ブラックボックステスト¶
はじめに¶
本サイトにつきまして、以下をご認識のほど宜しくお願いいたします。
01. ブラックボックステスト¶
ブラックボックステストとは¶
実装内容は気にせず、入力に対して、適切な出力が行われているかを検証する。
ユニットテストとホワイト/ブラックボックステストの関係性については、以下の書籍を参考にせよ。
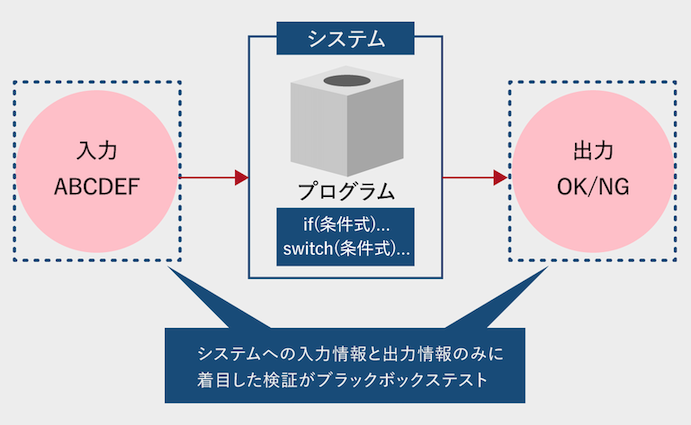
ブラックボックステストの種類¶
ホワイトボックステストと同じ名前のテストがあるが、実装内容を気にするか否かという点で、テスト内容は異なる。
- ユニットテスト
- 結合テスト
- 回帰テスト
- システムテスト
ブラックボックスの環境¶
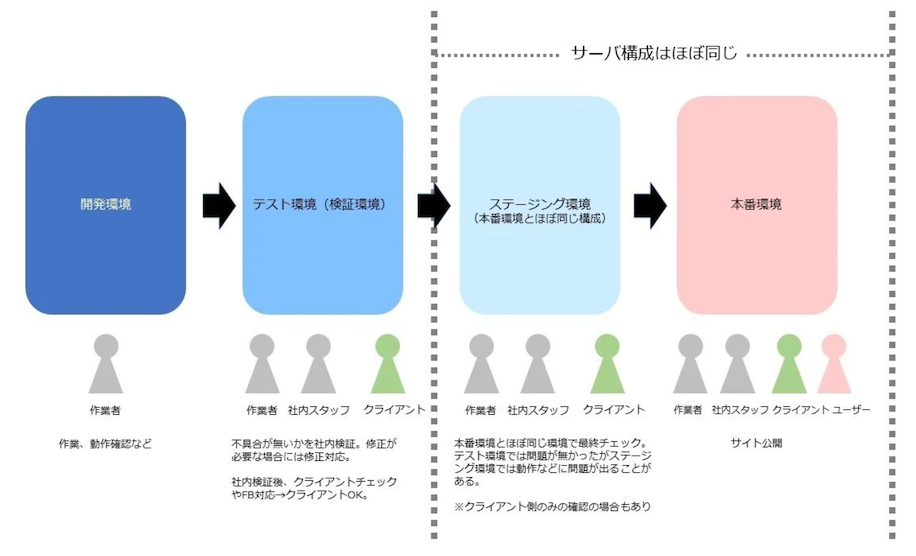
| 実行環境名 | 略称 | 説明 |
|---|---|---|
| 開発環境 (ローカル環境) | dev |
『ローカル環境』ともいう。ローカルマシンの環境であり、開発者が動作を確認するため使用する。 |
| テスト環境 (サンドボックス環境、検証環境) | tes (sbox) |
企業によっては、『サンドボックス環境』『検証環境』ともいう。共有の環境であり、開発環境で作成した機能をデプロイし、開発者が動作を確認するために使用する。 |
| ステージング環境 (ユーザー受け入れ環境) | stg (ua) |
システムの依頼者が社外にいる場合に『ユーザー受け入れ (UA) 環境』ともいう。共有の環境であり、システムの依頼者が社内にいる場合に、その依頼者が動作を確認するために使用する。 |
| 本番環境 | prd |
インターネットに公開された環境であり、Testing in productionを採用する場合は、一般のユーザーに動作を確認してもらう。 |
02. ユニットテスト (単体テスト)¶
ユニットテストとは¶
『単体テスト』ともいう。
機能追加/変更を含むコンポーネントのみが単体でまさしく動作するかを検証する。
ホワイトボックステストのユニットテストとは意味合いが異なることに注意する。
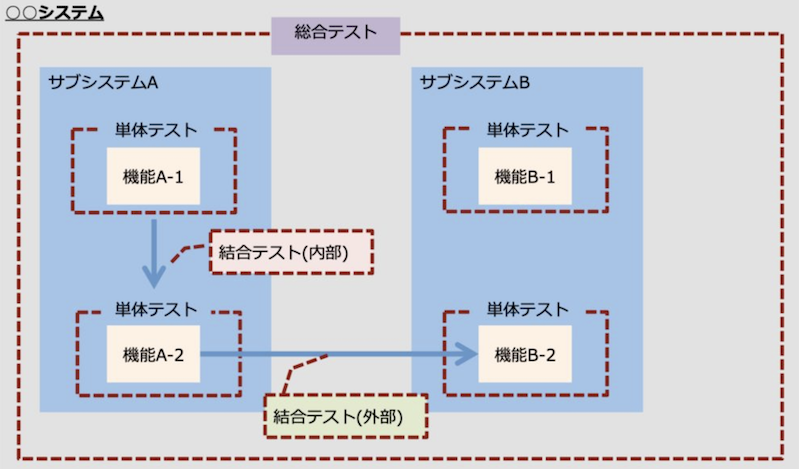
ユニットテストの種類¶
▼ 機能テスト¶
| テストの種類 | 検証内容 |
|---|---|
| 正常系 | 特定のシステムコンポーネントの処理を正しく操作できるか。 |
▼ 非機能テスト¶
| テストの種類 | 検証内容 |
|---|---|
| 正常系 | 特定のシステムコンポーネントのヘルスチェックが正常になっているか。 |
03. 結合テスト (統合テスト)¶
結合テストとは¶
『統合テスト』ともいう。
機能追加/変更を含む特定のコンポーネントを組み合わせ、特定のコンポーネント間の連携が正しく動作しているかを検証する。
注意点として、特定の機能に関するすべてのコンポーネント間の連携をテストする『E2E テスト』とは異なる。
結合テストの種類¶
▼ 機能テスト¶
| テストの種類 | 検証内容 |
|---|---|
| 正常系 | システムコンポーネント間の処理を正しく操作できるか |
▼ 非機能テスト¶
| テストの種類 | 検証内容 |
|---|---|
| 正常系 | システムコンポーネント間でまさしく連携できているか |
結合テストの方向¶
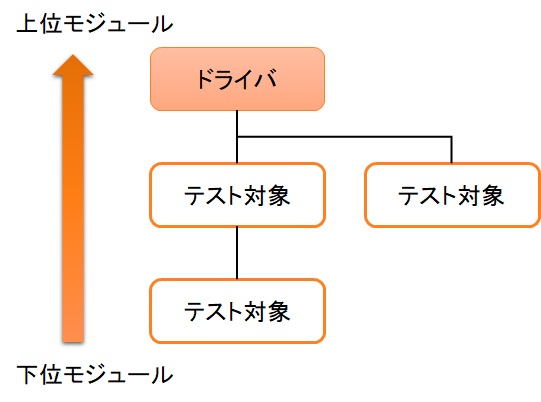
▼ トップダウンテスト¶
上層のコンポーネントから下層のコンポーネントに向かって、結合テストを実施する。
下層にはテストダブルのスタブを作成する。
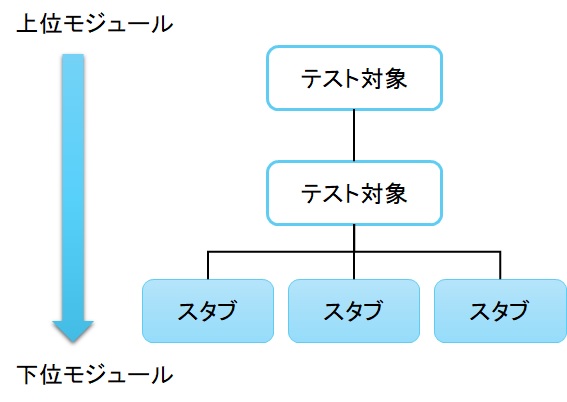
▼ ボトムアップテスト¶
下層のコンポーネントから上層のコンポーネントに向かって、結合テストを実施する。
上層にはテストダブルのドライバーを作成する。
シナリオテスト¶
実際の業務フローを参考にし、ユーザーが操作する順にテストを実施する。
04. 回帰テスト¶
回帰テストとは¶
既存コンポーネントの機能テストと非機能テストをあらためて実施する。
機能追加/変更を含むコンポーネントが既存のコンポーネントに影響を与えていないか (既存の機能でデグレーションが起こっていないか) を検証する。
回帰テストのテストケース¶
▼ 背景¶
Kubernetes の Node 上で、Kubernetes リソースとアプリケーションが稼働するシステムを運用している。
今回、Kubernetes リソースをアップグレードすることになった。
回帰テストを実施し、アップグレードによる機能追加/変更が、既存のコンポーネントに影響を与えていないかを検証する。
▼ Istioの場合¶
Istio のテストケースを示す。
| テスト種別 (UT:ユニットテスト、IT:結合テスト) |
組み合わせ (ITの場合のみ) | 確認方法 |
|---|---|---|
| UT | - | コントロールプレーンのPod (istio-deployment というDeployment配下のPod) が正常である。『Podが Running フェーズかつ Ready コンディションであること』をPodの正常とみなす。例えば、kubectl get コマンドを実行することにより、正常か否かを確認する。 |
| IT | Istio + Kubernetes |
istio.io/revキーのあるNamespaceのPodに、istio-proxyが挿入されている。例えば、kubectl get コマンドで -o jsonpath オプションを有効化し、確認する。 |
▼ Prometheusの場合¶
Prometheus のテストケースを示す。
| テスト種別 (UT:ユニットテスト、IT:結合テスト) |
組み合わせ (ITの場合のみ) | 確認方法 |
|---|---|---|
| UT | - | Podが正常である。『Podが Running フェーズかつ Ready コンディションであること』をPodの正常とみなす。例えば、kubectl get コマンドを実行することにより、正常か否かを確認する。 |
| UT | - | ・Podで収集したデータポイントがローカルストレージに永続化されている。 ・PodのローカルストレージがNodeにマウントされており、Podが削除されてもローカルストレージを再マウントできる。 |
| IT | Prometheus + VictoriaMetrics + Kubernetes |
Prometheusからメトリクスが送信されてきており、ダッシュボードでメトリクスを確認できる。例えば、メトリクスの cluster ラベルから、実行環境名 (dev、stg、prd) を確認する。 |
▼ Alertmanagerの場合¶
Alertmanager のテストケースを示す。
| テスト種別 (UT:ユニットテスト、IT:結合テスト) |
組み合わせ (ITの場合のみ) | 確認方法 |
|---|---|---|
| UT | - | Podが正常である。『Podが Running フェーズかつ Ready コンディションであること』をPodの正常とみなす。例えば、kubectl get コマンドを実行することにより、正常か否かを確認する。 |
| UT | - | ダッシュボード上から新しく作成したSilenceが、正常に動作している。 |
| IT | Alertmanager + Prometheus + Kubernetes |
ビルトインのPrometheusRule (.metadata.annotations キーにkubernetes-mixinへのURLを持つ) のアラートルールが発火した場合に、アラートを通知できる。必ずアラートが発火するような閾値 (例:ゼロ) に変更し、アラートが発火するかを検証する。 |
| IT | Alertmanager + Prometheus + Kubernetes |
ユーザ定義のPrometheusRuleのアラートルールが発火した場合に、アラートを通知できる。必ずアラートが発火するような閾値 (例:ゼロ) に変更し、アラートが発火するかを検証する。 |
| IT | Alertmanager + Prometheus + Kubernetes |
ダッシュボード上でアラートを捕捉しており、Prometheusから送信されたアラートを受信していることを確認できる。 |
▼ Grafanaの場合¶
Grafana のテストケースを示す。
| テスト種別 (UT:ユニットテスト、IT:結合テスト) |
組み合わせ (ITの場合のみ) | 確認方法 |
|---|---|---|
| UT | - | Podが正常である。『Podが Running フェーズかつ Ready コンディションであること』をPodの正常とみなす。例えば、kubectl get コマンドを実行することにより、正常か否かを確認する。 |
| UT | - | ビルトインのダッシュボード (mixin タグを持つ) を正しく読み込めるか。 |
| UT | - | ユーザ定義のダッシュボードを正しく読み込めるか。 |
| IT | Grafana + Prometheus + Kubernetes |
ビルトインのダッシュボード (mixin タグを持つ) でPromQLを入力し、Prometheusのメトリクスを確認できる。 |
| IT | Grafana + Prometheus + Kubernetes |
ユーザ定義のダッシュボードでPromQLを入力し、Prometheusのメトリクスを確認できる。 |
| IT | Grafana + Prometheus + Kubernetes |
ビルトインのダッシュボード (mixin タグを持つ) でPrometheusのメトリクスのリアルタイムデータを確認できる。 |
| IT | Grafana + Prometheus + Kubernetes |
ユーザ定義のダッシュボードでPrometheusのメトリクスのリアルタイムデータを確認できる。 |
| IT | Grafana + Prometheus + Kubernetes |
ビルトインのダッシュボード (mixin タグを持つ) で、datasource、namespace、type、resolusionの条件を変更し、リアルタイムデータを確認できる。 |
| IT | Grafana + Prometheus + Kubernetes |
ユーザ定義のダッシュボードで、datasource、namespace、type、resolusionの条件を変更し、リアルタイムデータを確認できる。 |
▼ PrometheusOperatorの場合¶
PrometheusOperator のテストケースを示す。
| テスト種別 (UT:ユニットテスト、IT:結合テスト) |
組み合わせ (ITの場合のみ) | 確認方法 |
|---|---|---|
| UT | - | PodMonitorの既存の設定が正常に動作しており、異常を検知するとアラートを発火できる。『Podが Running フェーズかつ Ready コンディションであること』をPodの正常とみなす。例えば、kubectl get コマンドを実行することにより、正常か否かを確認する。 |
| UT | - | Probeの既存の設定が正常に動作しており、異常を検知するとアラートを発火できる。 |
| UT | - | PrometheusRuleの既存の設定が正常に動作しており、異常を検知すると発火できる。 |
| UT | - | ServiceMonitorの既存の設定が正常に動作しており、異常を検知するとアラートを発火できる。 |
| UT | - | PrometheusOperatorのアラートが発火されていない。 |
▼ 各種Exporterの場合¶
各種 Exporter のテストケースを示す。
| Exporter名 | テスト種別 (UT:ユニットテスト、IT:結合テスト) |
組み合わせ (ITの場合のみ) | 確認方法 |
|---|---|---|---|
| kube-state-metrics | UT | - | Podが正常である。『Podが Running フェーズかつ Ready コンディションであること』をPodの正常とみなす。例えば、kubectl get コマンドを実行することにより、正常か否かを確認する。 |
| IT | kube-state-metrics + Prometheus + Kubernetes |
ダッシュボードでPromQLを入力し、Process Exporter経由で収集しているメトリクスを確認できる。例えば、kube_pod_info メトリクスや kube_node_info メトリクスを確認する。 |
|
| Node Exporter | UT | - | Podが正常である。『Podが Running フェーズかつ Ready コンディションであること』をPodの正常とみなす。例えば、kubectl get コマンドを実行することにより、正常か否かを確認する。 |
| IT | Node Exporter + Prometheus + Kubernetes |
ダッシュボードでPromQLを入力し、Node Exporter経由で収集しているメトリクスを確認できる。例えば、node_cpu_seconds_total メトリクスを確認する。 |
|
| Process Exporter | UT | - | Podが正常である。『Podが Running フェーズかつ Ready コンディションであること』をPodの正常とみなす。 |
| IT | Process Exporter + Prometheus + Kubernetes |
ダッシュボードでPromQLを入力し、Process Exporter経由で収集しているメトリクスを確認できる。例えば、namedprocess_namegroup_cpu_seconds_total メトリクスを確認する。 |
▼ Fluentdの場合¶
Fluentd のテストケースを示す。
| テスト種別 (UT:ユニットテスト、IT:結合テスト) |
組み合わせ (ITの場合のみ) | 確認方法 |
|---|---|---|
| UT | - | Podが正常である。『Podが Running フェーズかつ Ready コンディションであること』をPodの正常とみなす。例えば、kubectl get コマンドを実行することにより、正常か否かを確認する。 |
| IT | Fluentd + 監視バックエンド + 監視フロントエンド + Kubernetes |
Node内の任意のPodのログを正しい形式で監視バックエンドに送信し、監視フロントエンドで可視化できている。例えば、Containerdには、ログメッセージ部分がテキスト形式 (例:metrics-serverなど) の場合と json 形式 (例:alertmanager、istio-proxyなど) の場合がある。監視バックエンド (例:Grafana Loki) これらの両方の形式のログを正しく解析し、監視フロントエンド (例:Grafana、Kibana) がそれを可視化できていることを確認する。 |
▼ Kialiの場合¶
Kiali のテストケースを示す。
| テスト種別 (UT:ユニットテスト、IT:結合テスト) |
組み合わせ (ITの場合のみ) | 確認方法 |
|---|---|---|
| UT | - | Podが正常である。『Podが Running フェーズかつ Ready コンディションであること』をPodの正常とみなす。例えば、kubectl get コマンドを実行することにより、正常か否かを確認する。 |
| IT | Kiali + Prometheus + Istio |
Prometheusを介して、Istiodからメトリクスの元になるデータポイントを収集できているかを確認する。例えば、サービスメッシュトポロジーが表示されることを確認する。 PrometheusやIstioと通信できていない場合は、トポロジーを表示できない。 |
▼ metrics-serverの場合¶
metrics-server のテストケースを示す。
| テスト種別 (UT:ユニットテスト、IT:結合テスト) |
組み合わせ (ITの場合のみ) | 確認方法 |
|---|---|---|
| UT | - | Podが正常である。『Podが Running フェーズかつ Ready コンディションであること』をPodの正常とみなす。例えば、kubectl get コマンドを実行することにより、正常か否かを確認する。 |
| IT | metrics-server + Pod、Node |
Pod、Node、からメトリクスを取得できるかを確認する。例えば、kubectl top pod -A コマンドや kubectl top node コマンドで、PodやNodeのCPU使用率とメモリ使用率を取得できるかを確認する。また、 |
| IT | metrics-server + HorizontalPodAutoscaler |
HorizontalPodAutoscalerからメトリクスを取得できるかを確認する。例えば、事前に .spec.containers[*].resources キーが設定されたDeploymentを確認しておく。kubectl get hpa -A コマンドで、Target列が <unknown> になっていないことを確認する。 |
▼ その他¶
その他のテストケースを示す。
| コンポーネント | テスト種別 (UT:ユニットテスト、IT:結合テスト) |
組み合わせ (ITの場合のみ) | 確認方法 |
|---|---|---|---|
| その他 | - | - | Nameにて、不要なPodが稼働していないか。 |