可観測性¶
はじめに¶
本サイトにつきまして、以下をご認識のほど宜しくお願いいたします。
01. 可観測性¶
可観測性とは¶
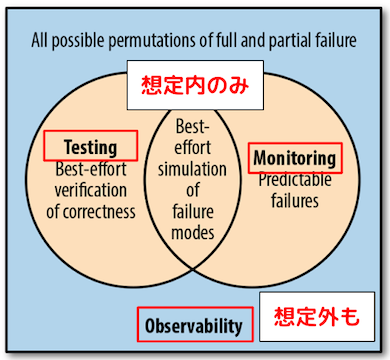
『収集したデータから、システムの想定内 (既知) と想定外 (未知) の両方の不具合を、どれだけ正確に推測できるか』を表す程度のこと。
システムの想定内の不具合は『監視』や『テスト (ホワイトボックステスト、ブラックボックステスト) 』によって検知できるが、想定外のものを検知できない。
可観測性は、監視やテストも含むスーパーセットであり、想定内の不具合のみでなく、想定外の不具合も表面化する。
想定外の不具合はインシデントの原因になるため、想定外の不具合の表面化はインシデントの予防につながる。
可観測性を高める方法¶
▼ マイクロサービスアーキテクチャの場合¶
テレメトリーを十分に収集し、これらを監視フロントエンドで可視化する必要がある。
▼ モノリシックアーキテクチャにおける可観測性¶
可観測性は、基本的にマイクロサービスアーキテクチャの文脈で語られる。
モノリシックでどのようにして可観測性を高めるのかを記入中... (情報が全然見つからない)
02. テレメトリー¶
テレメトリーとは¶
可観測性を実現するために収集する必要のあるデータ要素 (『メトリクス』『ログ』『分散トレース』) のこと。
NewRelic や Datadog はテレメトリーの要素をすべて持つ。
また、AWS では CloudWatch (メトリクス+ログ) と X-Ray (分散トレース) を両方利用すると、これらの要素を満たせたことになり、可観測性を実現できる。
計装 (インスツルメント化)¶
システムを、テレメトリーを収集できるような状態にすること。
計装するためには、データポイント収集用のツール、ロギングパッケージ、分散トレースのためのリクエスト ID の付与などを用意する必要がある。
多くの場合、各テレメトリーの収集ツールは別々に用意する必要があるが、OpenTelemetry ではこれらの収集機能をフレームワークとして提供しようとしている。
03. テレメトリー間の紐付け¶
メトリクスと分散トレースの紐付け¶
記入中...
ログと分散トレースの紐付け¶
記入中...
04. プロファイルの用途¶
分散トレースだけではマイクロサービス間のレスポンスタイムしかわからない。
プロファイルを導入すると、各マイクロサービスのハードウェアリソース消費量もわかるようになる。
これにより、性能デグレーションのボトルネックを特定しやすくなる。
05. その他のテレメトリー¶
メトリクス/ログ/分散トレース/プロファイルに加えて、新しいテレメトリーがいくつか提唱されている。
- Events (ドメインイベントのようなユーザー定義の処理イベント)
- Exception