プラクティス集@Kubernetesリソース¶
はじめに¶
本サイトにつきまして、以下をご認識のほど宜しくお願いいたします。
Cluster¶
バックアップ¶
例えば永続ボリュームを使用しているなど、クラスターの etcd の現在の状態の回復が必要な場合、障害でクラスター上のデータが損失することに備え、バックアップツール (例:Velero) を使用してクラスターバックアップを定期的に実行する。
もし単純に新しい Kubernetes Cluster にビルド可能な manifests を再インストール(kubectl apply)するだけで問題無く回復できるようなケースでは必ずしもクラスターバックアップは必要ない。
クラスターのDR構成¶
特定のリージョンのみにシステムを配置してしまうと、大規模な障害 (例:災害によるデータセンター大爆発!) があった場合に、システムのダウンタイムとなる。
システムに持たせたい耐障害性などにもよるが、こういったリージョン単位での障害に備える場合は複数リージョンで Kubernetes Cluster を構成することで耐障害性を高めることができる。
複数リージョンでの構成には主に以下のパターンがある。
| リージョン別Clusterパターン | リージョン横断Clusterパターン | |
|---|---|---|
| 説明 | リージョンごとに同一構成のClusterを配置する。 | Cluster内で、コントロールプレーンNodeとワーカーNodeを異なるリージョンに配置する。 |
| 備考 | リージョン間クラスターを構築する場合、当然リージョン内のクラスターと比べ通信の遅延が発生するため、リージョン間のetcd同期が遅くなったりといった影響がある。 | リージョンを横断する形でクラスターを構築した場合でも、DBなどの永続データを持つシステムは片方のリージョンだけで動かすか、あるいはリージョンをまたいで構築する必要がある。 |
上記の通りそれぞれ一長一短があり、運用コストも当然増加することになるため、十分に検討したうえで必要に応じて DR 構成を検討する。
ハードウェアをサイジングする¶
▼ CPU / メモリをサイジングする¶
性能目標値に基づいて、Node のスペック/数を適切に選び、Cluster 全体の CPU / メモリをサイジングする。
ロードテストを実施して、実地的な状況 (例:平常時、ピーク時、障害時) な負荷を再現し、性能目標を達成できるかを検証する。
- 平均スループット
- 平均レスポンスタイム
- 平均ハードウェア使用率
- 時間当たり平均トランザクション数
例えば、1 秒間に 50 人のユーザーからリクエスト (50 個/秒のリクエスト) があり、このときのレスポンスタイム目標値が 3 秒以内であるとする。
この場合、平均スループットの目標値は 50 (個/秒) 、平均レスポンスタイムの目標値は 3 秒以内、となる。
ロードテストの結果をメトリクスとして収集し、サイジングを最適化していく。
このとき、以下の設定値を調整し、Cluster 全体をサイジングする。
| Amazon EKS | Google Cloud GKE | |
|---|---|---|
| 適するアプリケーションのドメインやハードウェアの種類 | インスタンスファミリーで決まる | マシンファミリーで決まる。 |
| 同じインスタンスファミリー内での新しさ | インスタンス世代で決まる | マシンシリーズで決まる。 |
| CPU/メモリのスペックの高さ | インスタンスサイズインスタンス世代で決まる | マシンサイズで決まる。 |
| Nodeの数 | EC2 / Fargate の数で決まる。 | GKE Nodeの数で決まる。 |
| NodeにスケジューリングできるPodの上限数 | インスタンスサイズで決まる |
▼ ストレージをサイジングする¶
記入中...
適切な方法でアップグレードする¶
▼ 適切なアップグレードを採用する¶
アップグレード以下のいずれかを採用する。
| インプレース方式 | ローリング方式(サージ方式、ライブ方式) | NodeグループB/G方式(マイグレーション方式) | Cluster B/G方式(マイグレーション方式) | |
|---|---|---|---|---|
| 説明 | 新しくNodeは作成せずに、既存のNode内のK8sコンポーネントをそのままアップグレードする。既存のNodeを一定台数ごとに更新を実行するため、更新中はクラスタ全体のノードのキャパシティが少なくなる点に注意する。また、既存のNodeをアップデートしてしまうため、切り戻しが難しい点を認識しておく。 | アップグレード時に、Nodeグループに紐づくNodeテンプレートを更新し、旧Nodeグループ内のワーカーNodeを順にドレインしていくことにより、Nodeを入れ替える。クラウドプロバイダー (例:AWS、GCP) ではローリング方式をサポートしている場合がある。例えばAmazon EC2のAuto Scalingグループは、アップグレードを開始すると、新旧の起動テンプレートを更新する。新旧の起動テンプレート配下のEC2 Nodeを段階的に入れ替えることにより、ローリングアップグレードを実現する。GKE の場合は maxSurge と maxUnavailableを指定し、その設定に応じてローリングアップデートを実行する。 | 現K8sバージョンのNodeグループ (ブルー) を残したまま、新K8sバージョンのNodeグループ (グリーン) を作成する。ブルーのNodeグループをcordonし、Cluster Autoscalerなどのスケール対象からも外す。ブルーのNodeグループからグリーンのNodeグループにPodを移動する。ノードに対してdrainを実行したり、アプリケーションを再デプロイするなど、Podを移動する方法は複数ある。新Nodeグループで起動したPodにトラフィックが流れることで、開発者はコンテナの動作を確認する。問題なければ、現行Nodeグループを削除する。一方で、もし新Nodeグループで問題あれば、現Nodeグループをそのまま使用する。GKEにはNodeグループB/G方式をhttps://cloud.google.com/kubernetes-engine/docs/concepts/node-pool-upgrade-strategies?hl=ja#cluster-autoscaler-blue-greenがある。 | 現K8sバージョンのCluster (ブルー) を残したまま、新K8sバージョンのCluster (グリーン) を作成する。開発者は、新Cluster上のコンテナの動作を確認する。問題なければ、DNSやロードバランサーの振り分け先を新Clusterに切り替える。一方で、もし新Clusterで問題あれば、現Clusterをそのまま使用する。 |
| 採用可能なオーケストレーター(2023/10時点) | kubeadm | Amazon EKS、Google GKE | Amazon EKS、Google GKE | Amazon EKS、Google GKE |
| 金銭コスト | 既存のNodeをそのまま使用する。そのため、既存のコストと変わらない。 | 使用するマネージドサービスや、アップデート設定にもよるが、新Nodeを作成するような設定の場合は新Nodeを作成した後に旧Nodeをドレインするまでの間、Nodeの台数が増えることになるのでコストが多く発生することになる。そのため、アップグレードの際に増えるNode台数をあらかじめ計測しておきアップグレードにかかるコストについて見積もりをとっておくようにする。 | 新Nodeグループを作成することでNodeが二倍になる。そのため、金銭コスト見積もりでは各Nodeグループのアップグレードの間、平常時の2倍コストがかかることを想定しておく。 | 新Clusterを作成することでNodeが二倍になる。そのため、金銭コスト見積もりではクラスターアップグレードを実施~動作確認などを経て旧クラスター削除するまでの間、平常時の2倍コストがかかることを想定しておく。 |
| 切り戻ししやすさ | しにくい | しにくい | しやすい | しやすい |
▼ クラスターアップグレードのルールを決める¶
Kubernetes Cluster の規模や運用しているシステム、アップグレード方法によってはアップグレード時間が長くかかることもあれば、既存システムに影響がある可能性もある。
また、Kubernetes Cluster のバージョンアップによって既存の manifests を変更しなければ行けないケースも発生する。
そのため Kubernetes Cluster のアップグレードでは、どのようなルールやフローで実施するのかをルール化して実施することでアップグレードの安全性を高められる。
例えば下記のようなルールを盛り込んだアップグレードルールを作成する。
- クラスターアップグレードにあたっての準備
- クラスターアップグレード前に https://github.com/kubernetes/kubernetes/tree/master/CHANGELOG を確認し、(おおまかにでも)変更内容について確認する
- クラスターアップグレード前に廃止される API グループのバージョンを確認することで、変更が必要な既存の manifests を確認する
- あらかじめ検証環境で本番環境と(限りなく)同じ設定のクラスターのアップグレード~動作確認し、問題なくアップグレード可能かを検証する
- 監視ツールなどで廃止されるメトリクスを使用したクエリロジックがないかを確認する
- クラスターにインストールしてる各種 Helm Chart や Operator が対象のクラスターバージョンで正常に動作するか or サポートしているかを確認する
- クラスターバージョンのアップグレード戦略
- Kubernetes の「https://kubernetes.io/releases/version-skew-policy/#supported-component-upgrade-order」と「Kubernetes Release Versioning」に沿ったバージョンアップを実行する
- パッチバージョンのアップグレードについては CHANGELOG に基づいて修正されたバグの影響度に応じて実施する
- マイナーバージョンのアップグレードについては 1 バージョンずつアップグレードを実施する
- 約 4 ヶ月ごとのマイナーバージョンのリリースごとにマイナーバージョンのアップグレードを実施する or x ヶ月ごと(12 ヶ月以内)にそのタイミングの最新バージョンまでアップグレードを実施する
- ローリングアップグレードや B/G 方式などクラスターバージョンのアップグレード方法を決める
- アップグレード手順
- アップグレードの手順や動作確認方法、必要に応じてアップグレード完了後の旧クラスターの削除方法などをドキュメント化する
- また、アップグレードに失敗した際の切り戻し手順のドキュメント化を実行する
- アップグレード後の動作確認では Pod だけでなく Workload のコンディションとステータスを確認する
- クラスターにインストールしてる各種 Helm Chart や Operator などが正常に動作しているかを確認する
- クラスター側の設定
- コントロールプレーン Node でダウンタイムを発生させないために必要に応じて etcd と kube-apiserver の Pod に Pod Disruption Budget を設定する
- コントロールプレーンがマネージドな GKE や EKS などでは考慮不要
- コントロールプレーン Node でダウンタイムを発生させないために必要に応じて etcd と kube-apiserver の Pod に Pod Disruption Budget を設定する
コントロールプレーンNode¶
冗長化する¶
オンプレ環境などでコントロールプレーン Node を管理する必要がある場合、コントロールプレーン Node は 3 台以上に設定して冗長化を実行する。
ロードバランシングする¶
オンプレ環境などで kube-apiserver へのリクエストエンドポイントを手動で設定する必要がある場合、ロードバランサーを設定して kube-apiserver の Pod への負荷分散ができるようにする。
ロードバランサーには IP アドレスを付与して Kubernetes Cluster 内部と、Kubernetes Cluster のオペレーションが必要な IP アドレスからのリクエストを受け付けられるようにする。
冗長化された kube-apiserver に適切にインバウンドな通信を振り分けることにより、kube-apiserver の負荷を分散させる。
| パターン | コントロールプレーンNode外 配置パターン | コントロールプレーンNode内配置パターン |
|---|---|---|
| アクティブなルーティング先への仮想IPアドレスの割り当て | keep-alived | kube-vip |
| L4ロードバランサー | haproxy | kube-vip |
コントロールプレーンNodeを異なるトポロジーに分散させる¶
冗長化したコントロールプレーン Node を特定のトポロジー偏らせてに配置すると、その特定のトポロジーで障害が起こった場合に、コントロールプレーン Node が全滅してしまう。
そのため、例えばオンプレ環境であればコントロールプレーン Node を配置するサーバーをラック単位で分けて別の電源を確保しているトポロジーに分散させたり、クラウドの VM 環境で動作させる場合にはゾーンを分散させたり、マルチリージョンなデータセンターで Kubernetes Cluster を動作させる際にはリージョン単位でコントロールプレーン Node を分散配置させたりといった手法を取ることで冗長性を高めるようにする。
kube-apiserverへのインバウンド通信を制限する¶
kube-apiserver に対して、誰でもアクセスできてしまうことは危険である。
そのため、必要最低限の開発者のみがリクエストできるように、インバウンド通信を制限する。
- ファイアウォール
- kube-apiserver にリクエストを送信できる IP アドレスを制限する。
- 特定のサーバー (踏み台サーバー、リモートデスクトップのゲートウェイなど) からのみ、kube-apiserver へリクエストできるようにする。
- 認証
- 必要最低限の開発者にのみアカウントを発行する。このときに SSO の仕組みを採用し、kube-apiserver の認証を ID プロバイダー (例:Keycloak、Okta) に委譲すると、kube-apiserver で大量の UserAccount を管理する必要がなくなる。
ハードウェアをサイジングする¶
▼ ストレージをサイジングする¶
コントロールプレーンに etcd を作成する場合、etcd のディスクアクセスがクラスタ全体の性能や安全性に影響するため SSD を利用する。 ストレージ容量は最低限 40GiB 程度割り当てる。
Etcd¶
バックアップする¶
障害で Etcd 上のデータが損失することに備えて、Etcd を定期的にバックアップしておく。
冗長化する¶
etcd Node は 3 台に冗長化する。
高性能ストレージを利用する¶
Disk I/O は etcd の性能に直結するため、SSD など十分な IOPS を担保できるストレージを利用する。
RAIDのミラーリングやパリティを利用しない¶
etcd は Raft 合意アルゴリズムを利用しており、3 台以上のクラスタメンバーが高可用性を実現できるためストレージレイヤでの冗長化は行わない。
ワーカーNode¶
冗長化する¶
ワーカーNode は Pod の特性 (アプリ系、監視系、ロードバランサー系、バッチ系、サービスメッシュ系など) ごとに作成する。
また、ワーカーNode をグループ化し、Node グループごとに冗長化の程度を設計する。
Node グループの特徴に合った数だけ冗長化しつつ、N+1 にするとよい。
ここでは、Node グループの例をいくつか挙げる。
▼ Stateless / Stateful別¶
状態を持つ Pod とそうでない Pod を異なる Node グループ内で稼働させる。
| Stateless系(アプリ、バッチ、L7ロードバランサー、サービスメッシュなど) | Stateful系(例:DBなど) | |
|---|---|---|
▼ プロダクトのサブコンポーネント別¶
プロダクトの各サブコンポーネントの Pod を異なる Node グループ内で稼働させる。
| アプリ系 | バッチ系 | L7ロードバランサー系 | 監視系、サービスメッシュ系 | |
|---|---|---|---|---|
| 要件例 | アプリ系Nodeグループはユーザーに影響がある。 そのため、稼働時間を長くしたい。 | バッチ系Nodeグループはユーザーに影響がある。 そのため、稼働時間を長くしたい。 | ロードバランサー系Nodeグループは単一障害点となりユーザーに影響が大きい。 そのため、稼働時間はもっとも長くしたい。 | 監視系Nodeグループはユーザーに影響がない。 そのため、稼働時間を短くても問題ない。 |
| ⬇️ | ⬇️ | ⬇️ | ⬇️ | |
| Nodeの冗長化の程度 | Nodeを多く冗長化する。 | Nodeを多く冗長化する。 | Nodeをもっとも多く冗長化する。 | Nodeを少なく冗長化する。 |
オートスケーリング¶
IaaS 環境で Node 数をスケールさせられる環境では、動的に Node 数をスケールさせることで処理量の増加に対して柔軟に対応できるようになる。
Kubernetes では Node に対する動的なスケール手段として cluster autoscaler、Karpenter といったアプリケーションが用意されているため、これらを利用してオートスケーリングできるようにする。
適切なOS、CPUアーキテクチャを選ぶ¶
コントロールプレーン Node と重複するため、省略する。
ハードウェアをサイジングする¶
▼ CPU/メモリをサイジングする¶
Node グループ内の Pod 数や CPU/メモリ要求の特徴に合った量を割り当てる。
Cluster 全体に割り当てられたハードウェアリソースを適切に分配できるよう設計する。
(Node グループ例 1)
| Stateless系(アプリ、バッチ、L7ロードバランサーなど) | Stateful系(例:監視ツールなど) | |
|---|---|---|
(Node グループ例 2)
| アプリ系 | バッチ系 | L7ロードバランサー系 | 監視ツール系 | |
|---|---|---|---|---|
| Pod数の要件例 | アプリケーションの障害はユーザーに影響があるため、Podの冗長化の程度を他グループよりも大きくしたい。 | バッチの障害はユーザーに影響があるため、Podの冗長化の程度を他グループよりも大きくしたい。 | L7ロードバランサーは単一障害点になるため、Podの冗長化の程度をNodeグループ内でもっとも大きくしたい。 | 監視ツールの障害はユーザーに影響がないため、Podの冗長化の程度を他グループよりも小さくしたい。 |
| ハードウェアリソースの要件例 | アプリは恒常的にCPU/メモリを必要とする。 また、Nodeグループ当たりのPodの合計数が多い。 | バッチ系は瞬間的にCPU/メモリを必要とする。 また、Nodeグループ当たりのPodの合計数が多い。 | L7ロードバランサー系は恒常的にCPU/メモリを必要とする。 一方で、Nodeグループ当たりのPodの合計数が少ない | 監視ツールは恒常的にCPU/メモリを必要とする。 一方で、Nodeグループ当たりのPodの合計数が少ない。 |
| ⬇️ | ⬇️ | ⬇️ | ⬇️ | |
| 対処例 | アプリ系NodeグループにはCPU/メモリを他より多めに割り当てる。 | バッチ系Nodeグループには瞬間的な要求 (バースト) に適したCPU/メモリを選びつつ、多めに割り当てる。 AWSであればT系のインスタンスタイプが瞬間的な要求に適している。 | L7ロードバランサー系NodeグループにはCPU/メモリを他より多めに割り当てる。 | 監視ツール系NodeグループにはCPU/メモリを少なめに割り当てる。 |
▼ ストレージをサイジングする¶
Node グループにあったストレージを割り当てる。
例えば、ArgoCD がストレージに永続化するデータサイズは少ないため、ArgoCD の Node グループにはストレージはあまり必要ない。
一方で、Prometheus はメトリクスを Node のストレージに保管する (外部 TSDB を使用するにしても数日分は保管することになる)。
コントロールプレーンNodeとワーカーNodeで共通のプラクティス¶
異なるゾーンに分散させる¶
冗長化したコントロール Node とワーカーNode を特定のゾーンに配置すると、そのゾーンのデータセンターで障害が起こった場合に、Node が全滅してしまう。
異なるゾーンに分散させるように配置する。
適切なOS、CPUアーキテクチャを選ぶ¶
- OS は適切なの、くらいな表現になる
- CPU アーキテクチャ
- arm が安いから arm 使用する
- マルチプラットフォームビルドを避けられるなら避けたいので amd を使用するなど
- ベースイメージに arm 製が少ないから理由がなければ amd 使用する
Ingress¶
Ingressインバウンド通信を制限する¶
社内向けアプリケーションやテスト環境で、インバウンドな通信をすべて許可することは危険である。
Ingress Controller (例:Nginx Ingress Controller、AWS Load Balancer Controller、GCE L7 load Balancer Controller など) が提供する機能を使用して、インバウンド通信を制限する。
なお、Ingress のインバウンド通信を制限することはあっても、Egress のアウトバウンド通信を制限するとむしろ不便になるため、Egress のアウトバウンド通信はすべて許可しておく。
多くの Ingress Controller では、制限のルールを Ingress の .metadata.annotations キーに直接設定するか、Ingress から切り離して設定するか (例:ConfigMap、AWS WAF、CloudArmor) を選べる。
管理しやすいように、Ingress から切り離して設定するとよい。
IngressをSSL/TLS終端にする¶
Pod を SSL/TLS 終端にする場合、Cluster 内で HTTPS 通信を使用することになるため、さまざまな対処事項 (例:サーバー証明書管理、相互 TLS 認証の有無) で実装難易度が上がる。
仮にサービスメッシュを採用すれば対処しやすくなるが、採用しないのであれば自前での対処は大変である。
Ingress を SSL/TLS 終端にすると、Pod へは HTTP リクエストになってしまうが、Cluster 内の通信で対処事項が減るため、安全性と利便性を両立できる。
IngressClassの指定にingressClassNameを使用する¶
IngressClass の指定方法には、.spec.ingressClassName キーと .metadata.annotations.kubernetes.io/ingress.class キーがある。
.spec.ingressClassName キーの指定方法が推奨である。
CronJob¶
failedJobsHistoryLimitを設定する¶
CronJob で Job が失敗したとき、CronJob はデフォルトで過去 1 回分の失敗しか履歴に残さない。
トラブルシューティングしやすくするために、.spec.startingDeadlineSeconds キーで 3 回分以上を設定しておく。
startingDeadlineSecondsを設定する¶
CronJob のデフォルトの仕様として、Job が 100 回連続で失敗すると、CronJob を再作成しない限り Job を再実行できなくなる。
1 時間に Job を 1 回実行すると仮定すると、簡単に 100 回を超過してしまう。
停止時間 (8h) * 実行間隔 (60/h) = 480回
このとき、.spec.startingDeadlineSeconds キーを設定しておくと、これの期間に 100 回連続で失敗したときのみ、Job を再実行できなくなる。
100 回連続を判定する期間を短くすることで、再作成しなくてもよくなるようにする。
Job¶
ttlSecondsAfterFinishedを設定する¶
デフォルトでは、失敗した Job はそのまま残る。
ただ、監視ツールがこの失敗した Job のステータスをメトリクスとして収集し続けるため、アラートを発火し続けてしまう。
このとき、.spec.ttlSecondsAfterFinished キーを設定しておくと、Job の成功/失敗にかかわらず、実行後の Job 自体を自動的に削除できるようになる。
.spec.ttlSecondsAfterFinished キーには、Job の実行終了後に何秒経過してから Job 自体を削除するのかを設定する。
Pod¶
冗長化する¶
Workload (例:Deployment、DaemonSet、StatefulSet、Job など) で Pod を冗長化する。
N+1 個にするとよい。
水平スケーリングする¶
HorizontalPodAutoscaler で Pod を水平スケーリングする。
水平スケーリングは、Pod の負荷が高くなると Pod の台数を増やし、システム全体が高負荷で機能しなくなる状況を避けることができる。
ただし、突発的な高負荷には弱い。Pod の台数の増強が間に合わないこともある。
突発的な負荷のタイミングが事前にわかっているなら、事前に最小台数を高めに設定しておく。
HorizontalPodAutoscaler は、metrics-server の提供するメトリクス (例:CPU 使用率、メモリ使用率など) 、カスタムメトリクス、K8s 外のメトリクス (ロードバランサーの rps/qps 値、メッセージキューの待機リクエスト数など) 、に基づいて Pod 数を決める。
metrics-server はデフォルトで Cluster に存在していないため、別途インストールしておく必要がある。
最初、Deployment の spec.replicas キーに合わせて Pod が作成され、次に HorizontalPodAutoscaler の .spec.minReplicas キーが優先される。
この挙動は混乱につながるため、HorizontalPodAutoscaler を使用する場合、Deployment の spec.replicas キーの設定を削除しておくことが推奨である。
- https://github.com/kubernetes-sigs/metrics-server
- https://speakerdeck.com/hhiroshell/a-practical-guide-to-horizontal-autoscaling-in-kubernetes?slide=33
- https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/#migrating-deployments-and-statefulsets-to-horizontal-autoscaling
- https://stackoverflow.com/a/66431624/12771072
ロードバランシングする¶
L7のプロトコルの場合¶
冗長化したワーカーNode に負荷分散できるように、ワーカーNode の送信元に Ingress Controller の管理する L7 ロードバランサー (例:Nginx、Envoy、Istio Ingress Gateway、AWS ALB、Google CLB など) やこれに相当するもの (例:Gateway-API を使用しない Istio Ingress Gateway) を配置する。
L7 ロードバランサーが冗長化された Node に適切にインバウンドな通信を振り分ける。
L4のプロトコルの場合¶
冗長化した Pod に負荷分散できるように、Pod の送信元に L4 ロードバランサーとして Service を配置する。
Podのインバウンド通信を制限する¶
Pod のインバウンド通信をすべて許可することは危険である。
そのため、NetworkPolicy を用いて特定の Namespace 内の Pod に一括して通信の制限する。
ただし、Pod の通信に関するさまざまな要件が上がるたびに NetworkPolicy を変更するのは大変なため、採用するかどうかはプロダクトの方針による。
なお、Pod のインバウンド通信を制限することはあっても、アウトバウンド通信を制限するとむしろ不便になるため、アウトバウンド通信はすべて許可しておく。
DaemonSetやStatefulSet配下のPodのスケジューリング優先度を上げる¶
Node でハードウェアリソース不足が起こった場合、Node は一部の Pod を退避させてこれを解消しようとする。
このときに優先度を設定しないと、DaemonSet 配下の Pod のスケジューリング優先度が低くなる。
DaemonSet 配下の Pod は、各 Node の最低 1 つずつスケジューリングすることが望ましい。Node から DaemonSet 配下の Pod が退避させられると、障害が起こることもある。
また、StatefulSet 配下の Pod には状態を持たせることが多い。Node から StatefulSet 配下の Pod が退避させられると、書き込み中のデータが欠損することもある。
そこで、.spec.priorityClassName キーを使用すると、Pod のスケジューリング優先度を設定できる。
DeploymentやStatefulSetを使用する場合はPodDisruptionBudgetも合わせて作成する¶
Node のスケールインやアップグレード時に、Node はドレイン処理を実行し、古い Pod を退避させる。
このときに PodDisruptionBudget を作成しないと、Deployment や StatefulSet 配下の古い Pod が一斉に退避してしまう。
1 個でも古い Pod を動かすことで、ダウンタイムを避けるべきである。
そこで、PodDisruptionBudget を使用すると、Node のドレイン中に退避させる Pod の最小最大数 (spec.maxUnavailable キー、spec.minUnavailable キー) や起動し続ける利用可能な Pod の最小最大数 (spec.minAvailable キー,spec.maxAvailable キー) を設定できる。
Deploymentでは適切なデプロイ戦略をぶ¶
▼ 基本的にはRollingUpdate戦略を選ぶ¶
RollingUpdate 戦略では、既存の Pod を稼働させながら、新しい Pod をデプロイする。
新旧 Pod が並列的に稼働するため、クライアントからのリクエストを処理しながら、ダウンタイムなく Pod をデプロイできる。
ほとんどのユースケースで、RollingUpdate 戦略を選ぶようにする。
▼ 新旧Podが並列的に稼働することを許容しない場合はRecreate戦略を選ぶ¶
Recreate 戦略では、既存の Pod を削除した後、新しい Pod をデプロイする。
RollingUpdate 戦略では、デプロイ時に新旧 Pod が並列的に稼働するため、アプリケーションの仕様上で不都合がある場合に適さない。
そういったユースケースでは、Recreate 戦略を選ぶようにする。
Podを異なるNodeに分散させる / 特定のNodeにスケジューリングする¶
Workload 配下の Pod を異なる Node に分散させ、障害を防ぐ。
また、Node や Node グループを指定してスケジューリングさせる。
kube-scheduler は、Workload 配下の Pod を条件に応じて Node にスケジューリングする。
障害が起こった Node に Workload 配下の Pod が偏っていると、冗長化した Pod がすべて停止し、サービスに影響する可能性がある。
そのため、Pod が特定の Node へ偏らないようにする。
なお、以降の設定値は Pod のスケジューリング時にのみ考慮される。
スケジューリング後に条件と合致しなくなっても、kube-schedule は Pod を再スケジューリングしない。
例えば、一時的な負荷で Pod がスケールアウトした場合を考える。
Pod をスケジューリングするときは、条件を考慮して Pod を分散して配置する。
しかし、一時的な負荷が収まって Pod がスケールインするときは、条件を考慮して Pod を削除するわけではない。
そのため、Pod の分散配置が保証されなくなる。
Node にスケジュール後の Pod を定期的に再スケジューリングするために、descheduler を合わせて使用するとよい。
descheduler は条件に一致しない Pod を退避させるだけで、Pod の再スケジューリングは kube-scheduler が実行する。
▼ NodeSelectorを使用する¶
NodeSelector を使用すると、Workload 配下の Pod を指定した Node や Node グループにスケジューリングさせ、Pod を分散させられる。
Node や Node グループを単純な条件 (例:Node のラベルと値の有無) で指定できる。
▼ NodeAffinityを使用する¶
NodeAffinity を使用すると、Workload 配下の Pod を指定した Node や Node グループにスケジューリングさせ、Pod を分散させられる。
Node や Node グループを NodeSelector よりも複雑な条件 (例:Node のラベル自体の有無、Node のラベル値の有無) で指定できる。
▼ TopologySpreadConstraintsを使用する¶
TopologySpreadConstraints を使用すると、ドメイン (例 ゾーン、リージョン、ラック、Node) と制約を定義することで、Workload 配下の Pod をドメインに対して均等に分散できる。
NodeSelector や NodeAffinity とは異なり、特定のドメインに Pod が偏らないようにすることで、障害の影響を一部のドメイン内の Pod に抑えることができる。
▼ TaintsとTolerationsを使用する¶
Taints と Tolerations を使用すると、指定した条件に合致する Pod 以外を Node にスケジューリングさせないようにできる。
例えば、Workload が少ない Node グループ (monitoring、ingress など) に Taint を設定し、Workload が多い Node グループ (app、system など) にはこれを設定しないようにする。
すると、.spec.tolerations キーを設定しない限り、Pod が多い Node グループのほうに Pod がスケジューリングされる。
そのため、NodeSelector や NodeAffinity を使用するより、スケジューリング対象の Node を設定する手間が省ける。
以下の方法で設定する。
事前に Node へ Taint を設定しておく。
$ kubectl taint node foo-node group=monitoring:NoSchedule
## NodeグループやNodeプールがある場合、一括してTaintを設定する
Taint への耐性を .spec.tolerations キーで設定する。
合致する条件の .spec.tolerations キーを持つ Pod しか、Taint を持つ Node にスケジューリングさせられない。
apiVersion: v1
kind: Pod
metadata:
name: prometheus
spec:
containers:
- name: prometheus
image: prom/prometheus
imagePullPolicy: IfNotPresent
## Taintへの耐性をtolerationsで定義する
tolerations:
- key: group
operator: Equal
value: monitoring
effect: NoSchedule
適切なストレージの種類を選ぶ¶
▼ 大規模な一時的ストレージを必要とする場合はGeneric Ephemeral Volumesを使用する¶
Generic Ephemeral Volumes を使用して、Pod のデータを K8s 外部のストレージ (例:AWS EBS) に一時的に保管できる。
大量の一時的な中間データを保管したい場合 (例:画像処理中間データ、音声処理中間データなど) に役立つ。
一時的なストレージのため、Pod の作成時にストレージを払い出し、Pod が停止するとストレージは削除される。
EmptyDir Volume とは異なり、Node のストレージが Pod の容量を制限しない。
そのため、Node 外ストレージの容量次第では、一時的に保管できるデータサイズが EmptyDir よりも多い。
一方で、Node 外ストレージを追加で使用することになるため、金銭的コストが EmptyDir よりも大きい。
▼ 小規模な一時的ストレージを必要とする場合はEmptyDir Volumeを使用する¶
EmptyDir Volume を使用して、Pod のデータを Node のストレージに一時的に保管できる。
少量の一時的な中間データを保管したい場合 (例:キャッシュの保管、バッファリングなど) に役立つ。
Generic Ephemeral Volume とは異なり、Node のストレージが Pod の容量を制限する。
そのため、Node のストレージ次第では、一時的に保管できるデータサイズが Ephemeral Volumes よりも少ない。
一方で、Node のストレージをそのまま使用することになるため、金銭的コストが Ephemeral Volumes よりも小さい。
Pod のリソース要求やリソース制限に ephemeral-storage のフィールドを追加して、利用するディスク容量を制限できる。
これにより、scheduler が Node のストレージのキャパシティを考慮して Pod を配置してくれる。
また、リソース制限で指定した ephemeral-storage を超えてディスク容量を使用した場合に、その Pod は退避されて再起動する。
▼ 永続的ストレージを必要とする場合はPersistentVolume (Claim) を使用する¶
PersistentVolume (Claim) を使用することで特定のストレージ製品のボリュームに Pod のデータを永続化できる。
使用できるストレージ製品はクラスターのインストールされたボリュームプラグイン (≒ CSI Driver) と実行環境に依存しており、そのプラグインを使用する StorageClass
して、Pod のデータを Node のストレージに永続的に保管できる。
StorageClass による Node 外ストレージとは異なり、Node のストレージが Pod の容量を制限する。
そのため、Node のストレージ次第では、永続的に保管できるデータサイズが PersistentVolume よりも少ない。
▼ 大規模な永続的ストレージを必要とする場合はStorageClassによるNode外ストレージを使用する¶
StorageClass による K8s 外部のストレージ (例:AWS EBS) を使用して、Pod のデータを Node 外ストレージに永続的に保管できる。
StorageClass では、Node のストレージが Pod の容量を制限しない。
そのため、Node 外ストレージの容量次第では、一時的に保管できるデータサイズが PersistentVolume よりも多い。
適切なボリュームアクセスモードを選択する¶
▼ 独自ファイルシステムやファイルのロックが影響する場合は .spec.accessMode=ReadWriteOnce を割り当てる¶
1 つの Node に対して読み込み/書き込みが可能なボリュームとしてマウントする。
もし Node に Pod のインスタンスが複数ある場合、ReadWriteOnce であっても複数の Pod から読み込み/書き込みがある。
ロックのあるストレージの場合、Node ごとにストレージを分割しつつ、Node に 1 つだけスケジューリングされるようにした Pod がストレージを占有したほうがよい。
- 例 DB
▼ 複数Node/Pod間でファイルを共有するアプリケーションには .spec.accessMode=ReadWriteMany を割り当てる¶
複数のノードから読み込み/書き込みを行えるボリュームとしてマウントする。
ファイルシステムでは、Node 間でストレージを共有したほうがよい。
- 例 NFS、SMB
▼ 複数Node/Pod間でReadのみを許可するアプリケーションには .spec.accessMode=ReadOnlyMany を割り当てる¶
複数のノードから読み込みのみを行えるボリュームとしてマウントする。
ConfigMap に保管するには大きすぎる設定ファイルや共通データでは、Node 間で読み込みストレージを共有したほうがよい。
- 例 機械学習モデルのパラメータストア
ラベルを利用して目的に合ったストレージを選択する¶
アプリケーションによってストレージに求める性能は異なるため、利用用途に合わせて適したスペックのストレージを割り当てる必要がある。
そこでストレージクラスや PersistentVolume のラベルに .metadata.label.storage-type=ssd のようにストレージの種類などを設定し、spec.selector.matchLabels: storage-type: ssdのように指定することで利用用途に合ったストレージを選択できる。
利用用途に合ったReclaim Policyを設定する¶
▼ 特別な理由がない限りDeleteを指定する¶
Kubernetes のデフォルトでは Reclaim Policy が Delete に指定されている。
Delete を指定することで PersistentVolumeClaim(PersistentVolumeClaim)を削除し PersistentVolume(PV)が使用されなくなった時点で自動削除され、PV の管理負荷を削減できるため Reclaim Policy は原則 Delete を利用する。
▼ 重要なデータを含むPersistentVolumeClaimはRetainを指定する¶
DB やファイルストレージ用途などで PersistentVolumeClaim を利用している場合、誤った PersistentVolumeClaim の削除によるデータ損失を防ぐ必要がある。
そのため重要なデータを保管する PersistentVolumeClaim は Reclaim Policy に Retain を指定し、PV が完全に削除されないよう保護できる。
▼ RecycleポリシーではなくDynamic Provisioningを利用する¶
現在 Recycle ポリシーは Deprecated されている。
そのため PersistentVolumeClaim のみ削除し、PV は削除しないようなユースケースでは Dynamic Provisioning を利用する。
ストレージをPodと同じNodeに作成する¶
Node を冗長化している場合、Workload は配下の Pod を各 Node にスケジューリングされるため Pod がアクセスするストレージも同様の Node に作成する必要がある。
ストレージが Pod と異なる Node に作成された場合、ほか Node の障害によりストレージを利用できなくなり Node を超えて障害が伝搬してしまう。
そこで topologySpreadConstraints キーを使用することで、Pod と同じ Node にストレージをスケジューリングできる。
StorageClassやPersistentVolumeに適切なラベルを設定する¶
Pod から PersistentVolumeClaim を利用する場合ラベルなどがついていないと、適切なボリューム選択が困難になってしまう。
そのため StorageClass や PersistentVolume の metadata.label に storage-type=ssd や iops=3000、environment=prd などストレージ性能や環境などボリューム選択に利用できるラベルを設定する。
Pod内のコンテナとホスト (Node) のネットワーク名前空間を分離する¶
▼ hostIPCを無効化する¶
Pod の .spec.hostIPC キー有効化すると、Pod 内のコンテナのホスト (Node) 間で同じ IPC 名前空間を使用するようになる。
コンテナのプロセスは、同じ IPC 名前空間に属する任意のプロセスと通信できるようになる。
ただし、悪意のある人がコンテナに接続した場合、Node のほかのプロセスにリクエストできてしまう。
そのため、無効化しておく。
▼ hostPIDを無効化する¶
Pod の .spec.hostPID キー有効化すると、コンテナと Node 間で同じ PID 名前空間を使用するようになる。
Node とコンテナのプロセス ID が同じになるため、コンテナは Node のプロセスを操作できるようになる。
つまり、悪意のある人がコンテナに接続した場合、Node のプロセスを操作できてしまう。
そのため、無効化しておく。
コンテナ¶
ヘルスチェックを設定する¶
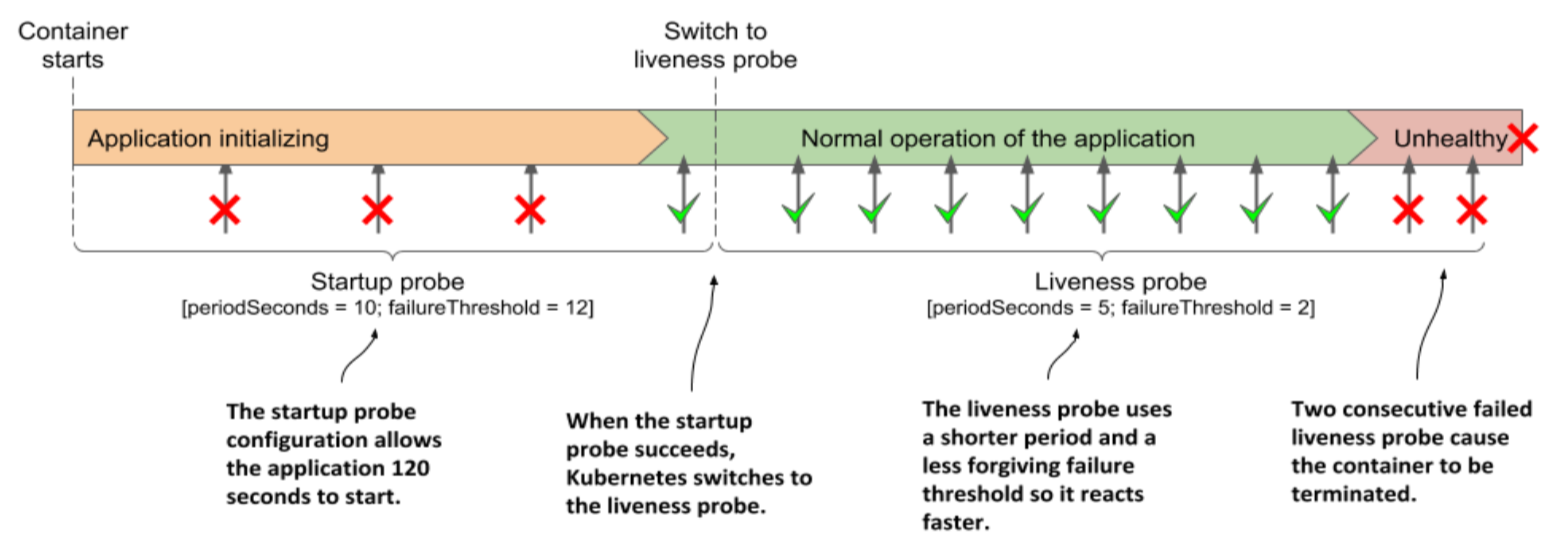
kubelet は、コンテナをヘルスチェック (例:StartupProbe ➡️ LivenessProbe/ReadinessProbe) し、障害を防ぐ。
LivenessProbe ヘルスチェックと ReadinessProbe ヘルスチェックの間に順番はなく、独立して実行される。
言語やフレームワークによっては StartupProbe 用のエンドポイントが提供されていない場合があり、ReadinessProbe ヘルスチェック用のエンドポイントを StartupProbe ヘルスチェックの対象として代用する。
| StartupProbeヘルスチェック | LivenessProbeヘルスチェック | ReadinessProbeヘルスチェック | ||
|---|---|---|---|---|
| 説明 | ヘルスチェックを実行することで、コンテナ内のアプリケーションの起動が完了したかを確認する。ReadinessProbeよりも先に実行される。ReadinessProbeと違って起動時にしか実行されない。 | ➡️ | ヘルスチェックを実行することで、コンテナが正常に動作しているか確認する。 注意点として、LivenessProbeヘルスチェックの間隔が短すぎると、kubeletに必要以上に負荷がかかる。 | ヘルスチェックを実行することで、コンテナがトラフィックを処理可能かを確認する。 コンテナが起動してもトラフィックを処理できるようになるまでに時間がかかる場合や、問題の起きたコンテナにトラフィックを流さないようにする場合に役立つ。注意点として、ReadinessProbeの間隔が短すぎると、kubeletに必要以上に負荷がかかる。 |
| エンドポイント例 | ・SpringBoot製のJavaアプリなら /actuator/startup を使用する。・NginxならReadiness用のエンドポイントで代用する。 |
➡️ | ・SpringBoot製のJavaアプリなら /actuator/health/liveness を使用する。・Nginxなら 200 ステータスを返却するだけの /healthcheck を定義する。 |
・SpringBoot製のJavaアプリなら /actuator/health/readiness (ウォームアップ実施エンドポイント) を使用する。・Nginxなら /nginx-ready (設定ファイル読み込み状態エンドポイント) を使用する。・MySQLなら接続受信準備完了エンドポイントを使用する。 |
| 正常とき | LivenessProbe/ReadinessProbeヘルスチェックを実行する。 | ➡️ | HTTP リクエストの場合、コンテナのヘルスチェックエンドポイントが 200 ステータスから 399 ステータスまでを返却すれば正常とみなす。 |
HTTP リクエストの場合、コンテナのヘルスチェックエンドポイントが 200 から 399 ステータスを返却すれば正常とみなす。 |
| 異常とき | コンテナを再起動する。LivenessProbe/ReadinessProbeヘルスチェックを実行しない。 | ➡️ | コンテナを再起動する。コンテナで障害 (例:デッドロック) が起こって応答しなくなると、コンテナを強制的に再起動してくれる。 | コンテナのプロセスの準備が完了しない間、そのコンテナが処理できるようになるまで、ServiceからPodに通信を流さないようにしてくれる。コンテナは再起動しない。 |
- https://srcco.de/posts/kubernetes-liveness-probes-are-dangerous.html
- https://stackoverflow.com/questions/42567475/docker-compose-check-if-mysql-connection-is-ready
- https://docs.nginx.com/nginx-ingress-controller/configuration/global-configuration/command-line-arguments/#-ready-status
- https://speakerdeck.com/hhiroshell/jvm-on-kubernetes?slide=48
- https://speakerdeck.com/hhiroshell/jvm-on-kubernetes?slide=49
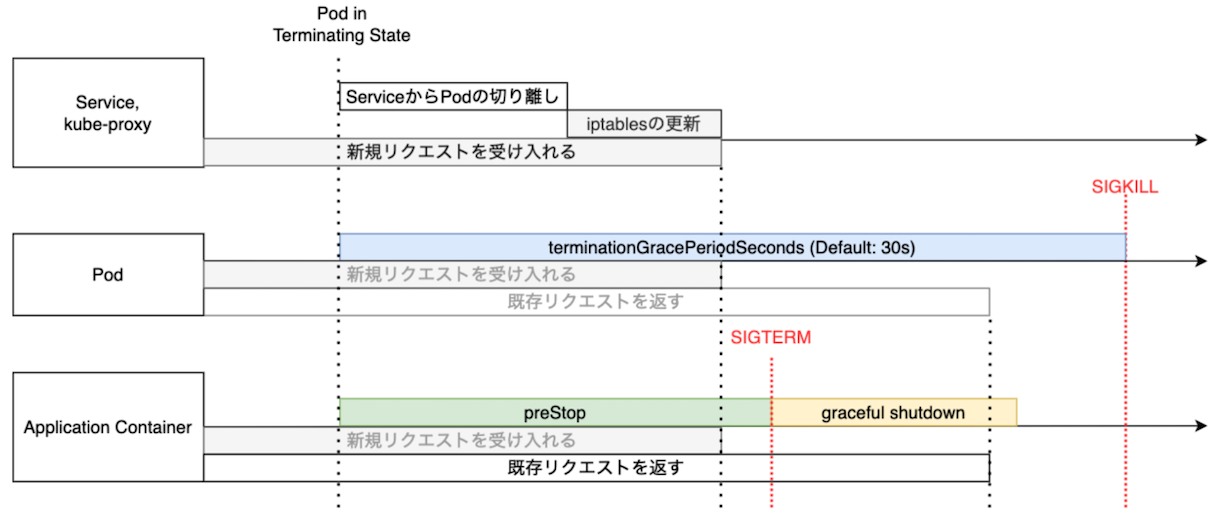
preStopとterminationGracePeriodSecondsを組み合わせてPodをGraceful Shutdownする¶
kubelet により、Pod の終了プロセスが始まると、以下の一連のプロセスも開始する。
- Workload (例:Deployment、StatefulSet など) が古い Pod を切り離す。
- Service と kube-proxy が古い Pod の宛先情報を削除する。
- コンテナを停止する。
これらのプロセスはそれぞれ独立して実施され、ユーザーは制御できない。
例えば、Service と kube-proxy が Pod の宛先情報を削除する前に Pod が終了してしまうと、Service から Pod への接続を途中で切断することになってしまう。
また、コンテナを停止する前に Pod を終了してしまうと、コンテナを強制的に終了することになり、ログにエラーが出力されてしまう。
- Service と kube-proxy の処理後に Pod を終了できるように、ユーザーが Pod の
.spec.terminationGracePeriodSecondsキーに任意の秒数を設定し、Pod の削除に伴う Service と kube-proxy の処理の完了を待機する必要がある。 - コンテナの正常な終了後に Pod を終了できるように、ユーザーが Pod の
.spec.containers[*].lifecycle.preStopキーに任意の秒数を設定し、コンテナに待機処理 (例:sleepコマンド) を実行させる必要がある。
なお、.spec.terminationGracePeriodSeconds の秒数が長すぎると Pod の終了に時間がかかりすぎるようになり、Pod の更新や Cluster のアップグレードの時間にも影響が出る。
長くとも 120 秒以内にするとよい。
Cluster DNS に対する無駄な名前解決のリクエストを減らす¶
Cluster DNS として CoreDNS などを利用している場合、無駄な名前解決のリクエストを減らすことで名前解決の安定性の向上や性能を改善できる。
Cluster 外へのリクエストでは、ドメインの末尾にドットをつける。
○: www.google.com.
×: www.google.com
完全修飾ドメイン名であることを宣言できるため、コンテナはそのドメインをそのまま名前解決しようとする。
これにより、DNS の検索パスを補間しなくなるため、名前解決の無駄なリクエストが発生しない。
別の方法として、/etc/resolv.conf ファイルの ndots 値を 1 に変更してもよい。
デフォルトでは、コンテナの /etc/resolv.conf ファイルには、ndots:5 が設定されている。
nameserver 172.20.0.10
search foo.svc.cluster.local svc.cluster.local cluster.local
options ndots:5
これにより、ドメインのドット数が 5 未満の場合は、Cluster 内で名前解決するしようとする。
しかし、Cluster 外へしかリクエストを送信しないコンテナでは、Cluster 内で名前解決する必要はない。
そういったコンテナの Pod では、Pod DNS Config の .spec.dnsConfig.options キーで ndots を 1 にし、ドット数が 1 未満の場合 (つまりドットが 1 個でもあれば) 、Cluster 外で名前解決するさせるようにする。
apiVersion: v1
kind: Pod
metadata:
namespace: default
name: foo
spec:
...
dnsConfig:
options:
- name: ndots
value: 1
前述の 2 つの対策を講じても Cluster DNS に必要以上の負荷がかかったり、ノード上の conntrack テーブルが溢れるなどの問題がある場合、NodeLocal DNSCache の採用を検討する。
Pod は、Cluster DNS に名前解決のリクエストを送信する前に、一度 NodeLocal DNSCache にリクエストを送信する。
このとき、名前解決のキャッシュがあると、Cluster DNS にリクエストを送信せずに名前解決できる。
機密性の高い情報を守る¶
▼ env変数やConfigMapに機密性の高い情報を設定しない¶
ConfigMap や Secret 上のファイルやデータを、コンテナにファイルや環境変数として渡せる。
このとき、ConfigMap では情報を平文で保持することになる。
機密性の高い情報を保持することは危険であり、Secret で保持するほうがよい。
▼ Secretの元データはSecretストアで暗号化して管理する¶
Secret は、base64 方式のエンコード値を保持する。
これの元データを平文のまま管理することは危険なため、Secret ストアに管理するほうがよい。
また、暗号化キーを使って暗号化したうえで、Secret ストアで管理する。
| リポジトリ + キーバリュー型ストア | リポジトリ + クラウドキーバリュー型ストア | |
|---|---|---|
| バージョン管理 | 管理できる。 | 管理できない。 |
| 暗号化 | base64方式エンコード値を暗号化キー (例:AWS KMS、Google Cloud CKM、GnuPG、PGPなど) で暗号化する。 | base64方式エンコード値を暗号化キー (例:AWS KMS、Google Cloud CKM、GnuPG、PGPなど) で暗号化する。 |
| Secretストア | リポジトリ上でキーバリュー型ストア (例:SOPS、kubesec、Hashicorp Vault) で管理する。 Apply時にbase64方式エンコード値に復号する。 | クラウドプロバイダー内のキーバリュー型ストア (例:AWS パラメーターストア、Google Cloud Secret Managerなど) で管理する。 Apply時に、ストア仲介ツール (例:SecretsStoreCSIDriver、External SecretsOperator) を使用してSecretのデータを取得しつつ、base64方式エンコード値に復号する。 |
コンテナイメージのタグにlatestを設定しない¶
コンテナイメージのタグに latest を指定すると、むやみに新しいバージョンのコンテナイメージのタグをプルしてしまい、障害が起こりかねない。
そこで、コンテナイメージはセマンティックバージョニングでタグ付けし、特定のバージョンをプルする。
なお、各コンテナイメージのアーキテクチャに割り当てられたダイジェスト値を指定できるが、K8s が Node の CPU アーキテクチャに基づいてよしなに選んでくれるため、ダイジェスト値は指定しない。
コンテナイメージが更新された場合のみコンテナイメージレジストリからプルする¶
コンテナ作成のたびにコンテナイメージをプルすると、コンテナイメージレジストリに負荷がかかる。
K8s で、一度プルしたコンテナイメージを基本的に削除しないため、キャッシュとして再利用できる。
.spec.containers[*].imagePullPolicy キーに IfNotPresent を使用し、Node 上にコンテナイメージのキャッシュがない場合のみプルできるようにする。
もし、キャッシュを使用せずにコンテナイメージをプルしたい場合、一時的に .spec.containers[*].Always キーを使用する。
Nodeに永続データを持たせない¶
StatefulSet を使用して Node に永続データを持たせた場合、Node の障害が永続データにも影響を与えかねない。
そこで、Node に永続データを持たせずに、外部のサーバー (例:Amazon RDS、MySQL) を使用する。
コンテナにセッションデータを持たせない¶
StatefulSet を使用してコンテナにセッションデータを持たせた場合、以下が起こると、コンテナが入れ替わってコンテナ上のセッションデータを削除してしまう。
- Pod が再起動する
- Pod が更新される
- Pod がスケーリングする
- ワーカーNode が再起動する
- …
セッションデータがなくなると、セッションを途中で維持できなくなってしまう。
そこで、コンテナにセッションデータを持たせずに、外部のセッションストレージツール (例:Amazon ElastiCache、Redis) を使用する。
コンテナが入れ替わっても、セッションストレージツールからセッションデータを取得できるようにする。
コンテナのCPU/メモリの性能チューニング¶
CPU/メモリの割り当て方法¶
▼ 仕組み¶
kube-scaduler は、コンテナの下限 (.spec.containers[*].resources.requests) 値以上の余剰がある Node に、Pod をスケジューリングする。
CPU の場合、上限値 (.spec.containers[cpu].resources.limits) が Node の余剰分を超過していると、コンテナは Node の余剰分を使用して稼働し続ける。
一方でメモリの場合、上限値 (.spec.containers[memory].resources.limits) が Node の余剰分を超過していると、コンテナは OOM Killed を起こし、再起動される。
▼ 算出¶
Pod 内のコンテナが要求する合計 CPU/メモリに見合った CPU/メモリを割り当てる。
また、Node の CPU/メモリの割り当てに関係するため、Pod の合計数や Pod 当たりの CPU/メモリ要求量を算出しておく。
なお LimitRange を使用すれば、.spec.containers[*].resources キー配下に設定がなくとも、コンテナの実行時に自動的に挿入してくれる。
ハードウェアリソース要求量の上限下限値を設定する¶
ハードウェアリソース要求量の上限値 (.spec.containers[*].resources.limits) / 下限値 (.spec.containers[*].resources.requests) を設定しないと、コンテナはハードウェアリソースを自由に要求してしまい、Node のハードウェアリソース不足になりかねない。
.spec.containers[*].resources キーを使用すれば、コンテナのハードウェアリソース要求量の上限下限値を設定できる。
なお、コンテナの特性に合わせて、上限下限値を設定するとよい。
▼ ハードウェアリソースを恒常的に要求する場合はGuaranteed QoSにする¶
ハードウェアリソースを恒常的に要求し、継続的に稼働させたいコンテナ (例:アプリ) では、Guaranteed QoS にする。
Guaranteed QoS では、上限 (.spec.containers[*].resources.limits) = 下限 (.spec.containers[*].resources.requests) のように、CPU とメモリを設定する。
上限 (.spec.containers[*].resources.limits) と下限 (.spec.containers[*].resources.requests) の設定の両方または一方を省略すると、自動的に Guaranteed になる。
コンテナが一定量のハードウェアリソースを要求し続けたとしても、無制限 (Node の空きリソース分) のハードウェアリソースを提供し、要求を満たせるようにする。
基本的には、ほとんどのコンテナを Guaranteed QoS にすればよい。
補足として、Guaranteed QoS の Pod はスケジューリングの優先度がもっとも高い。Node-pressure Eviction が発生した場合には、他の QoS (Burstable、BestEffort) よりも後に退避する。
▼ ハードウェアリソースを瞬間的に要求する場合はBurstableなQoSにする¶
ハードウェアリソースを瞬間的に要求し、一時的に稼働させたいコンテナ (例:バッチ、起動時に特にハードウェアを要求する JVM) では、Burstable な QoS にする。
Guaranteed QoS では、上限 (.spec.containers[*].resources.limits) > 下限 (.spec.containers[*].resources.requests) のように、CPU とメモリを設定する。
上限 (.spec.containers[*].resources.limits) を設定しないと上限が無制限になるため、下限 (.spec.containers[*].resources.requests) のみを設定した場合も Burstable である。
コンテナがハードウェアリソース要求量を瞬間的に上昇させても、対応できるようにする。
すべてのコンテナを Guaranteed QoS にするとハードウェアのコストが高くなるため、部分的に Burstable な QoS にするとよい。
ただし、上限 (.spec.containers[*].resources.limits) を高くしすぎると、割り当て可能な全体量を超えてしまう (オーバーコミットする) ため、上限は慎重に設定する。
補足として、Burstable な QoS の Pod はスケジューリングの優先度が Guaranteed の次に高く、Node-pressure Eviction が発生した場合には、Guaranteed の次に退避する。
設計例
Grafana ダッシュボードから、このシステムでは CPU とメモリの使用量に平常時とピーク時があるとわかる。
| CPU | メモリ | |
|---|---|---|
| requests | 平常時くらいのコア数にする。 | 平常時くらいのメモリ量にする。 |
| limits | ここ一週間の負荷ピーク時は多めに見積もって 0.9 コアである。ピーク時にも 70%くらいになるコア数にする。 |
ここ一週間の負荷ピーク時は多めに見積もって 1.2GiBである。ピーク時にも 70%くらいになるメモリ量にする。 |
▼ CPUの上限を設定しないBurstableなQoSにする¶
CPU の上限 (.spec.containers[*].resources.limits) だけは設定しないようにし、Burstable な QoS にする方法もある。
ただ、上限を設定したほうが監視しやすく、エラーの原因もわかりやすいため、CPU の上限も設定がおすすめである。
上限下限値を適切に設定する¶
上限下限値の差が大きいほどオーバーコミットが起こりやすいが、リソース効率は高くなる。
上限下限値の差が小さいほどオーバーコミットが起こりにくいが、リソース効率は低くなる。
InitContainerを適切に使用する¶
▼ InitContainerを適切な順番で起動させる¶
InitContainer が複数個ある場合、定義した順番に起動する。
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: app
image: app:1.0.0
ports:
- containerPort: 8080
volumeMounts:
- name: app-volume
mountPath: /go/src
initContainers:
- name: init-1
...
- name: init-2
...
$ kubectl get pod -o "custom-columns=" \
"NAME:.metadata.name," \
"INIT:.spec.initContainers[*].name," \
"CONTAINERS:.spec.containers[*].name"
# 定義した順番 (init-1、init-2) で起動する
NAME INIT CONTAINERS
app-***** init-1,init-2 app
▼ InitContainerで依存先コンテナの起動開始を待機する¶
依存先コンテナ (例:DB コンテナ、インメモリ DB コンテナ) の起動完了を待機する。
*実行例*
DB コンテナ (例:MySQL) が起動するために時間が必要であり、app コンテナではそれを待機可能にする。
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: app
image: app:1.0.0
ports:
- containerPort: 8080
volumeMounts:
- name: app-volume
mountPath: /go/src
initContainers:
- name: readiness-check-db
image: busybox:1.28
# StatefulSetのDBコンテナの3306番ポートに通信できるまで、本Podのappコンテナの起動開始を待機する。
# StatefulSetでReadinessProbeヘルスチェックを設定しておけば、これのPodがREADYになるまでncコマンドは成功しないようになる。
command:
- /bin/bash
- -c
args:
- |
until nc -z db 3306; do
echo waiting for db;
sleep 2;
done
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: foo-db
image: mysql:8.0
ports:
- containerPort: 3306
volumeMounts:
- name: foo-db-volume
mountPath: /var/lib
volumes:
- name: foo-db-volume
emptyDir: {}
*実行例*
インメモリ DB コンテナ (例:Redis) が起動するために時間が必要であり、app コンテナではそれを待機可能にする。
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: app
image: app:1.0.0
ports:
- containerPort: 8080
volumeMounts:
- name: app-volume
mountPath: /go/src
initContainers:
- name: readiness-check-redis
image: busybox:1.28
# StatefulSetのインメモリDBコンテナの6379番ポートに通信できるまで、本Podのappコンテナの起動開始を待機する。
# StatefulSetでReadinessProbeヘルスチェックを設定しておけば、これのPodがREADYになるまでncコマンドは成功しないようになる。
command:
- /bin/bash
- -c
args:
- |
until nc -z inmemory-db 6379; do
echo waiting for inmemory-db;
sleep 2;
done
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: foo-db
image: redis:8.0
ports:
- containerPort: 6379
volumeMounts:
- name: foo-inmemory-db-volume
mountPath: /var/lib
volumes:
- name: foo-inmemory-db-volume
emptyDir: {}
▼ InitContainerで依存ツールやSSLs用名所をインストールする¶
*実行例*
app コンテナから HTTPS リクエストを送信する場合に、サーバー証明書が必要になる。
これはすでに署名されている必要があり、例えば ubuntu では、CA 証明書 (CA 証明書) を含む ca-certificates パッケージをインストールする。
すると、/etc/ssl ディレクトリ配下に CA 証明書に関する一連のファイルがインストールされる。
これを、共有 Volume を介して、app コンテナにマウントする。
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: app
image: app:1.0.0
ports:
- containerPort: 8080
volumeMounts:
- name: app-volume
mountPath: /go/src
- name: certificate-volume
mountPath: /etc/ssl
initContainers:
- name: certificate-installer
image: ubuntu:22.04
command:
- /bin/sh
- -c
args:
- |
apt-get update -y
# CA証明書をインストールする
apt-get install -y ca-certificates
# 証明書を更新する
update-ca-certificates
volumeMounts:
- mountPath: /etc/ssl
name: certificate
volumes:
- name: certificate
emptyDir: {}
▼ InitContainerで初期データをDBに挿入する¶
記入中...
▼ どうしても特権コンテナが必要ならInitContainerを使用する¶
istio-init コンテナとかまさにその例
▼ InitContainerでサーバー証明書を準備する¶
記入中...
コンテナのストレージの性能チューニング¶
記入中...
Podとコンテナで共通のプラクティス¶
securityContextを適切に使い分ける¶
▼ PodとコンテナのsecurityContextを使い分ける¶
securityContext キーは、Pod とコンテナのいずれかまたは両方に設定できるキーを持つ。
特に Pod に設定できるキーは、Pod 内のすべてのコンテナに同じ設定を適用する。
| 両方 | Podのみ | コンテナのみ | |
|---|---|---|---|
| キー | runAsUser、runAsGroup、runAsNonRoot、seLinuxOptions、seccompProfileなど | fsGroup、fsGroupChangePolicyなど | privileged、allowPrivilegeEscalation、readOnlyRootFilesystem |
▼ runAsNonRoot、runAsUser / runAsGroupを使用して、非rootユーザーでコンテナを実行する¶
コンテナはホスト (Node) と各 namespace を分離しており、Capability を制限したうえで実行する。
しかし、Kubernetes では諸々の理由により、1.28 時点で namespace のうち user namespace をデフォルトで分離しない実装になっている (なお、Docker ではデフォルトで無効)。
そのため、Node とコンテナの User ID や Group ID のマッピングは同じになっている。
コンテナを root ユーザーで実行すると、コンテナブレイクアウトのサイバー攻撃を受ける可能性が高くなる。
例えば、コンテナを root ユーザーで実行している状況で、コンテナの runC (OCI ランタイムの一種) の脆弱性を突かれると、コンテナが Node の root ユーザーを操作できてしまう
よって、コンテナブレイクアウトの攻撃の可能性を小さくするために、できるだけコンテナを root ユーザーで実行しないほうがよい。
そこで、.securityContext.runAsNonRoot キーを有効化し、非 root ユーザーでコンテナを実行する。
さらに、.securityContext.runAsUser キーと .securityContext.runAsGroup キーで、使用する実行ユーザーの UID と GID を指定するようにしておく。
なお、Dockerfile の USER や GROUP でも同様に UID と GID を設定できる。しかし、マニフェスト側でも Dockerfile と同様に runAsUser と runAsGroup を設定すると可読性が高い。
そのため、Dockerfile 側にすでに設定があるかどうかに関わらず、コード規約としてマニフェスト側でも設定するようにする。
▼ privilegedを無効化する¶
特権コンテナの実行ユーザーは、root ユーザー権限の Capability (CHOWN、NET_RAW、CAP_SYS_BOOT、CAP_AUDIT_WRITE など) のすべて持っている。
非特権コンテナを実行する root ユーザーが Capability を全く持たないことからもわかるとおり、非常に大きな権限を持つ。
例えば、特権コンテナの実行ユーザーはルートファイルシステムにある /proc を書き換えられる。
/proc 配下には Node へのアクセスを中継するファイルがあるため、特権コンテナの実行ユーザーは Node 上で任意のコマンドを実行できる。
よって、これらを防ぐために特権コンテナは無効化しておいたほうがよい。
.spec.containers[*].securityContext.privileged キーで、コンテナに特権を付与するかどうかを設定できる。
▼ allowPrivilegeEscalationを無効化する¶
コンテナのプロセスは、コンテナ起動コマンド (親プロセス)、親プロセスが実行するプロセス (子プロセス) 、からなる。
.containers[*].securityContext.allowPrivilegeEscalation キーを有効化してしまうと、子プロセスは権限フラグ (setuid、setgid) を使用できるようになる。
権限フラグを使用すると、コンテナの実行ユーザーは、root ユーザーに近い権限を一時的に持てるようになる。
つまり、悪意のある人がこれを使用すると、Node 上のほかのコンテナや Node 自体にリクエストできてしまう。
そこで、.containers[*].securityContext.allowPrivilegeEscalation キーを有効化し、権限フラグを使用できないようにしておく。
▼ readOnlyRootFilesystemを有効化する¶
コンテナは自身のファイルシステムにリクエストを送信できる。
このときに、.containers[*].securityContext.readOnlyRootFilesystem キーが無効になっていると、コンテナのルートファイルシステムに Read/Write の両方を実行できる。
つまり、悪意のある人がこれを使用すると、任意のディレクトリ配下でファイルを作成変更できてしまう。
そこで、.containers[*].securityContext.readOnlyRootFilesystem キーを有効化し、Read のみを実行できるようにしておく。
アプリでログの出力先をログファイルにしているとエラーになってしまうため、標準出力/標準エラー出力にログを出力する必要がある。
UserAccount とRole / ClusterRole¶
UserAccountと最小権限のRoleを作成する¶
▼ UserAccount にはClusterRoleを紐付けない¶
最小権限にするため、UserAccount には ClusterRole を紐付けない。
代わりに Role を紐づけることで、Namespace スコープな K8s リソースのみにリクエストを送信できるようにする。
▼ チーム構成に合わせたUserAccountとRoleを作成する¶
最小権限にするため、チームを構成するメンバーの役割に合わせて、Role を作成する。
小規模なアプリほど、メンバーは複数の役割を兼備することになる。
| UserAccount | Roleの認可スコープ | |
|---|---|---|
| アプリメンバー | Reporter | 担当するNamespace内のK8sリソースのRead |
| インフラ寄りアプリメンバー | AppDeveloper | 担当するNamespace内のK8sリソースのRead/Write |
| アプリ寄りインフラメンバー | InfraDeveloper | すべてのNamespace内のK8sリソースのRead/Write |
| インフラメンバー | InfraDeveloper | すべてのNamespace内のK8sリソースのRead/Write |
| チームリーダー | Maintainer | すべてのNamespace内のK8sリソースのRead/Write、ClusterのRead/Write |
| Cluster管理者(一時的に使用できる) | Administrator | Cluster、Cluster内のすべてのK8sリソースのRead/Write |
▼ リリース時以外は本番環境はReadのみとする¶
実行環境の誤選択や悪意のある人のアクセスを防ぐために、リリース時以外はすべての UserAccount の本番環境の認可スコープを Read にする。
本番環境ではUserAccountに不必要に権限を割り当てない¶
▼ pods/exec や pods/attach を設定しない¶
Role や ClusterRole に設定できる pods/exec や pods/attach といった権限は、Pod 内のコンテナへ接続するために使う。
コンテナへの接続を許可してしまうと、コンテナ内から悪意のある人がサイバー攻撃を実施するかもしれない。また、悪意のない人による本来不必要な作業の実施につながるおそれがある。
一方で場合によっては、デバッグのために Pod 内のコンテナに接続する必要があるかもしれない。
そこで、本番環境では Cluster の管理者の UserAccount 以外には pods/exec や pods/attach を付与しない
また、テスト環境では基本的に設定しないが、必要であれば設定を許容する。
▼ Secretに関する権限を設定しない¶
ServiceAccountとRole / ClusterRole¶
Role や ClusterRole を使用して、ServiceAccount に適切な認可スコープを付与する。
テスト¶
マニフェスト静的解析ツールを使用する¶
▼ 検証したい項目を選ぶ¶
Kubernetes のマニフェストファイルに対する静的解析ツールが存在するため、必要に応じてエディタや CI などに組み込んで使用する。
マニフェストファイルは、例えば以下の観点で静的解析することが望ましい。
- マニフェストの文法
- マニフェストの組織特有のコード規約
- ベストプラクティス
- 脆弱性
- CPU/メモリのサイジングの最適値
- マニフェストの非推奨 apiVersion
- Helm チャートの構造
▼ 適切なツールを選び¶
ここでは、各観点を解析できるツールと、執筆時点 (2023/11) での推奨ツール (★) とその理由、開発初期時点で採用を推奨するツール (✅) を紹介している。
最終的に、すべての観点を解析する必要はなく、例えば ”CPU/メモリのサイジングの最適値” の解析は紹介だけにとどめている。
なお、Helm チャートや Kustomize を使用している場合、テンプレートからマニフェストを作成し、これをツールに渡すとよい。
## 例:helmチャートから作成したマニフェストをplutoの標準入力に渡す
$ helm template . -f foo-values.yaml \
| pluto detect -o wide -t k8s=<Kubernetesのバージョン> -
| 観点 | ツール名 | 概要 | 推奨ツール | ★の理由 (2023/11時点) | 開発初期時点で採用推奨 | |
|---|---|---|---|---|---|---|
| 文法違反 | kubeconform | https://github.com/yannh/kubeconform | Kubernetesリソースのスキーマ (カスタムリソースであればCRD) に基づいて、マニフェストの文法違反を検証する。 | ★ | kubevalの後継ツールであり、他にめぼしい競合ツールがない。 | |
| コード規約違反テスト | conftest | https://www.conftest.dev/ | Regoでコード規約を定義する。 | |||
| コード規約違反テスト | Gatekeeper | https://open-policy-agent.github.io/gatekeeper/website/docs/gator/ | Regoでコード規約を定義する。 | |||
| コード規約違反テスト | Kyverno | https://github.com/kyverno/kyverno | Yamlでコード規約を定義する。 | |||
| ベストプラクティス違反テスト | kubelinter | https://docs.kubelinter.io/#/ | 脆弱性、効率性、信頼性の観点で検証する。 | |||
| ベストプラクティス違反テスト | kubelinter | https://docs.kubelinter.io/#/ | 脆弱性、効率性、信頼性の観点で検証する。 | |||
| ベストプラクティス違反テスト | kube-score | https://kube-score.com/ | 脆弱性、信頼性の観点で検証する。 | |||
| ベストプラクティス違反テスト | polaris | https://polaris.docs.fairwinds.com/checks/security/ | 脆弱性、効率性、信頼性の観点で検証する。 | ★ | 競合ツールと比較して、ベストプラクティス違反の検証項目がもっとも多い。 | |
| 脆弱性診断 | trivy | https://aquasecurity.github.io/trivy/dev/docs/target/kubernetes/ | マニフェストの設定値に起因する脆弱性を検証する | ★ | 他の競合ツールとは異なり、K8s以外のIaCツール (Terraform、Dockerfile) や、コンテナイメージ (コンテナイメージ、マシンコンテナイメージ) も検証できるため、他の場面でも知見を流用できる。いずれのツールも、おおよそ同じDB (例:GitHub、GitLab、RedHatなど) に基づいて検証するため、脆弱性診断の項目数で優劣を比べないほうがよい。 | |
| サイジング最適値算出ツール | goldilocks | https://goldilocks.docs.fairwinds.com/ | IaCのソースコード上のCPU/メモリの設定値と、Cluster上の実際のハードウェアリソース消費量を比較して、最適値を算出できる。 | |||
| サイジング最適値算出ツール | robusta | https://github.com/robusta-dev/krr | Prometheusのメトリクスから各コンテナに最適なCPU/メモリの設定値を算出できる。 ただし、CPUのlimits値の設定はアンチパターンとして扱っており、未設定を推奨している。 | |||
| 非推奨apiVersion検出 | pluto | https://pluto.docs.fairwinds.com/ | 指定したKubernetesのバージョンに基づいて、マニフェストの非推奨apiVersionを検証する。 | ★ | 競合ツールのなかでもっともコントリビューター数が多くて開発が盛んである。また、GitHubのスター数がもっとも多い。 | ✅ |
| 非推奨apiVersion検出 | kubepug | https://kubepug.xyz/ | 指定したKubernetesのバージョンに基づいて、マニフェストの非推奨apiVersionを検証する。 | |||
| 非推奨apiVersion検出 | kube-no-trouble | https://github.com/doitintl/kube-no-trouble | 指定したKubernetesのバージョンに基づいて、マニフェストの非推奨apiVersionを検証する。 | |||
| 非推奨apiVersion検出 | Amazon EKSアップグレードインサイト | https://docs.aws.amazon.com/eks/latest/best-practices/cluster-upgrades.html | 指定したKubernetesのバージョンに基づいて、マニフェストの非推奨apiVersionを検証する。 |
ツールを選ぶときは、検証タイミングの設計思想を比べるとよい。
クライアント # 文法違反(kubeconform)、非推奨apiVersion検出(pluto、kubepug)
↓
--- Cluster
↓
kube-apiserver # コード規約違反テスト(Kyverno、Gatekeeper)
↓
etcd # 非推奨apiVersion検出(kube-no-trouble、Amazon EKS upgrade insights)
Helmチャートの静的解析ツールを使用する¶
▼ 検証したい項目を選ぶ¶
Helm チャート専用の静的解析ツールが存在するため、必要に応じてエディタや CI などに組み込んで使用する。
ここでは、各観点を解析できるツールと、執筆時点 (2023/11) での推奨ツール (★) とその理由、開発初期時点で採用を推奨するツール (✅) を紹介している。
最終的に、すべての観点を解析する必要はなく、例えば ”チャートのバージョン” の解析は紹介だけにとどめている。
| 観点 | ツール名 | 概要 | 推奨ツール | ★の理由 (2023/11時点) | 開発初期時点で採用推奨 |
|---|---|---|---|---|---|
| Helmチャート構造 | https://helm.sh/docs/helm/helm_lint/ | チャートの公式ルールに基づいて、構造の誤り (valuesファイルがあるか、Chart.yamlがあるかなど) を検証する。 | |||
| Helm専用のツールであり、Helmチャートを渡す必要がある。 | ★ | Helmのビルトインツールであり、めぼしい競合ツールがない。 | ✅ | ||
| チャートのバージョン | https://nova.docs.fairwinds.com/ | Helmチャートのバージョンが古くなっていないかを検証する。 | |||
| Helm専用のツールであり、Helmチャートを渡す必要がある。 |
ブラックボックステスト¶
▼ ロードテストを実施する¶
過去 (平常時、ピーク時、障害時) から予想できる負荷を Cluster にかける。
このときの性能が、非機能要件の期待値を満たしているかを検証する。
▼ Kubernetesのアップグレード後には各Kubernetesリソースの動作確認する¶
| 概要 | 内容 |
|---|---|
| Podが全滅していないことを確認する。 | PodDisruptionBugdetの設定によってWorkload (例:Deployment、DaemonSet、StatefulSet、Jobなど) で起動しているアプリケーションのPodが全滅しないかを確認する。 PodDisruptionBugdetを適切に設定できていないと、例えばWebアプリケーションのコンテナがすべてダウンしてしまいリクエストを受け付けられなくなるといったケースがあるため、PodDisruptionBugdetの設定した内容に沿ってPodが保護されるかを確認する。 |
| PodがまさしくNodeに分散されていることを確認する。 | NodeAffinityの設定に基づいて適切にPodがNodeに分散配置されるかや、NodeLabelやTaintの設定に基づいたNodeが選定されているかなどを確認する。 |
| Workloadのデプロイ戦略が正しく動作していることを確認する。 | Workload (例:Deployment、DaemonSet、StatefulSet、Jobなど) のデプロイ戦略 (例:RollingUpdate) が設定に応じた割合で行われ、Podの入れ替えが行われていることを確認する。 |
| WorkloadがPodのレプリカ数を維持できることを確認する。 | Workload (例:Deployment、DaemonSet、StatefulSet、Jobなど) に属するPodが削除され、replica数を下回った際に時間経過で設定したレプリカ数になるように回復されることを確認する。 |
| Podのスケーリングが正しく動作することを確認する。 | HorizontalPodAutorocalerやVerticalPodAutoscalerを使用している場合、HorizontalPodAutorocalerやVerticalPodAutoscalerの設定と使用しているメトリクスに応じたスケーリングが行われることを確認する。 |
| Nodeのスケーリングが正しく動作することを確認する。 | Cluster AutoscalerやKarpenterを使用している場合、Cluster AutoscalerやKarpenterの設定とNodeのリソース状況応じたスケーリングが行われることを確認する。 |
運用¶
運用しやすいチームを作る¶
▼ チームを体制する¶
K8s Cluster を使用したプロダクトのチームメンバー構成の例を挙げる。
前提として、実 Cluster をマルチテナントの単位とし、テナントごとに Cluster を管理しているとする。
チームメンバーが少なければ、兼任することになる。
- プロジェクトマネージャー
- アプリメンバー (バックエンド + フロントエンド)
- インフラ寄りアプリメンバー
- アプリ寄りインフラメンバー
- インフラメンバー
▼ メンバーで領域を分担する¶
担当領域の例を挙げる。
チームメンバーが少なければ、一人当たりの担当領域はより増えてしまう。
| 担当領域 | アプリメンバー | インフラ寄り アプリメンバー | アプリ寄りインフラメンバー | インフラメンバー |
|---|---|---|---|---|
| アプリケーションのフロントエンドとバックエンド | ✅ | ✅ | ||
| アプリケーションのWorkload(Deployment、CronJobなど) | ✅ | ✅ | ||
| インフラWorkloadの周辺K8sリソース(PodDisruptionBugdet、HorizontalPodAutorocaler、ConfigMap、Secretなど) | ||||
| アプリCIツール(コンテナイメージビルド、アプリケーションのホワイトボックステスト、コンテナイメージレジストリ格納など) | ✅ | ✅ | ||
| サービスメッシュのデータプレーン | ✅ | ✅ | ||
| マニフェストCIツール(ホワイトボックステストなど) | ✅ | ✅ | ||
| 分散トレーシング | ✅ | ✅ | ||
| CDツール | ✅ | |||
| サービスメッシュのコントロールプレーン | ✅ | ✅ | ||
| インフラのWorkload(Deployment、CronJobなど) 、周辺K8sリソース (PodDisruptionBugdet、HorizontalPodAutorocaler、ConfigMap、Secretなど) | ✅ | ✅ | ||
| コントロールプレーンNode ワーカーNode | ✅ | ✅ | ||
| K8s Clusterが依存する周辺インフラ | ✅ | ✅ | ✅ | |
| インフラの低レイヤー | ✅ |
運用しやすいテナントに分割する¶
▼ マルチテナントパターン¶
K8s リソースをグルーピングしたテナントを作成し、影響範囲を小さくする。
テナントには作成パターンがあり、それぞれのパターンでテナントに役割 (例:プロダクト、実行環境など) を割り当てる。
| パターン | Clusters as a Service | Control Plances as a Service | Namespaces as a Service | ツール固有テナント |
|---|---|---|---|---|
| テナントの単位 | 実Clusterテナント | 仮想Cluster | Namespaceテナント | カスタムリソーステナント |
| ツール | 実Cluster管理ツール (Amazon EKS、Google Cloud GKE、Azure AKE、Kubeadmなど) | 仮想Cluster管理ツール (Kcp、tensile-kube、vcluster、VirtualClusterなど) | Namespaceを増やすだけなのでツール不要 | ArgoCDのAppProject、CapsuleのTenant、kioskのAccount、KubeZooのTenantなど |
| … |
マニフェストを管理しやすくする¶
▼ K8sリソースのラベル付けする¶
マニフェストに意味付けするため、ラベルを付与する。
適切にラベルを付与しておくと、仕様を理解するうえでの助けになる。
| よくラベル | 説明 | 値の例 |
|---|---|---|
| http://app.kubernetes.io/name | アプリ側であればマイクロサービス名、インフラ側であればツール名を設定する。 | prometheus |
| http://app.kubernetes.io/component | K8sリソースをシステムの要素と捉えたときに、その役割名を設定する。 | app、database |
| http://app.kubernetes.io/part-of | K8sリソースをシステムの要素と捉えたときに、その親のシステム名を設定する。 | argocd |
| http://app.kubernetes.io/managed-by | K8sリソースの管理ツール名を設定する。 | helm、foo-operator、EKS (Amazon EKSアドオンなど) |
| … |
▼ マニフェスト管理ツールを使用する¶
大量のマニフェストファイルを個別にバージョン管理することは大変であり、一括して管理できるように、マニフェスト管理ツールを使用する。
- Helm
- Kustomize
監視¶
監視したいデータを決める¶
▼ ログを選ぶ¶
監視したいログを決める。
むやみやたらにログを収集すると、保管が大変なため、必要最低限のログにする。
- コントロールプレーン Node
- Pod のアクセスログ/実行ログ
- ワーカーNode
- アプリ Pod のアクセスログ/実行ログ
- インフラ Pod のアクセスログ/実行ログ
▼ メトリクス選ぶ¶
監視したいメトリクスを決める。
むやみやたらにメトリクスの元になるデータポイントを収集すると、収集対象に負荷がかかるため、必要最低限のメトリクスにする。
監視したいメトリクスを決める。
むやみやたらにメトリクスの元になるデータポイントを収集すると、収集対象に負荷がかかるため、必要最低限のメトリクスにする。
| メトリクスの種類 | 収集ツール例 |
|---|---|
| ハードウェアリソース系 (CPU使用量、メモリ使用量など) | Node Exporter、cAdvisor |
| ネットワーク系 (帯域幅、スループット値など) | cAdvisor |
| 状態系 (Podのレプリカ数、ヘルスチェックの失敗数など) | kube-state-metrics |
対象のデータを収集する¶
▼ ログを収集する¶
監視したいログを収集する。
| パターン | DaemonSetパターン | Pod内サイドカーパターン |
|---|---|---|
| 説明 | ログ収集ツールのPodをDaemonSetで動かす。 Pod内のアプリで、ログを標準出力/標準エラーに出力し、一度Nodeに保管する。FluentdやFluentBitを使用して、Node上のログを監視バックエンドに送信する。 | ログ収集ツールをPod内のサイドカーで動かす。ログ収集ツールが提供するドライバーを使用して、Pod内のアプリからログ収集コンテナにログを渡す。Pod内のログ収集コンテナから監視バックエンドにログを直接送信する。 |
| … |
▼ メトリクスの元になるデータポイントを収集する¶
監視したいメトリクスの元になるデータポイントを収集する。
ここにデータポイント収集の設計パターンを書く…
収集したログ/メトリクスを保管する¶
収集したログ/メトリクスをストレージに保管する。
| 要件 | 説明 |
|---|---|
| ストレージ容量 | ログファイルのメトリクスのストレージのサイズを決める。 メトリクスの場合、データポイント数を抑えて (例:収集間隔の拡大、ダウンサンプリング、重複排除) 、データサイズを小さくするとよい。 |
| バックアップしないログ | すべてのログを保管するとストレージ容量を圧迫してしまうため、一部のログ (例:ヘルスチェックのアクセスログ) は捨てるように決めておくとよい。 |
| バックアップの保管期間 (リテンション) | ログファイルのメトリクスのバックアップを実施し、また保管期間ポリシー (例:3ヶ月) を決めておくとよい。 |
| ローテーション | ログローテーションによって、ファイルを小さく分割して保管しておく。ログファイルやメトリクスのローテーション期間 (例:7日) をポリシーとして決めておくとよい。 ローテションされた過去のログやメトリクスのファイルでは、ファイル名の末尾に最終日付 (例:-20220101) をつけておく。 |
| 世代数 | ローテションの結果作成されるファイルの世代数 (例:5) をポリシーとして決めておくとよい。 ただ、これは設定できないツールがある。 |