もし Role を紐づけた場合は、その UserAccount / ServiceAccount / Group は、Namespaced スコープの Kubernetes リソースやカスタムリソースに関する権限を得る。
もし ClusterRole を紐づけた場合は、その UserAccount / ServiceAccount / Group は、Cluster スコープの Kubernetes リソースやカスタムリソースに関する権限を得る。
09. ポリシー系リソース¶
NetworkPolicy¶
▼ NetworkPolicyとは¶
Pod 間通信でのインバウンド通信とアウトバウンド通信の送受信ルールを設定する。
▼ Ingressの場合¶
他の Pod からの受信する通信のルールを設定する。
Ingress とは関係がないことに注意する。
▼ Egressの場合¶
他の Pod に送信する通信のルールを設定する。