リソース定義@Kubernetes¶
はじめに¶
本サイトにつきまして、以下をご認識のほど宜しくお願いいたします。
APIService¶
.spec.group¶
▼ groupとは¶
拡張 apiserver が受信する API グループ名を設定する。
apiVersion: apiregistration.k8s.io/v1
kind: APIService
metadata:
name: v1beta1.foo.k8s.io
spec:
group: foo.k8s.io
.spec.groupPriorityMinimum¶
▼ groupPriorityMinimumとは¶
同じ API グループがある場合に、優先度を設定する。
apiVersion: apiregistration.k8s.io/v1
kind: APIService
metadata:
name: v1beta1.foo.k8s.io
spec:
groupPriorityMinimum: 100
.spec.insecureSkipTLSVerify¶
▼ insecureSkipTLSVerifyとは¶
apiVersion: apiregistration.k8s.io/v1
kind: APIService
metadata:
name: v1beta1.foo.k8s.io
spec:
insecureSkipTLSVerify: true
.spec.service¶
▼ serviceとは¶
拡張 apiserver は、kube-apiserver からリクエストを直接的に受信するのではなく、専用の Service を介してリクエストを受信する。このとき、どの Service からリクエストを受信するかを設定する。
apiVersion: apiregistration.k8s.io/v1
kind: APIService
metadata:
name: v1beta1.foo.k8s.io
spec:
service:
name: foo-service
namespace: kube-system
port: 443
.spec.version¶
▼ versionとは¶
拡張 apiserver が受信する API グループのバージョンを設定する。
apiVersion: apiregistration.k8s.io/v1
kind: APIService
metadata:
name: v1beta1.foo.k8s.io
spec:
version: v1beta1
.spec.versionPriority¶
▼ versionPriorityとは¶
同じ API グループがある場合に、バージョンの優先度を設定する。
apiVersion: apiregistration.k8s.io/v1
kind: APIService
metadata:
name: v1beta1.foo.k8s.io
spec:
versionPriority: 100
CertificateSigningRequest¶
.spec.request¶
▼ requestとは¶
base64 方式でエンコードした証明書署名要求 (.csr ファイル) を設定する。
apiVersion: certificates.k8s.io/v1
kind: CertificateSigningRequest
metadata:
name: foo-csr
spec:
groups:
- system:authenticated
# base64方式でエンコードした証明書署名要求ファイル
request: LS0tL...
signerName: kubernetes.io/kube-apiserver-client
usages:
- digital signature
- key encipherment
- client auth
定義した CertificateSigningRequest を承認し、サーバー証明書 (.crt) を作成するためには、kubectl certificate approve コマンドを使用する。
# 承認
$ kubectl certificate approve foo-csr
# サーバー証明書を取得する。
$ kubectl get csr foo-csr -o jsonpath='{.status.certificate}'| base64 -d > foo.crt
Config¶
clusters¶
▼ clustersとは¶
kubectl コマンドの向き先となる Cluster を設定する。
▼ name¶
Cluster 名を設定する。
apiVersion: v1
kind: Config
clusters:
- name: <ClusterのARN>
...
- name: docker-desktop
...
- name: minikube
...
▼ cluster¶
kub-apiserver の接続先情報を設定する。
apiVersion: v1
kind: Config
clusters:
- cluster:
# kube-apiserverのサーバー証明書
certificate-authority-data: LS0tLS1 ...
# kube-apiserverのURL
server: https://*****.gr7.ap-northeast-1.eks.amazonaws.com
...
- cluster:
certificate-authority-data: LS0tLS1 ...
server: https://kubernetes.docker.internal:6443
...
- cluster:
certificate-authority: /Users/hiroki-hasegawa/.minikube/ca.crt
extensions:
- extension:
last-update: Fri, 13 May 2022 16:58:59 JST
provider: minikube.sigs.k8s.io
version: v1.25.2
name: cluster_info
server: https://127.0.0.1:52192
...
contexts¶
▼ contextsとは¶
kubectl コマンドの向き先の候補を設定する。
▼ name¶
向き先の名前を設定する。
apiVersion: v1
kind: Config
contexts:
- name: <ClusterのARN>
...
- name: docker-desktop
...
- name: minikube
...
▼ context¶
実際に使用する Cluster 名と ServiceAccount ユーザー名を、.contexts[*].context.cluster キーと .contexts[*].context.user キーから選んで設定する。
apiVersion: v1
kind: Config
contexts:
- context:
cluster: <ClusterのARN>
user: <ClusterのARN>
...
- context:
cluster: docker-desktop
user: docker-desktop
...
- context:
cluster: minikube
extensions:
- extension:
last-update: Fri, 13 May 2022 16:58:59 JST
provider: minikube.sigs.k8s.io
version: v1.25.2
name: context_info
namespace: default
user: minikube
...
current-context¶
▼ current-contextとは¶
kubectl コマンドの現在の向き先の名前を設定する。
apiVersion: v1
kind: Config
current-context: <ClusterのARN>
preferences¶
▼ preferencesとは¶
apiVersion: v1
kind: Config
preferences: {}
users¶
▼ usersとは¶
kube-apiserver のクライアント (特に kubectl コマンド実行者) の UserAccount の情報を設定する。
▼ name¶
ユーザー名を設定する。
apiVersion: v1
kind: Config
users:
- name: <ClusterのARN>
...
- name: docker-desktop
...
- name: minikube
▼ user¶
ユーザーの資格情報を設定する。
Amazon EKS のように、資格情報を動的に取得するようにしてもよい。
apiVersion: v1
kind: Config
users:
- user:
exec:
apiVersion: client.authentication.k8s.io/v1
args:
- --region
- ap-northeast-1
- eks
- get-token
- --cluster-name
- prd-foo-eks-cluster
command: "aws"
...
- user:
client-certificate-data: LS0tLS1 ...
client-key-data: LS0tLS1 ...
...
- user:
client-certificate: /Users/hiroki-hasegawa/.minikube/profiles/minikube/client.crt
client-key: /Users/hiroki-hasegawa/.minikube/profiles/minikube/client.key
...
ConfigMap¶
data¶
▼ dataとは¶
Kubernetes リソースに渡す機密でない変数を設定する。
▼ 変数の管理¶
ConfigMap に設定する変数を設定する。
apiVersion: v1
kind: ConfigMap
metadata:
name: foo-config-map
data:
bar: BAR
string 型しか設定できないため、デコード後に integer 型や boolean 型になってしまう値は、ダブルクオーテーションで囲う必要がある。
apiVersion: v1
kind: ConfigMap
metadata:
name: foo-config-map
data:
enableFoo: true # ダブルクオーテーションで囲う。
number: "1"
▼ ファイルに管理¶
パイプ (|) を使用すれば、ファイルを変数として設定できる。
apiVersion: v1
kind: ConfigMap
metadata:
name: foo-fluent-bit-conf-config-map
data:
fluent-bit.conf: |
[SERVICE]
Flush 1
Log_Level info
[OUTPUT]
Name cloudwatch
Match *
region ap-northeast-1
log_group_name /prd-foo-k8s/log
log_stream_prefix container/fluent-bit/
auto_create_group true
CronJob¶
.spec.concurrencyPolicy¶
▼ concurrencyPolicy¶
CronJob 配下の Job の並列処理ルールを設定できる。
▼ Allow¶
Job の並列処理を許可する。
▼ Forbid¶
Job の並列処理を拒否する。
▼ Allow¶
もし別の Job を実行していれば、その Job を停止して新しく Job を実行する。
.spec.jobTemplate¶
▼ jobTemplateとは¶
CronJob で、定期的に実行する Job を設定する。
apiVersion: batch/v1
kind: CronJob
metadata:
name: foo-cronjob
spec:
# 毎日 00:00 (JST) に実行する
schedule: "0 15 * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: foo-alpine
image: alpine:latest
# 定期的に実行するコマンドを設定する。
command:
- /bin/bash
- -c
args:
- echo Hello World
restartPolicy: OnFailure
.spec.failedJobsHistoryLimit¶
▼ failedJobsHistoryLimitとは¶
実行に失敗した Job に関して、上限の履歴数を設定する。
apiVersion: io.k8s.api.batch.v1
kind: CronJob
metadata:
name: foo-cronjob
spec:
failedJobsHistoryLimit: 2
.spec.schedule¶
▼ scheduleとは¶
Cron のルールを設定する。
apiVersion: io.k8s.api.batch.v1
kind: CronJob
metadata:
name: foo-cronjob
spec:
# 1時間ごとに実行する
schedule: "00 * * * *"
なお、タイムゾーンは Kubernetes Cluster の設定による。
例えば、Amazon EKS Cluster は UTC で時間を管理しているため、9 時間分ずらす必要がある。
apiVersion: io.k8s.api.batch.v1
kind: CronJob
metadata:
name: foo-cronjob
spec:
# 毎日 00:00 (JST) に実行する
schedule: "0 15 * * *"
.spec.startingDeadlineSeconds¶
▼ startingDeadlineSeconds¶
Job が Cron のスケジュール通りに実行されなかった場合、実行の遅れを何秒まで許容するかを設定する。
指定した秒数を過ぎると、実行を失敗とみなす。
apiVersion: io.k8s.api.batch.v1
kind: CronJob
metadata:
name: foo-cronjob
spec:
startingDeadlineSeconds: 100
CronJob のデフォルトの仕様として、Job が 100 回連続で失敗すると、CronJob を再作成しない限り Job を再実行できなくなる。
1 時間に Job を 1 回実行すると仮定すると、簡単に 100 回を超過してしまう。
停止時間 (8h) * 実行間隔 (60/h) = 480回
このとき、.spec.startingDeadlineSeconds キーを設定しておくと、これの期間に 100 回連続で失敗したときのみ、Job を再実行できなくなる。
100 回連続を判定する期間を短くすることで、再作成しなくてもよくなるようにする。
.spec.successfulJobsHistoryLimit¶
▼ successfulJobsHistoryLimitとは¶
実行に成功した Job に関して、上限の履歴数を設定する。
apiVersion: batch/v1
kind: CronJob
metadata:
name: foo-cronjob
spec:
successfulJobsHistoryLimit: 2
DaemonSet¶
.spec.replicas¶
Deployment と同じである。
.spec.strategy¶
.spec.strategy (RollingUpdateの場合)¶
Pod で .spec.containers[*].ports[*].hostPort キーを使用する場合、.spec.strategy.rollingUpdate.maxSurge キーは 0 (デフォルト値) にしなければならない。
Deployment¶
.spec.replicas¶
▼ replicasとは¶
Cluster 内で維持する Pod のレプリカ数を設定する。
Cluster 内に複数の Node が存在していて、いずれかの Node が停止した場合、稼働中の Node 内でレプリカ数を維持するように Pod 数が増加する。
HorizontalPodAutoscaler を使用する場合、レプリカ数は HPA が決めるため .spec.replicas は設定不要である。
apiVersion: apps/v1
kind: Deployment
metadata:
name: foo-deployment
spec:
# HorizontalPodAutoscalerを使用する場合、.spec.replicasは設定不要である
replicas: 2
selector:
matchLabels:
app.kubernetes.io/name: foo-pod
app.kubernetes.io/component: app
template:
metadata:
labels:
app.kubernetes.io/name: foo-pod
app.kubernetes.io/component: app
.spec.revisionHistoryLimit¶
▼ revisionHistoryLimitとは¶
保管されるリビジョンの履歴数を設定する。
もし依存のリビジョンにロールバックする場合があるのであれば、必要数を設定しておく。
デフォルトは 10 個で、個人的にこれは多い。
apiVersion: apps/v1
kind: Deployment
metadata:
name: foo-deployment
spec:
revisionHistoryLimit: 5
selector:
matchLabels:
app.kubernetes.io/name: foo-pod
app.kubernetes.io/component: app
template:
metadata:
labels:
app.kubernetes.io/name: foo-pod
app.kubernetes.io/component: app
.spec.selector¶
▼ selectorとは¶
Deployment で管理する Pod を明示的に設定する。
▼ matchLabels¶
Pod の .metadata.labels キーを指定する。
Pod に複数の .metadata.labels キーが付与されているときは、これらをすべて指定する必要がある。
apiVersion: apps/v1
kind: Deployment
metadata:
name: foo-deployment
spec:
selector:
matchLabels: # Deploymentに紐付けるPodのmetadata.labelsキー
app.kubernetes.io/name: foo-pod
app.kubernetes.io/component: app
template:
metadata:
labels: # Podのmetadata.labelsキー
app.kubernetes.io/name: foo-pod
app.kubernetes.io/component: app
▼ field is immutable¶
Deployment の .spec.selector.matchLabels キーの値は変更できないため、もしこの値を変更する場合は、Deployment を再作成する必要がある。
例えば、以下のマニフェストの .spec.selector.matchLabels キーの値を変更しようとする。
apiVersion: apps/v1
kind: Deployment
metadata:
name: foo-deployment
spec:
selector:
matchLabels:
app.kubernetes.io/name: foo-pod # 変更しようとする
app.kubernetes.io/component: app # 変更しようとする
template:
metadata:
labels:
app.kubernetes.io/name: foo-pod
app.kubernetes.io/component: app
すると、以下のようなエラーになってしまう。
v1.LabelSelector{MatchLabels:map[string]string{"app.kubernetes.io/name":"foo-pod", "app.kubernetes.io/component":"app"}, MatchExpressions:[]v1.LabelSelectorRequirement(nil)}: field is immutable
.spec.strategy¶
▼ strategyとは¶
デプロイメントの方法を設定する。
以下のタイミングで Deployment は Pod を再デプロイする。
| 箇所 | 説明 |
|---|---|
.spec.replicas キー |
Podのレプリカ数を変更すると、DeploymentはPodを再デプロイする。 |
.spec.template キー配下の任意のキー |
Podテンプレートを変更した場合、DeploymentはPodを再デプロイする。 |
.spec.strategy.type (Recreateの場合)¶
▼ Recreateとは¶
インプレースデプロイメントを使用して、新しい Pod を作成する。
apiVersion: apps/v1
kind: Deployment
metadata:
name: foo-deployment
spec:
strategy:
type: Recreate
selector:
matchLabels:
app.kubernetes.io/name: foo-pod
app.kubernetes.io/component: app
template:
metadata:
labels:
app.kubernetes.io/name: foo-pod
app.kubernetes.io/component: app
.spec.strategy (RollingUpdateの場合)¶
▼ RollingUpdateとは¶
ローリングアップデートを使用して、新しい Pod を作成する。
ダウンタイムなしで Pod を入れ替えられる。
▼ ブルー/グリーン方式 (パーセントの場合)¶
もし .spec.strategy.rollingUpdate.maxSurge キーを 100%、また .spec.strategy.rollingUpdate.maxUnavailable キーを 0%とすると仮定する。
apiVersion: apps/v1
kind: Deployment
metadata:
name: foo-deployment
spec:
# レプリカ数は10とする
replicas: 10
strategy:
type: RollingUpdate
rollingUpdate:
# デプロイ時に、Podのレプリカ数の50% (5個) だけ、新しいPodを並行的に作成する
maxSurge: 100%
# デプロイ時に、Podのレプリカ数の0% (0個) が停止している状態にならないようにする
maxUnavailable: 00%
selector:
matchLabels:
app.kubernetes.io/name: foo-pod
app.kubernetes.io/component: app
template:
metadata:
labels:
app.kubernetes.io/name: foo-pod
app.kubernetes.io/component: app
この場合、RollingUpdate 戦略時に、Pod のレプリカ数と同じ数だけ新しい Pod を作成するようになる。
.spec.strategy.rollingUpdate.maxSurge キーにより、10 個の新しい Pod を並行的に作成する (つまり、デプロイ時に新旧 Pod が合計 20 個ある) 。
.spec.strategy.rollingUpdate.maxUnavailable キーにより、0 個が停止している状態を避ける (停止する Pod がない)。
また、Pod の停止数がレプリカ数を下回らないようになる。
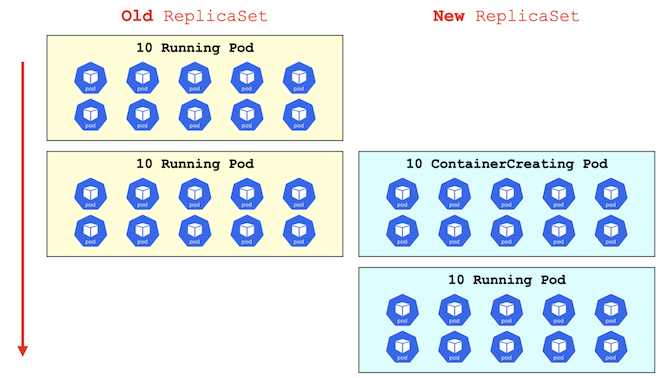
▼ ブルー/グリーン方式 (絶対値の場合)¶
もし .spec.strategy.rollingUpdate.maxSurge キーを 10、また .spec.strategy.rollingUpdate.maxUnavailable キーを 0 と仮定する。
apiVersion: apps/v1
kind: Deployment
metadata:
name: foo-deployment
spec:
# レプリカ数は10とする
replicas: 10
strategy:
type: RollingUpdate
rollingUpdate:
# デプロイ時に、Podのレプリカ数の10個だけ、新しいPodを並行的に作成する
maxSurge: 10
# デプロイ時に、Podのレプリカ数の0個が停止している状態にならないようにする
maxUnavailable: 0
selector:
matchLabels:
app.kubernetes.io/name: foo-pod
app.kubernetes.io/component: app
template:
metadata:
labels:
app.kubernetes.io/name: foo-pod
app.kubernetes.io/component: app
この場合、RollingUpdate 戦略時に、Pod のレプリカ数と同じ数だけ新しい Pod を作成するようになる。
.spec.strategy.rollingUpdate.maxSurge キーにより、10 個の新しい Pod を並行的に作成する (つまり、デプロイ時に新旧 Pod が合計 20 個ある)。
.spec.strategy.rollingUpdate.maxUnavailable キーにより、0 個が停止している状態を避ける (停止する Pod がない)。
また、Pod の停止数がレプリカ数を下回らないようになる。
.spec.template¶
▼ templateとは (設定項目はPodと同じ)¶
Deployment で維持管理する Pod テンプレートを設定する。
設定項目は Pod と同じである。
Deployment 自体の .metadata.labels キーを更新した場合、Pod は再作成しない。しかし、.spec.template キー配下の .metadata.labels キーの場合、Pod は再作成する。
*実装例*
apiVersion: apps/v1
kind: Deployment
metadata:
name: foo-deployment
spec:
selector:
matchLabels:
app.kubernetes.io/name: foo-pod
app.kubernetes.io/component: app
template:
metadata:
labels:
app.kubernetes.io/name: foo-pod
spec:
containers:
- name: app
image: app:1.0.0
ports:
- containerPort: 8080
EndpointSlice¶
.spec.endpoints¶
▼ endpointsとは¶
Service でルーティング先の Pod に関して、『現在の』 宛先情報を設定する。
Kubernetes が自動的に更新するため、ユーザーが管理する必要はない。
▼ addresses¶
Pod の現在の IP アドレスを設定する。
apiVersion: discovery.k8s.io/v1
kind: EndpointSlice
metadata:
name: foo-endpoint-slice
endpoints:
- addresses:
- *.*.*.*
▼ condition¶
Pod の現在のライフサイクルフェーズを設定する。
apiVersion: discovery.k8s.io/v1
kind: EndpointSlice
metadata:
name: foo-endpoint-slice
endpoints:
- conditions:
ready: true
serving: true
terminating: false
▼ nodeName¶
Pod をスケジューリングさせている Node 名を設定する。
これにより、Service とそのルーティング先の Pod が異なる Node 上に存在していたとしても、Service は Pod にルーティングできる。
apiVersion: discovery.k8s.io/v1
kind: EndpointSlice
metadata:
name: foo-endpoint-slice
endpoints:
- nodeName: foo-node
▼ targetRef¶
Pod の識別子を設定する。
apiVersion: discovery.k8s.io/v1
kind: EndpointSlice
metadata:
name: foo-endpoint-slice
endpoints:
- targetRef:
kind: Pod
name: foo-pod
namespace: foo-namespace
▼ zone¶
Pod をスケジューリングさせている AZ を設定する。
apiVersion: discovery.k8s.io/v1
kind: EndpointSlice
metadata:
name: foo-endpoint-slice
endpoints:
- zone: ap-northeast-1a
.spec.ports¶
▼ portsとは¶
Pod が待ち受けるポート番号を設定する。
Kubernetes が自動的に更新するため、ユーザーが管理する必要はない。
apiVersion: discovery.k8s.io/v1
kind: EndpointSlice
metadata:
name: foo-endpoint-slice
ports:
- name: http-foo
port: 443
protocol: TCP
HTTPRoute¶
parentRefs¶
紐づける Gateway を設定する。
Gateway は共有の Namespace に配置し、HTTPRoute はマイクロサービスのある各 Namespace に配置する。
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
name: foo
spec:
parentRefs:
- name: ingress-nginx
namespace: ingress-nginx
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
name: foo
spec:
parentRefs:
- name: istio-ingressgateway
namespace: istio-ingress
rules¶
宛先の Service を設定する。
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
name: foo
spec:
rules:
- backendRefs:
- kind: Service
name: foo
port: 80
HorizontalPodAutoscaler¶
.spec.maxReplicas、spec.minReplicas¶
▼ maxReplicasとは¶
自動水平スケーリングのスケールアウト時の最大 Pod 数を設定する。
最初、Deployment の spec.replicas キーに合わせて Pod が作成され、次に HorizontalPodAutoscaler の .spec.minReplicas キーが優先される。
この挙動は混乱につながるため、HorizontalPodAutoscaler を使用する場合、Deployment の spec.replicas キーの設定を削除しておくことが推奨である。
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: foo-horizontal-pod-autoscaler
spec:
maxReplicas: 5
▼ minReplicasとは¶
自動水平スケーリングのスケールイン時の最小 Pod 数を設定する。
最初、Deployment の spec.replicas キーに合わせて Pod が作成され、次に HorizontalPodAutoscaler の .spec.minReplicas キーが優先される。
この挙動は混乱につながるため、HorizontalPodAutoscaler を使用する場合、Deployment の spec.replicas キーの設定を削除しておくことが推奨である。
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: foo-horizontal-pod-autoscaler
spec:
minReplicas: 3
.spec.targetCPUUtilizationPercentage¶
維持する CPU 使用率を設定する。
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: foo-horizontal-pod-autoscaler
spec:
targetCPUUtilizationPercentage: 50
.spec.metrics¶
▼ metricsとは¶
自動水平スケーリングのトリガーとするメトリクスと、維持されるターゲット値を設定する。
▼ type¶
メトリクスの種類を設定する。
以下のタイプを設定できる。
なお、カスタムメトリクスの元になるデータポイントを収集するためには、別途ツール (例:prometheus-adapter) が必要である。
| タイプ名 | 説明 | メトリクス例 |
|---|---|---|
Resource |
リソースメトリクス | CPU使用率、メモリ使用率など |
Pods |
Podのカスタムメトリクス | Queries Per Second、message broker’s queueなど |
Object |
Pod以外のKubernetesリソースのカスタムメトリクス | Ingressに関するメトリクスなど |
External |
Kubernetes以外の任意のメトリクス | AWS、Google Cloud、Azureに固有のメトリクス |
▼ Resourceの場合¶
Deployment のリソースメトリクスを指定する。
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: foo-horizontal-pod-autoscaler
spec:
metrics:
- type: Resource
resource:
name: cpu
targetAverageUtilization: 60
▼ Podsの場合¶
Pod のカスタムメトリクスを指定する。
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: foo-horizontal-pod-autoscaler
spec:
metrics:
- type: Pods
resource:
name: cpu
targetAverageUtilization: 60
▼ Objectの場合¶
記入中...
▼ Externalの場合¶
記入中...
.spec.scaleTargetRef¶
▼ scaleTargetRefとは¶
自動水平スケーリングを実行する Kubernetes リソースを設定する。
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: foo-horizontal-pod-autoscaler
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment # Deploymentで自動水平スケーリングを実行する。
name: foo-deployment
▼ Deploymentの場合¶
デプロイ戦略に基づいて、新しい ReplicaSet を作成し、Pod を自動水平スケーリングする。
▼ ReplicaSetの場合¶
既存の ReplicaSet 配下で Pod を自動水平スケーリングする。
▼ StatefulSetの場合¶
デプロイ戦略に基づいて、新しい Pod を自動水平スケーリングする。
Ingress¶
.metadata.annotations¶
▼ annotationsとは¶
IngressClass の専用オプションを設定する。
.spec.ingressClassName¶
▼ ingressClassNameとは¶
IngressClass の .metadata.name キーの値を設定する。
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: foo-ingress
spec:
ingressClassName: foo-ingress-class
.spec.hosts¶
▼ hosts¶
ルーティング条件とする Host ヘッダー値を設定する。
.spec.rules[*].hosts キーを設定しなければ、すべての Host ヘッダー値が対象になる。
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: foo-ingress
spec:
hosts: foo.example.com
.spec.rules¶
▼ rulesとは¶
Service へのルーティングルールを設定する。
複数の Service にインバウンド通信を振り分けられる。
Ingress を使用する場合、宛先の Service は、ClusterIP Service とする。
▼ .spec.rules[*].host¶
ホストベースルーティングの判定に使用するパス名を設定する。
本番環境では、ドメインを指定した各種ダッシュボードにリクエストを送信できる必要がある。
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: foo-ingress
spec:
rules:
- host:
- prd.monitoring.com
http:
paths:
- path: /
▼ .spec.rules[].http.paths[].path¶
パスベースルーティングの判定に使用するパス名を設定する。
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: foo-ingress
spec:
rules:
- http:
paths:
- path: /foo
- http:
paths:
- path: /bar
▼ .spec.rules[].http.paths[].pathType¶
パスベースルーティング判定時のルールの厳しさを設定する。
| 厳しさ | タイプ | |
|---|---|---|
| パス名の前方一致 | Prefix | 前方一致である。最初のパスさえ合致すれば、トレイリングスラッシュの有無や最初のパス以降のパスも許容して合致させる。そのため、ワイルドカード (*) は不要である。 |
| パス名の完全一致 | Exact | 完全一致である。指定したパスのみを合致させ、トレイリングスラッシュも有無も許容しない。 |
| IngressClassの機能による | ImplementationSpecific | IngressClass (例:Nginx、ALBなど) の設定に応じて、独自タイプ、Prefix、Exactを自動的に切り替える。そのため、IngressのルーティングルールがIngressClassに依存している。IngressClassの仕様変更や別のIngressClassへの移行があった場合に、Ingress Controllerが想定外のルーティングを実行する可能性がある。 |
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: foo-ingress
spec:
rules:
- http:
paths:
- path: /foo
pathType: Prefix
- http:
paths:
- path: /bar
pathType: Prefix
▼ .spec.rules[].http.paths[].backend¶
宛先の Service を設定する。
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: foo-ingress
spec:
rules:
- http:
paths:
- path: /foo
pathType: Prefix
backend:
service:
name: foo-service # CluserIP Serviceとする。
port:
number: 80
- http:
paths:
- path: /bar
pathType: Prefix
backend:
service:
name: bar-service # CluserIP Serviceとする。
port:
number: 80
IngressClass¶
.metadata.annotations¶
▼ is-default-class¶
デフォルトの IngressClass として設定する。
apiVersion: networking.k8s.io/v1
kind: IngressClass
metadata:
name: foo-ingress-class
annotations:
ingressclass.kubernetes.io/is-default-class: true
spec: ...
.spec.controller¶
▼ controllerとは¶
Ingress Controller の実体として使用するツールの API グループを設定する。
- https://kubernetes.io/docs/reference/kubernetes-api/service-resources/ingress-class-v1/#IngressClassSpec
- https://kubernetes-sigs.github.io/aws-load-balancer-controller/v2.2/guide/ingress/ingress_class/#deprecated-kubernetesioingressclass-annotation
- https://kubernetes.github.io/ingress-nginx/#i-have-only-one-ingress-controller-in-my-cluster-what-should-i-do
▼ AWS ALBの場合¶
apiVersion: networking.k8s.io/v1
kind: IngressClass
metadata:
name: foo-alb-ingress-class
spec:
controller: ingress.k8s.aws/alb
▼ Nginx Ingressの場合¶
apiVersion: networking.k8s.io/v1
kind: IngressClass
metadata:
name: foo-ingress-class
spec:
controller: k8s.io/ingress-nginx
▼ Istio Ingressの場合¶
apiVersion: networking.k8s.io/v1
kind: IngressClass
metadata:
name: foo-istio-ingress-class
spec:
controller: istio.io/ingress-controller
.spec.parameters¶
▼ parametersとは¶
外部 Ingress に応じたオプションを設定する。
代わりに、IngressClassParams を使用してもよい。
▼ AWS ALBの場合¶
apiVersion: networking.k8s.io/v1
kind: IngressClass
metadata:
name: foo-alb-ingress-class
spec:
parameters:
apiGroup: elbv2.k8s.aws
kind: IngressClassParams
name: foo-alb-ingress-class-params
Gateway¶
spec.gatewayClassName¶
▼ gatewayClassNameとは¶
GatewayClass の .metadata.name キーの値を設定する。
Gateway は共有の Namespace に配置し、HTTPRoute はマイクロサービスのある各 Namespace に配置する。
▼ Nginxの場合¶
Nginx を作成する。
apiVersion: gateway.networking.k8s.io/v1
kind: Gateway
metadata:
name: gateway
namespace: istio-ingress
spec:
gatewayClassName: istio
▼ istioの場合¶
Istio Ingress Gateway を作成する。
apiVersion: gateway.networking.k8s.io/v1
kind: Gateway
metadata:
name: gateway
namespace: istio-ingress
spec:
gatewayClassName: istio
▼ istio-waypointの場合¶
Istio の waypoint-proxy を作成する。
apiVersion: gateway.networking.k8s.io/v1
kind: Gateway
metadata:
name: gateway
namespace: istio-ingress
spec:
gatewayClassName: istio-waypoint
spec.listeners¶
apiVersion: gateway.networking.k8s.io/v1
kind: Gateway
metadata:
name: gateway
namespace: istio-ingress
spec:
# Istio Ingress Gatewayを作成する
gatewayClassName: istio
listeners:
- name: default
hostname: "*.example.com"
port: 443
protocol: HTTPS
tls:
certificateRefs:
- kind: Secret
group: ""
name: self-signed-cert
namespace: istio-ingress
allowedRoutes:
namespaces:
from: All
GatewayClass¶
spec.controllerName¶
▼ controllerNameとは¶
Gateway の実体として使用するツールの API グループを設定する。
kind: GatewayClass
metadata:
name: foo-gateway
spec:
controllerName: "example.net/gateway-controller"
▼ Envoyの場合¶
apiVersion: gateway.networking.k8s.io/v1
kind: GatewayClass
metadata:
name: envoy-gateway
spec:
controllerName: gateway.envoyproxy.io/gatewayclass-controller
▼ Istioの場合¶
apiVersion: gateway.networking.k8s.io/v1
kind: GatewayClass
metadata:
name: istio
spec:
controllerName: istio.io/gateway-controller
▼ Traefikの場合¶
記入中...
▼ Amazon VPC Latticeの場合¶
Amazon VPC Lattice をプロビジョニングする。
apiVersion: gateway.networking.k8s.io/v1
kind: GatewayClass
metadata:
name: amazon-vpc-lattice
spec:
controllerName: application-networking.k8s.aws/gateway-api-controller
Namespace¶
apiVersion: v1
kind: Namespace
metadata:
name: foo
NetworkPolicy¶
NetworkPolicyとは¶
自身の所属する Namespace に対して、インバウンドとアウトバウンドな通信を制限する。
それぞれの Namespace で NetworkPolicy を作成すると、Namespace 間の通信はデフォルトで拒否になる。
そのため、許可するように設定する。
egress¶
許可するアウトバウンド通信を設定する。
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: foo-network-policy
namespace: foo
spec:
policyTypes:
- Egress
egress:
# アウトバウンド通信の宛先IPアドレス
- to:
# 送信を許可するCIDRブロック
- ipBlock:
cidr: 10.0.0.0/24
# アウトバウンド通信の宛先ポート
ports:
- protocol: TCP
port: 5978
ingress¶
許可するインバウンド通信を設定する。
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: foo-network-policy
namespace: foo
spec:
policyTypes:
- Ingress
ingress:
# インバウンド通信の送信元IPアドレス
- from:
# Cluster外からのインバウンド通信のうちで、受信を許可するCIDRブロック
- ipBlock:
cidr: 172.17.0.0/16
except:
- 172.17.1.0/24
# 受信を許可するNamespace
- namespaceSelector:
matchLabels:
project: myproject
# 同じNamespaceに所属するPodからのインバウンド通信のうちで、受信を許可するPod
- podSelector:
matchLabels:
role: frontend
# インバウンド通信の宛先ポート
- ports:
- protocol: TCP
port: 6379
podSelector¶
▼ podSelectorとは¶
NetworkPolicy を適用する Pod を設定する。
▼ matchLabels¶
metadata.labels キーの値で Pod を選ぶ。
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: foo-network-policy
namespace: foo
spec:
podSelector:
matchLabels:
name: app
▼ 空¶
空 ({}) を設定し、いずれの Pod も許可の対象としない。
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: foo-network-policy
namespace: foo
spec:
# 全てのPodを拒否する
podSelector: {}
policyTypes:
- Ingress
- Egress
policyTypes¶
許否ルールを適用する通信タイプを設定する。
デフォルト値は Ingress タイプが設定される。
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: foo-network-policy
namespace: foo
spec:
policyTypes:
# インバウンド通信に適用する
- Ingress
# アウトバウンド通信に適用する
- Egress
Job¶
.spec.activeDeadlineSeconds¶
▼ activeDeadlineSecondsとは¶
Job の試行の上限実行時間を設定する。
設定された時間を超過すると、エラーが返却される。
.spec.backoffLimit キーよりも優先される。
apiVersion: batch/v1
kind: Job
metadata:
name: foo-job
spec:
activeDeadlineSeconds: 20
.spec.backoffLimit¶
▼ backoffLimitとは¶
Job の試行の上限数を設定する。
apiVersion: batch/v1
kind: Job
metadata:
name: foo-job
spec:
backoffLimit: 4
.spec.parallelism¶
▼ parallelismとは¶
同時に起動できる Pod 数を設定する。
apiVersion: batch/v1
kind: Job
metadata:
name: foo-job
spec:
parallelism: 3
.spec.template¶
▼ templateとは¶
起動する Pod を設定する。
apiVersion: batch/v1
kind: Job
metadata:
name: foo-job
spec:
template:
spec:
containers:
- name: foo-alpine
image: alpine:latest
command:
- /bin/bash
- -c
args:
- echo Hello World
restartPolicy: OnFailure
nodeSelector:
node.kubernetes.io/nodetype: foo
.spec.ttlSecondsAfterFinished¶
▼ ttlSecondsAfterFinishedとは¶
Job が成功/失敗した場合の Job 自体の削除を有効化しつつ、その秒数を設定する。
失敗した Job が残り続けると、データポイント収集ツール (例:Prometheus) でメトリクスが記録され続け、アラートを送信し続けてしまう。
そのため、できるだけ Job は削除したほうがよい。
apiVersion: batch/v1
kind: Job
metadata:
name: foo-job
spec:
# Job自体の削除を有効化しつつ、Jobの実行が終了してから30秒後とする
ttlSecondsAfterFinished: 30
- https://kubernetes.io/docs/concepts/workloads/controllers/job/#clean-up-finished-jobs-automatically
- https://dev.appswingby.com/kubernetes/kubernetes-%E3%81%A7-job%E3%82%92%E8%87%AA%E5%8B%95%E5%89%8A%E9%99%A4%E3%81%99%E3%82%8Bttlsecondsafterfinished%E3%81%8Cv1-21%E3%81%A7beta%E3%81%AB%E3%81%AA%E3%81%A3%E3%81%A6%E3%81%84%E3%81%9F%E4%BB%B6/
Node¶
Kubernetes の実行時に自動的に作成される。
もし手動で作成する場合は、kubectl コマンドを実行することにより、そのときに --register-node キーを false とする必要がある。
LimitRange¶
.spec.limit¶
▼ Containerの場合¶
Namespace 内のコンテナのハードウェアリソースの上限必要サイズを設定する。
Pod の .spec.containers[*].resources キー配下に設定がなくとも、コンテナの実行時に自動的に挿入できる。
apiVersion: v1
kind: LimitRange
metadata:
name: foo-limit-range
namespace: foo
spec:
limits:
- max:
cpu: "500m"
min:
cpu: "200m"
type: Container
PersistentVolume¶
.spec.accessModes¶
▼ accessModesとは¶
ボリュームへの認可スコープを設定する。
▼ ReadWriteMany¶
ボリュームに対して、複数の Node から読み出し/書き込み可能にする。
Node 間で DB を共有したい場合に使用する。
*実装例*
apiVersion: v1
kind: PersistentVolume
metadata:
name: foo-persistent-volume
spec:
accessModes:
- ReadWriteMany
▼ ReadOnlyMany¶
ボリュームに対して、複数の Node から読み出しでき、また単一の Node のみから書き込み可能にする。
Node 間で読み出し処理のみ DB を共有したい場合に使用する。
*実装例*
apiVersion: v1
kind: PersistentVolume
metadata:
name: foo-persistent-volume
spec:
accessModes:
- ReadOnlyMany
▼ ReadWriteOnce¶
ボリュームに対して、単一の Node からのみ読み出し/書き込み可能にする。
もし Node に Pod のインスタンスが複数ある場合、ReadWriteOnce であっても複数の Pod から読み込み/書き込みがある。
*実装例*
apiVersion: v1
kind: PersistentVolume
metadata:
name: foo-persistent-volume
spec:
accessModes:
- ReadWriteOnce
.spec.capacity¶
▼ capacityとは¶
ストレージの最大サイズを設定する。
*実装例*
apiVersion: v1
kind: PersistentVolume
metadata:
name: foo-persistent-volume
spec:
capacity:
storage: 10G
.spec.hostPath¶
▼ hostPathとは¶
PersistentVolume の一種である HostPath Volume を作成する。
Volume の一種である Pod による HostPath Volume とは区別すること。
▼ path¶
Node 側のマウント元のディレクトリを設定する。
Pod のマウントポイントは、Pod の .spec.containers[*].volumeMount キーで設定する。
apiVersion: v1
kind: PersistentVolume
metadata:
name: foo-persistent-volume
spec:
hostPath:
path: /data/src/foo
▼ type¶
マウント方法を設定する。
apiVersion: v1
kind: PersistentVolume
metadata:
name: foo-persistent-volume
spec:
hostPath:
type: DirectoryOrCreate
path: /data/src/foo
.spec.local¶
▼ localとは¶
Node 上のストレージにボリュームを作成する。
.spec.nodeAffinity キーの設定が必須であり、Node を明示的に指定できる。
apiVersion: v1
kind: PersistentVolume
metadata:
name: foo-persistent-volume
spec:
local:
path: /data/src/foo
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- foo-node
.spec.mountOptions¶
▼ mountOptionsとは¶
*実装例*
apiVersion: v1
kind: PersistentVolume
metadata:
name: foo-persistent-volume
spec:
mountOptions:
- hard
.spec.nfs¶
▼ nfsとは¶
ホスト上であらかじめ NFS サーバーを起動しておく。
NFS サーバーのストレージ上にボリュームを作成する。
Node 内の Pod を、ホスト上の NFS サーバーにマウントする。
*実装例*
apiVersion: v1
kind: PersistentVolume
metadata:
name: foo-persistent-volume
spec:
nfs:
server: <NFSサーバーのIPアドレス>
path: /data/src/foo
.spec.nodeAffinity¶
▼ nodeAffinityとは¶
PersistentVolume の作成先とする Node を設定する。
▼ required.nodeSelectorTerms.matchExpressions¶
作成先の Node の .metadata.labels キーを指定するための条件 (In、NotIn、Exists) を設定する。
| 設定値 | 条件の説明 |
|---|---|
| In | 指定した metadata.labels キー配下に、指定した値を持つ。 |
| NotIn | 指定した metadata.labels キー配下に、指定した値を持たない。 |
| Exists | 指定した metadata.labels キーを持つ。 |
| DoesNotExists | 指定した metadata.labels キーを持たない。 |
*実装例*
apiVersion: v1
kind: PersistentVolume
metadata:
name: foo-persistent-volume
spec:
local:
path: /data/src/foo
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
# metadata.labelsキー
- key: node.kubernetes.io/nodetype
operator: In
# metadata.labelsキーの値
values:
- bar-group
# 開発環境であれば minikubeを指定する。
# - minikube
.spec.persistentVolumeReclaimPolicy¶
▼ persistentVolumeReclaimPolicyとは¶
PersistentVolume のライフサイクルを設定する。
▼ Delete¶
PersistentVolume を指定する PersistentVolumeClaim が削除された場合、PersistentVolume も自動的に削除する。
クラウドプロバイダーの PersistentVolume の動的プロビジョニングのために使用することが多い。
*実装例*
apiVersion: v1
kind: PersistentVolume
metadata:
name: foo-persistent-volume
spec:
persistentVolumeReclaimPolicy: Delete
▼ Recycle (非推奨)¶
PersistentVolume を指定する PersistentVolumeClaim が削除された場合、PersistentVolume 内のデータのみを削除し、PersistentVolume 自体は削除しない。
将来的に廃止予定のため、非推奨。
*実装例*
apiVersion: v1
kind: PersistentVolume
metadata:
name: foo-persistent-volume
spec:
persistentVolumeReclaimPolicy: Recycle
▼ Retain¶
PersistentVolume を指定する PersistentVolumeClaim が削除されたとしても、PersistentVolume は削除しない。
割り当てから解除された PersistentVolume は Released ステータスになる。
一度、Released ステータスになると、他の PersistentVolumeClaim からは指定できなくなる。
*実装例*
apiVersion: v1
kind: PersistentVolume
metadata:
name: foo-persistent-volume
spec:
persistentVolumeReclaimPolicy: Retain
.spec.storageClassName¶
▼ storageClassNameとは¶
ストレージクラス名を設定する。
特に、PersistentVolumeClaim が StorageClass に対応する PersistentVolume を要求するときに役立つ。
例えば、StorageClass に数種類のボリュームタイプ (standard、fast、slow、gp2 など) がある場合に、区別しやすくなる。
PersistentVolume にストレージクラス名を設定しない場合、これを要求できるのは、同じくストレージクラス名を持たない PersistentVolumeClaim だけである。
注意点として、もし異なる StorageClassName に変更したい場合は、PersistentVolume を作成し直す必要がある。
| クラス名 | 説明 |
|---|---|
"" (明示的な空文字) |
PersistentVolumeに対応するStorageClassがない場合 (PersistentVolumeを使用するが、StorageClassは使用しない場合) につける。 |
local |
PersistentVolumeに対応するStorageClassが中速中容量ストレージの場合につける。 |
standard |
PersistentVolumeに対応するStorageClassが中速中容量ストレージの場合につける。 |
fast |
PersistentVolumeに対応するStorageClassが高速小容量ストレージの場合につける。 |
slow |
PersistentVolumeに対応するStorageClassが低速大容量ストレージの場合につける。 |
*実装例*
apiVersion: v1
kind: PersistentVolume
metadata:
name: foo-persistent-volume
spec:
storageClassName: standard
PersistentVolumeClaim¶
.spec.accessModes¶
▼ accessModesとは¶
要求対象の PersistentVolume の accessMode を設定する。
*実装例*
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: foo-persistent-volume-claim
spec:
accessModes:
- ReadWriteMany
.spec.resources¶
▼ resourcesとは¶
要求する仮想ハードウェアの Kubernetes リソースを設定する。
▼ requests¶
要求対象の PersistentVolume の requests を設定する。
*実装例*
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: foo-persistent-volume-claim
spec:
resources:
requests:
storage: 2Gi
.spec.storageClassName¶
▼ storageClassNameとは¶
要求対象の PersistentVolume のストレージクラス名を設定する。
これを設定しない場合は、ストレージクラス名が standard の PersistentVolume を要求する。
注意点として、もし異なる StorageClassName に変更したい場合は、PersistentVolume を作成し直す必要がある。
*実装例*
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: foo-persistent-volume-claim
spec:
storageClassName: standard
Pod¶
.spec.affinity¶
▼ affinityとは¶
Pod のスケジューリング対象の Node を設定する。
.spec.tolerations キーとは反対の条件である。
.spec.nodeSelector キーと比較して、より複雑に条件を設定できる。
Deployment や Stateful でこれを使用する場合は、Pod のレプリカそれぞれが独立し、条件に合わせて kube-scheduler がスケジューリングさせる。
- https://kubernetes.io/docs/concepts/scheduling-eviction/assign-pod-node/#node-affinity
- https://www.devopsschool.com/blog/understanding-node-selector-and-node-affinity-in-kubernetes/
- https://hawksnowlog.blogspot.com/2021/03/namespaced-pod-antiaffinity-with-deployment.html#%E7%95%B0%E3%81%AA%E3%82%8B-namespace-%E9%96%93%E3%81%A7-podantiaffinity-%E3%82%92%E4%BD%BF%E3%81%86%E5%A0%B4%E5%90%88
.spec.affinity.nodeAffinity¶
▼ affinity.nodeAffinityとは¶
Node の .metadata.labels キーを指定することにより、kube-scheduler が Pod をスケジューリングさせる Node を設定する。
.spec.nodeSelector キーと比較して、より複雑に条件を設定できる。
Deployment や Stateful でこれを使用する場合は、Pod のレプリカそれぞれが独立し、kube-scheduler は条件に合わせてスケジューリングさせる。
複数の Node に同じ .metadata.labels キーを付与しておき、この Node 群を Node グループと定義すれば、特定の Node に Pod を作成するのみでなく Node グループ単位で Pod をスケジューリングさせられる。
- https://kubernetes.io/docs/concepts/scheduling-eviction/assign-pod-node/#node-affinity
- https://www.devopsschool.com/blog/understanding-node-selector-and-node-affinity-in-kubernetes/
- https://hawksnowlog.blogspot.com/2021/03/namespaced-pod-antiaffinity-with-deployment.html#%E7%95%B0%E3%81%AA%E3%82%8B-namespace-%E9%96%93%E3%81%A7-podantiaffinity-%E3%82%92%E4%BD%BF%E3%81%86%E5%A0%B4%E5%90%88
▼ requiredDuringSchedulingIgnoredDuringExecution (ハード)¶
条件に合致する Node にのみ Pod をスケジューリングさせる。
もし条件に合致する Node がない場合、Pod のスケジューリングを待機し続ける。
共通する SchedulingIgnoredDuringExecution の名前の通り、.spec.affinity キーによるスケジューリングの制御は新しく作成される Pod にしか適用できず、すでに実行中の Pod には適用できず、再スケジューリングさせないといけない。
Pod が削除された後に Node の .metadata.labels キーの値が変更されたとしても、一度スケジューリングされた Pod が .spec.affinity キーの設定で再スケジューリングされることはない。
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: app
image: app:1.0.0
ports:
- containerPort: 8080
affinity:
nodeAffinity:
# ハードアフィニティ
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
# PodをスケジューリングさせたいNodeのmetadata.labelsキー
# ここでNodeグループのキーを指定しておけば、Nodeグループ単位でスケジューリングさせられる。
- key: node.kubernetes.io/nodetype
operator: In
# 指定した値をキーに持つNodeに、Podをスケジューリングさせる。
values:
- app
▼ preferredDuringSchedulingIgnoredDuringExecution (ソフト)¶
条件に合致する Node を優先して Pod をスケジューリングさせる。
もし条件に合致する Node がない場合でも、それを許容する。そのうえで、条件に合致しない Node へ Pod をスケジューリングさせる。
条件に合致しない Node の探索で重みづけルールを設定できる。
共通する SchedulingIgnoredDuringExecution の名前の通り、.spec.affinity キーによるスケジューリングの制御は新しく作成される Pod にしか適用できない。
すでに実行中の Pod には適用できず、再スケジューリングさせないといけない。
Pod が削除された後に Node の .metadata.labels キーの値が変更されたとしても、一度スケジューリングされた Pod が .spec.affinity キーの設定で再スケジューリングされることはない。
.spec.affinity.podAffinity¶
▼ affinity.podAffinityとは¶
Node 内の Pod を、.metadata.labels キーで指定することにより、その Pod と同じ Node 内に、新しい Pod をスケジューリングさせる。
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: app
image: app:1.0.0
ports:
- containerPort: 8080
affinity:
podAffinity:
# ハードアフィニティー
requiredDuringSchedulingIgnoredDuringExecution:
# 分散単位
- topologyKey: kubernetes.io/hostname
labelSelector:
- matchExpressions:
# Podのmetadata.labelsキー
- key: app.kubernetes.io/name
operator: In
# 指定した値をキーに持つPodと同じNodeに、Podをスケジューリングさせる。
values:
- bar-gin
preferredDuringSchedulingIgnoredDuringExecution の場合、podAffinityTerm キーや preference キーが必要である。
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: app
image: app:1.0.0
ports:
- containerPort: 8080
affinity:
podAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
topologyKey: kubernetes.io/hostname
labelSelector:
- matchExpressions:
- key: app.kubernetes.io/name
operator: In
values:
- bar-gin
▼ requiredDuringSchedulingIgnoredDuringExecution (ハード)¶
.spec.affinity.nodeAffinity キーの Pod 版である。
▼ preferredDuringSchedulingIgnoredDuringExecution (ソフト)¶
.spec.affinity.nodeAffinity キーの Pod 版である。
.spec.affinity.podAntiAffinity¶
▼ affinity.podAntiAffinityとは¶
.metadata.labels キーを持つ Node とは異なる Node 内に、その Pod をスケジューリングさせる。
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: app
image: app:1.0.0
ports:
- containerPort: 8080
affinity:
podAntiAffinity:
# ハードアフィニティー
requiredDuringSchedulingIgnoredDuringExecution:
# Podの分散単位
- topologyKey: topology.kubernetes.io/zone
labelSelector:
- matchExpressions:
# Podのmetadata.labelsキー
- key: app.kubernetes.io/name
operator: In
# 指定した値をキーに持つPodとは異なるNodeに、Podをスケジューリングさせる。
values:
- bar-gin
preferredDuringSchedulingIgnoredDuringExecution の場合、podAffinityTerm キーや preference キーが必要である。
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: app
image: app:1.0.0
ports:
- containerPort: 8080
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
topologyKey: topology.kubernetes.io/zone
labelSelector:
- matchExpressions:
- key: app.kubernetes.io/name
operator: In
values:
- bar-gin
*スケジューリング例*
もし、コピーする Pod の名前を設定した場合、Pod のレプリカ同士は同じ Node にスケジューリングされることを避ける。
また、分散単位に topology.kubernetes.io/zone を設定しているため、各 AZ に Pod をバラバラにスケジューリングさせる。
結果として、各 AZ の Node に Pod が 1 個ずつスケジューリングされるようになる。
apiVersion: apps/v1
kind: Deployment
metadata:
name: foo-deployment
spec:
selector:
matchLabels:
app.kubernetes.io/name: foo-pod
replicas: 3
template:
metadata:
labels:
app.kubernetes.io/name: foo-pod
spec:
containers:
- name: app
image: app:1.0.0
ports:
- containerPort: 8080
affinity:
podAntiAffinity:
# ハードアフィニティー
requiredDuringSchedulingIgnoredDuringExecution:
# Podの分散単位
- topologyKey: topology.kubernetes.io/zone
labelSelector:
- matchExpressions:
# Podのmetadata.labelsキー
- key: app.kubernetes.io/name
operator: In
# 指定した値をキーに持つPodとは異なるNodeに、Podをスケジューリングさせる。
values:
# 自身がコピーするPodの名前
- app
▼ requiredDuringSchedulingIgnoredDuringExecution (ハード)¶
.spec.affinity.nodeAffinity キーのアンチ Pod 版である。
▼ preferredDuringSchedulingIgnoredDuringExecution (ソフト)¶
.spec.affinity.nodeAffinity キーのアンチ Pod 版である。
▼ node affinity conflict¶
ただし、AWS のスポットインスタンスと相性が悪く、特定の AZ でしか Node が作成されなかった場合に、以下のようなエラーになってしまう。
N node(s) had volume node affinity conflict, N node(s) didn't match Pod's node affinity/selector
.spec.containers¶
▼ containersとは¶
Pod 内で起動するコンテナを設定する。
Pod を Deployment や ReplicaSet に紐付けず、単体で使用することは非推奨である。
▼ name、image¶
Pod を構成するコンテナの名前、ベースイメージを設定する。
*実装例*
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: app
image: app:1.0.0
ports:
- containerPort: 8080
Amazon ECR からコンテナイメージをプルする場合は、以下の通りである。
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: app
image: <AWSアカウントID>.dkr.ecr.ap-northeast-1.amazonaws.com/foo-repository/app:1.0.0
ports:
- containerPort: 8080
▼ env¶
環境変数を設定する。
*実装例*
status.podIP から自身の IP アドレスを取得し、MY_POD_IP という名前で設定する。
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: app
image: app:1.0.0
ports:
- containerPort: 8080
env:
- name: MY_POD_IP
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: status.podIP
▼ envFrom¶
.spec.volumes.secret キー (ファイルをコンテナに設定する) とは異なり、Secret や ConfigMap からコンテナに環境変数を出力する。
*実装例*
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: app
image: app:1.0.0
ports:
- containerPort: 8080
envFrom:
- secretRef:
# 環境変数としてコンテナに出力するSecret
name: foo-secret
- configMapRef:
# 環境変数としてコンテナに出力するConfigMap
name: foo-config-map
▼ ports¶
コンテナが待ち受けるポート番号を、仕様として設定する。
単なる仕様であり、ドキュメントとしての役割がある。
コンテナがポート番号を公開してさえいれば、.spec.containers[*].ports キーは設定しなくとも問題ない。
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: app
image: app:1.0.0
# 待ち受けるポート番号の仕様
ports:
# コンテナがポート番号を公開していれば、設定しなくてもポートは公開されている
- containerPort: 8080
▼ imagePullPolicy¶
イメージのプルのルールを設定する。
| オプション | 説明 |
|---|---|
| IfNotPresent | Node上にコンテナイメージのキャッシュがあればこれを使用する。なければイメージリポジトリからぷるする。 |
| Always | Node上のキャッシュを使用せず、常にイメージリポジトリからコンテナイメージをプルする。 |
| Never | Node上にコンテナイメージのキャッシュを常にを使用する。 |
*実装例*
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: app
image: app:1.0.0
imagePullPolicy: IfNotPresent
ports:
- containerPort: 8080
▼ resources.requests、resources.limits¶
Node 全体のハードウェアリソースを分母として、Pod 内のコンテナが要求するリソースの下限/上限必要サイズを設定する。
各 Pod は Node 内のハードウェアリソース (cpu、memory、ephemeral-storage) を奪い合っており、Node が複数ある場合、kube-scheduler は requests 値以上の余剰がある Node 上に Pod のスケジューリングを実行する。
このとき kube-scheduler は、コンテナの resource キーの値に基づいて、どの Node に Pod を作成するかを決めている。
同じ Pod 内に resources キーを設定したコンテナが複数ある場合、下限/上限の必要サイズを満たしているか否かの判定は、同じ Pod 内のコンテナの要求サイズの合計値に基づく。
| キー名 | 説明 | 補足 |
|---|---|---|
requests |
ハードウェアリソースの下限必要サイズを設定する。 | ・高くしすぎると、そのPod内のコンテナがハードウェアリソースを常に要求するため、他のPodがスケーリングしにくくなる。 ・もし、設定値がNodeのハードウェアリソース以上の場合、コンテナは永遠に起動しない。 ・https://qiita.com/jackchuka/items/b82c545a674975e62c04#cpu ・もし、これを設定しない場合は、コンテナが使用できるハードウェアリソースの下限がなくなる。そのため、Kubernetesが重要なPodにリソースを必要最低限しか割かず、性能が低くなる可能性がある。 |
limits |
ハードウェアリソースの上限必要サイズを設定する。 | ・低くしすぎると、コンテナにハードウェアリソースを割り当てられないため、性能が常時悪くなる。 ・もし、コンテナが上限値以上のハードウェアリソースを要求すると、CPUの場合はPodは削除されずに、コンテナのスロットリング (起動と停止を繰り返す) が起こる。一方でメモリの場合は、OOMキラーによってPodのプロセスが削除され、Podは再作成される。 ・https://blog.mosuke.tech/entry/2020/03/31/kubernetes-resource/ ・もし、これを設定しない場合は、コンテナが使用できるハードウェアリソースの上限がなくなる。そのため、Kubernetesが重要でないPodにリソースを割いてしまう可能性がある。 ・https://kubernetes.io/docs/tasks/configure-pod-container/assign-cpu-resource/#if-you-do-not-specify-a-cpu-limit ・https://kubernetes.io/docs/tasks/configure-pod-container/assign-memory-resource/#if-you-do-not-specify-a-memory-limit |
補足として、Node 全体のハードウェアリソースは、kubectl describe コマンドから確認できる。
$ kubectl describe node <Node名>
...
Capacity:
attachable-volumes-aws-ebs: 20
cpu: 4 # NodeのCPU
ephemeral-storage: 123456789Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 1234567Ki # Nodeのメモリー
pods: 10 # スケジューリング可能なPodの最大数
Allocatable:
attachable-volumes-aws-ebs: 20
cpu: 3920m # 実際に使用可能なCPU
ephemeral-storage: 123456789
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 1234567Ki # 実際に使用可能なメモリ
pods: 10
...
▼ resources.requests/limits.<ハードウェアリソース>¶
| ハードウェアリソース名 | 単位 | |
|---|---|---|
cpu |
コンテナのCPU | m:millicores (1m = 1 ユニット = 0.001 コア) |
memory |
コンテナのメモリ | Mi:mebibyte (1Mi = 1.04858MB) |
ephemeral-storage |
EmptyDir Volume、ログ、ローカルディスクへの書き込み | Mi:mebibyte |
*実装例*
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: app
image: app:1.0.0
resources:
# 下限必要サイズ
requests:
cpu: 250m
ephemeral-storage: 500Mi
memory: 64Mi
# 上限サイズ
limits:
cpu: 500m
ephemeral-storage: 2Gi
memory: 512Mi
- name: istio-proxy
...
各コンテナの実際のハードウェアリソース消費量を確認する場合は、kubectl top コマンドを使用する。
『(実測値) ÷ (メモリ上限値) × 100』で計算できる。
$ kubectl top pod --container -n foo-namespace
POD NAME CPU(cores) MEMORY(bytes)
foo-pod app 1m 19Mi # 19Mi ÷ 128Mi × 100 = 14%
foo-pod istio-proxy 5m 85Mi
▼ volumeMounts¶
Pod 内のコンテナのマウントポイントを設定する。
パスは相対パスではなく絶対パスで指定する。
.spec.volumes キーで設定されたボリュームのうちから、コンテナにマウントするボリュームを設定する。
Node 側のマウント元のディレクトリは、PersistentVolume の .spec.hostPath キーで設定する。
volumeMount という名前であるが、『ボリュームマウント』を実行するわけではなく、Volume や PersistentVolume で設定された任意のマウントを実行できることに注意する。
*実装例*
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: app
image: app:1.0.0
ports:
- containerPort: 8080
volumeMounts:
- name: app-volume
# 絶対パスにする
mountPath: /go/src
volumes:
- name: app-volume
persistentVolumeClaim:
claimName: foo-persistent-volume-claim
*実装例*
Secret の名前を指定できる。
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: app
image: app:1.0.0
ports:
- containerPort: 8080
volumeMounts:
- name: app-volume
# 絶対パスにする
mountPath: /go/src
volumes:
- name: app-volume
secret:
secretName: app-secret
*実装例*
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: app
image: app:1.0.0
ports:
- containerPort: 8080
# 資格情報ファイルをマウントする
volumeMounts:
- name: credentials-volume
# 絶対パスにする
mountPath: /credentials
env:
# Google Cloudの資格情報のパスを設定する
- name: GOOGLE_APPLICATION_CREDENTIALS
value: /credentials/google_cloud_credentials.json
volumes:
- name: credentials-volume
secret:
secretName: app-secret
---
apiVersion: v1
kind: Secret
metadata:
name: app-secret
type: Opaque
data:
google_cloud_credentials.json: *****
▼ workingDir¶
コンテナの作業ディレクトリを設定する。
ただし、作業ディレクトリの設定はアプリケーション側の責務のため、Kubernetes で設定するよりも Dockerfile で定義したほうがよい。
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: app
image: app:1.0.0
ports:
- containerPort: 8080
workingDir: /go/src
.spec.containers[*].livenessProbe¶
▼ livenessProbeとは¶
kubelet がヘルスチェックを実行することで、コンテナが正常に動作しているか確認する。
注意点として、LivenessProbe ヘルスチェックの間隔が短すぎると、kubelet に必要以上の負荷がかかる。
terminationGracePeriodSeconds に関しては、.spec.terminationGracePeriodSeconds キーで Pod 単位での待機時間を設定できる。
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: foo-app-springboot
image: foo-app-springboot:1.0.0
livenessProbe:
httpGet:
port: 8080
# SpringBoot製Javaアプリケーションのlivenessエンドポイント
path: /actuator/health/liveness
scheme: HTTP
# 各設定のデフォルト値を示す
initialDelaySeconds: 0
periodSeconds: 10
timeoutSeconds: 1
successThreshold: 1
failureThreshold: 3
terminationGracePeriodSeconds: 30
terminationGracePeriodSeconds: 30
▼ exec¶
コンテナの LivenessProbe ヘルスチェックで、任意のコマンドによるヘルスチェックを実行する。
終了コード 0 なら成功である。
LivenessProbe が対応可能なプロトコル (HTTP、TCP、gRPC による HTTP) 以外で、ヘルスチェックを実行したい場合に役立つ。
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: app
image: app:1.0.0
livenessProbe:
exec:
command:
- source
- healthcheck.sh
▼ httpGet¶
コンテナの LivenessProbe ヘルスチェックで、L7 チェックを実行する。
200 ステータスから 399 ステータスまでの間なら成功である。
具体的には、コンテナの指定したエンドポイントに GET メソッドで HTTP リクエストを送信し、レスポンスのステータスコードを検証する。
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: app
image: app:1.0.0
livenessProbe:
httpGet:
port: 80
path: /healthcheck
# またはHTTPS
scheme: HTTP
自身のアプリケーションではエンドポイントを実装する必要があるが、OSS ではすでに用意されていることが多い。
| ツール | エンドポイント |
|---|---|
| Alertmaanger | /-/healthy |
| Grafana | /healthz |
| Kiali | /kiali/healthz |
| Prometheus | /-/healthy |
| ... | ... |
▼ failureThreshold¶
デフォルト値は 3 である。
コンテナの LivenessProbe ヘルスチェックが失敗したとみなす試行回数を設定する。
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: app
image: app:1.0.0
livenessProbe:
failureThreshold: 5
▼ initialDelaySecond¶
デフォルト値は 0 である。
初回の LivenessProbe ヘルスチェックを開始するまでの待機時間を設定する。
この時間を過ぎてもコンテナの LivenessProbe ヘルスチェックが失敗する場合、Pod はコンテナを再起動する。
設定した時間が短すぎると、Pod がコンテナの起動を待てずに再起動を繰り返してしまう (デフォルト値の 0 は短すぎる) 。
一方で、設定した時間が長すぎると、Pod の作成開始から完了まで時間がかかりすぎてしまう。
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: app
image: app:1.0.0
livenessProbe:
# 初回以降のLivenessProbeヘルスチェックを実行するまでに5秒間待機する。
initialDelaySeconds: 10
▼ periodSeconds¶
デフォルト値は 10 である。
コンテナの LivenessProbe ヘルスチェックの試行当たりの間隔を設定する。
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: app
image: app:1.0.0
livenessProbe:
# 5秒ごとにLivenessProbeヘルスチェックを実行する。
periodSeconds: 5
▼ successThreshold¶
デフォルト値は 1 である。
LivenessProbe ヘルスチェックの失敗後のリトライで、成功と判定する最小試行回数を設定する。
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: app
image: app:1.0.0
livenessProbe:
successThreshold: 1
▼ tcpSocket¶
コンテナの LivenessProbe ヘルスチェックで、L4 チェックを実行する。
具体的には、コンテナに TCP スリーウェイハンドシェイクを実行し、TCP 接続を確立できるかを検証する。
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: app
image: app:1.0.0
livenessProbe:
tcpSocket:
port: 8080
▼ terminationGracePeriodSeconds¶
デフォルト値は Pod 単位の .spec.terminationGracePeriodSeconds キーを継承し、30 である。
コンテナの終了プロセスを開始するまで待機時間を設定する。
この時間を超えてもコンテナを終了できていない場合は、コンテナを強制的に停止する。
設定した時間が長すぎると、Pod 全体の終了プロセスに時間がかかり、Pod の削除までに時間がかかりすぎてしまう。
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: app
image: app:1.0.0
livenessProbe:
terminationGracePeriodSeconds: 10
terminationGracePeriodSeconds: 45
▼ timeoutSeconds¶
デフォルト値は 1 である。
コンテナの LivenessProbe ヘルスチェックのタイムアウト時間を設定する。
この時間を過ぎてもコンテナの LivenessProbe ヘルスチェックが失敗する場合、Pod はコンテナを再起動する。
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: app
image: app:1.0.0
livenessProbe:
# LivenessProbeヘルスチェックのタイムアウト時間を30秒とする。
timeoutSeconds: 10
.spec.containers[*].startupProbe¶
▼ startupProbeとは¶
kubelet がヘルスチェックを実行することで、アプリケーションの起動が完了したかを確認する。
ReadinessProbe よりも先に実行される。
言語やフレームワークによっては StartupProbe 用のエンドポイントが提供されていない場合があり、ReadinessProbe 用のエンドポイントで代用する。
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: foo-app-springboot
image: foo-app-springboot:1.0.0
startupProbe:
httpGet:
port: 8080
# SpringBoot製Javaアプリケーションののstartupエンドポイント
path: /actuator/startup
initialDelaySeconds: 10
periodSeconds: 10
timeoutSeconds: 10
successThreshold: 1
failureThreshold: 5
terminationGracePeriodSeconds: 10
.spec.containers[*].readinessProbe¶
▼ readinessProbeとは¶
kubelet がヘルスチェックを実行することで、コンテナがトラフィックを処理可能かを確認する。
terminationGracePeriodSeconds に関しては、.spec.terminationGracePeriodSeconds キーで Pod 単位での待機時間を設定できる。
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: foo-app-springboot
image: foo-app-springboot:1.0.0
readinessProbe:
httpGet:
port: 8080
# SpringBoot製JavaアプリケーションのReadinessエンドポイント
path: /actuator/health/readiness
scheme: HTTP
# 各設定のデフォルト値を示す
initialDelaySeconds: 0
periodSeconds: 10
timeoutSeconds: 1
successThreshold: 1
failureThreshold: 3
terminationGracePeriodSeconds: 30
terminationGracePeriodSeconds: 30
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: foo-app-grpc
image: foo-app-grpc:1.0.0
readinessProbe:
tcpSocket:
port: 5000
# 各設定のデフォルト値を示す
initialDelaySeconds: 0
periodSeconds: 10
timeoutSeconds: 1
successThreshold: 1
failureThreshold: 3
terminationGracePeriodSeconds: 30
terminationGracePeriodSeconds: 30
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: foo-app-grpc
image: foo-app-grpc:1.0.0
readinessProbe:
grpc:
port: 8080
# 各設定のデフォルト値を示す
initialDelaySeconds: 0
periodSeconds: 10
timeoutSeconds: 1
successThreshold: 1
failureThreshold: 3
terminationGracePeriodSeconds: 30
terminationGracePeriodSeconds: 30
コンテナが起動してもトラフィックを処理できるようになるまで時間がかかる場合や、問題の起きたコンテナへトラフィックを流さない場合に役立つ。例えば、Java のウォームアップ完了まで、Nginx の最初の設定ファイル読み込み完了まで、MySQL の最初の接続受信準備完了までなどである。
注意点として、ReadinessProbe の間隔が短すぎると、kubelet に必要以上の負荷がかかる。
そのため、READY は 0 で、STATUS は Running になる。
$ kubectl get pod -n foo-namespace
NAME READY STATUS RESTARTS AGE
foo-pod 0/1 Running 0 14m
bar-pod 0/1 Running 0 14m
Readiness probe failed: Get "http://*.*.*.*:*/ready": dial tcp *.*.*.*:*: connect: connection refused
- https://www.ianlewis.org/jp/kubernetes-health-check
- https://amateur-engineer-blog.com/livenessprobe-readinessprobe/#toc4
- https://kodekloud.com/community/t/what-is-the-meaning-for-a-pod-with-ready-0-1-and-state-running/21660
- https://spring.io/blog/2020/03/25/liveness-and-readiness-probes-with-spring-boot
▼ exec¶
コンテナの LivenessProbe ヘルスチェックで、任意のコマンドのヘルスチェックを実行する。
終了コード 0 なら成功である。
LivenessProbe が対応可能なプロトコル (HTTP、TCP、gRPC による HTTP) 以外で、ヘルスチェックを実行したい場合に役立つ。
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: app
image: app:1.0.0
readinessProbe:
exec:
command:
- source
- healthcheck.sh
▼ httpGet¶
コンテナの ReadinessProbe ヘルスチェックで、L7 チェックを実行する。
200 ステータスから 399 ステータスまでの間なら成功である。
具体的には、コンテナの指定したエンドポイントに GET メソッドで HTTP リクエストを送信し、レスポンスのステータスコードを検証する。
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: app
image: app:1.0.0
readinessProbe:
httpGet:
port: 80
path: /healthcheck
# またはHTTPS
scheme: HTTP
▼ failureThreshold¶
デフォルト値は 3 である。
ReadinessProbe ヘルスチェックが失敗したとみなす試行回数を設定する。
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: app
image: app:1.0.0
readinessProbe:
failureThreshold: 5
▼ initialDelaySeconds¶
デフォルト値は 0 である。
初回の ReadinessProbe ヘルスチェックを開始するまでの待機時間を設定する。
この時間を過ぎてもコンテナの ReadinessProbe ヘルスチェックが失敗する場合、Pod はコンテナを再起動する。
設定した時間が短すぎると、Pod がコンテナの起動を待てずに再起動を繰り返してしまう (デフォルト値の 0 は短すぎる) 。
一方で、設定した時間が長すぎると、Pod の作成開始から完了まで時間(つまり、リリースの作業時間)がかかりすぎてしまう。
例えば、gRPC サーバーであれば基本的には 1 秒以内で起動するため、initialDelaySeconds は 5 ほどでよい。
Workload を何度かリスタートし、問題なく起動できれば調整は完了である。
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: app
image: app:1.0.0
readinessProbe:
initialDelaySeconds: 10
▼ periodSeconds¶
デフォルト値は 10 である。
ReadinessProbe ヘルスチェックの試行当たりの間隔を設定する。
適正値は 10 秒ほどでよい。
Workload を何度かリスタートし、問題なく起動できれば調整は完了である。
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: app
image: app:1.0.0
readinessProbe:
periodSeconds: 5
▼ successThreshold¶
デフォルト値は 1 である。
ReadinessProbe ヘルスチェックの失敗後のリトライで、成功と判定する最小試行回数を設定する。
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: app
image: app:1.0.0
readinessProbe:
successThreshold: 1
▼ tcpSocket¶
ReadinessProbe ヘルスチェックで、L4 チェックを実行する。
コンテナに TCP スリーウェイハンドシェイクを実行し、TCP 接続を確立できるかを検証する。
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: app
image: app:1.0.0
readinessProbe:
tcpSocket:
port: 3306
▼ terminationGracePeriodSeconds¶
デフォルト値は Pod 単位の .spec.terminationGracePeriodSeconds キーを継承し、30 である。
コンテナの終了プロセスを開始するまで待機時間を設定する。
この時間を超えても Pod を終了できていない場合は、コンテナを強制的に停止する。
設定した時間が長すぎると、Pod 全体の終了プロセスに時間がかかり、Pod の削除までに時間がかかりすぎてしまう。
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: app
image: app:1.0.0
readinessProbe:
terminationGracePeriodSeconds: 10
terminationGracePeriodSeconds: 45
▼ timeoutSeconds¶
デフォルト値は 1 である。
コンテナの ReadinessProbe ヘルスチェックのタイムアウト時間を設定する。
この時間を過ぎてもコンテナの ReadinessProbe ヘルスチェックが失敗する場合、Pod はコンテナを再起動する。
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: app
image: app:1.0.0
readinessProbe:
# ReadinessProbeヘルスチェックのタイムアウト時間を30秒とする。
timeoutSeconds: 10
.spec.containers[*].securityContext¶
▼ securityContextとは¶
Pod 内の特定のコンテナに対して、認可スコープを設定する。
オプションは、.spec.securityContext キーと同じである。
.spec.containers[*].volumeMounts¶
▼ volumeMountsとは¶
Pod の Volume 内のディレクトリをコンテナにマウントする。
パスは相対パスではなく絶対パスで指定する。
▼ subPath¶
Pod の Volume 内のサブディレクトリを指定し、マウント可能にする。
これを指定しない場合、Volume のルートディレクトリ配下をコンテナへマウントすることになる。
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: app
image: app:1.0.0
volumeMounts:
- name: app-volume
# foo-volumeにあるwwwディレクトリを指定する
subPath: www
# コンテナのvarディレクトリをマウントする
mountPath: /var
volumes:
- name: app-volume
emptyDir: {}
ディレクトリではなく、ファイルを指定できる。
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: app
image: app:1.0.0
volumeMounts:
- name: app-volume
# foo-volumeにあるwww.confファイルを指定する
subPath: www.conf
# コンテナに/etc/www.confファイルとしてマウントする
mountPath: /etc/www.conf
volumes:
- name: app-volume
emptyDir: {}
.spec.enableServiceLinks¶
▼ enableServiceLinks¶
Service の宛先情報 (IP アドレス、プロトコル、ポート番号) に関する環境変数を Pod 内に出力するかどうかを設定する。
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: app
image: app:1.0.0
enableServiceLinks: false
.spec.hostname¶
▼ hostnameとは¶
Pod のホスト名を設定する。
また、.spec.hostname キーが設定されていないときは、.metadata.name がホスト名として使用される。
*実装例*
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: app
image: app:1.0.0
hostname: foo-pod
.spec.hostNetwork¶
▼ hostNetworkとは¶
Pod が、自身の稼働する Node のネットワークにリクエストを送信できるかどうかを設定する。
ユーザーが使用するうユースケースは少なく、例えば Node Exporter の Pod で使用される。
apiVersion: v1
kind: Pod
metadata:
name: foo-node-exporter
spec:
containers:
- name: foo-node-exporter
image: prom/node-exporter:1.0.0
hostNetwork: true
.spec.imagePullSecrets¶
▼ imagePullSecretsとは¶
プライベートイメージリポジトリからコンテナイメージをプルするため、プライベートイメージリポジトリの資格情報を持つ Secret を設定する。
別途、ServiceAccount の .imagePullSecrets キーでも同じ Secret を指定しておき、この ServiceAccount を Pod に紐付ける。
これにより、Pod は Secret にあるプライベートリポジトリの資格情報を使用できるようになる。
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: app
image: private-app:1.0.0 # プライベートプライベートイメージリポジトリ
imagePullSecrets:
- name: app-repository-credentials-secret # プライベートイメージリポジトリの資格情報を持つSecret
- https://kubernetes.io/docs/concepts/containers/images/#specifying-imagepullsecrets-on-a-pod
- https://kubernetes.io/docs/tasks/configure-pod-container/pull-image-private-registry/#create-a-pod-that-uses-your-secret
- https://medium.com/makotows-blog/kubernetes-private-registry-tips-image-pullsecretse-20dfb808dfc-e20dfb808dfc
.spec.initContainers¶
▼ initContainersとは¶
.spec.containers キーで設定したコンテナよりも先に起動するコンテナ (InitContainer) を設定する。
依存先コンテナ (例:DB コンテナ、インメモリ DB コンテナ) の待機処理、依存ツールやサーバー証明書のインストール処理などのために使用する。
▼ command¶
実行するコマンドを設定する。
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: app
image: app:1.0.0
ports:
- containerPort: 8080
volumeMounts:
- name: app-volume
mountPath: /go/src
initContainers:
- name: readiness-check-redis
image: busybox:1.28
# StatefulSetのインメモリDBコンテナの6379番ポートに通信できるまで、本Podのappコンテナの起動開始を待機する。
# StatefulSetでReadinessProbeヘルスチェックを設定しておけば、これのPodがREADYになるまでncコマンドは成功しないようになる。
command:
- /bin/bash
- -c
args:
- |
until nc -z inmemory-db 6379; do
echo waiting for inmemory-db;
sleep 2;
done
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: foo-db
image: redis:8.0
ports:
- containerPort: 6379
volumeMounts:
- name: foo-inmemory-db-volume
mountPath: /var/lib
volumes:
- name: foo-inmemory-db-volume
emptyDir: {}
▼ restartPolicy¶
Always 値を設定することで、サイドカーコンテナを作成できる。
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: app
image: app:1.0.0
ports:
- containerPort: 8080
volumeMounts:
- name: app-volume
mountPath: /go/src
initContainers:
- name: sidecar
image: proxy:1.0.0
restartPolicy: Always
.spec.priorityClassName¶
▼ priorityClassNameとは¶
Pod のスケジューリングの優先度を設定する。
何らかの理由 (例:ハードウェアリソース不足など) でより優先度の高い Pod をスケジューリングさせられない場合、より優先度の低い Pod を Node から退去させ、優先度の高い Pod をスケジューリングさせる。
| 設定値 | 優先度 |
|---|---|
system-node-critical、system-cluster-critical |
最優先 |
high |
|
low-non-preemptible |
|
low |
後回し |
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: app
image: app:1.0.0
priorityClassName: system-node-critical
▼ DaemonSet配下のPod¶
DaemonSet 配下の Pod は、デフォルトですべての Node でスケジューリングされるようになっている。
ただし何らかの理由 (例:ハードウェアリソース不足など) で、特定の Node で DaemonSet 配下の Pod をスケジューリングさせられないことがある。
他の Pod よりスケジューリングの優先度を上げるために、DaemonSet 配下の Pod には必ず、system-node-critical の PriorityClassName を設定しておく。
.spec.nodeSelector¶
▼ nodeSelectorとは¶
Pod のスケジューリング対象とする Node を設定する。
.spec.affinity キーと比較して、より単純に条件を設定できる。
複数の Node に同じ .metadata.labels キーを付与しておき、この Node 群を Node グループと定義すれば、特定の Node に Pod を作成するのみでなく Node グループに Pod を作成できる。
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: app
image: app:1.0.0
nodeSelector:
node.kubernetes.io/nodetype: foo
▼ DaemonSet配下のPod¶
DaemonSet では、特定の Node に Pod をスケジューリングさせられる。
▼ nodeSelectorとaffinittyの両方設定¶
.spec.nodeSelector キーと .spec.affinity キーの両方を設定できる。
両方を設定した場合、両方を満たした Node に Pod をスケジューリングさせられる。
.spec.restartPolicy¶
▼ restartPolicyとは¶
Pod 内のコンテナのライフサイクルの再起動ポリシーを設定する。
▼ Always¶
コンテナが停止した場合、これが正常 (終了ステータス 0) か異常 (終了ステータス 1) かを問わず、常にコンテナを再起動する。
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: app
image: app:1.0.0
restartPolicy: Always
▼ Never¶
コンテナが停止した場合、コンテナを再起動しない。
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: app
image: app:1.0.0
restartPolicy: Never
▼ OnFailure¶
コンテナが停止した場合、これが異常 (終了ステータス 1) の場合にのみ、常にコンテナを再起動する。
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: app
image: app:1.0.0
restartPolicy: OnFailure
.spec.securityContext¶
▼ securityContextとは¶
Pod 内のすべてのコンテナに対して、認可スコープを設定する。
▼ runAsUser¶
コンテナのプロセスのユーザーID を設定する。
コンテナがユーザーを提供していない場合、あらじかじめユーザーを作成する必要がある。
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: app
image: app:1.0.0
securityContext:
runAsUser: 999
▼ runAsGroup¶
コンテナのプロセスのグループ ID を設定する。
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: app
image: app:1.0.0
securityContext:
runAsGroup: 3000
▼ runAsNonRoot¶
コンテナを特権モード (root 権限) で実行できないようにする。
もしこれを設定したコンテナが root 権限の実行ユーザーを使用しようとすると、コンテナの起動に失敗する。
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: app
image: app:1.0.0
securityContext:
runAsNonRoot: true
▼ fsGroup¶
Pod 内のコンテナ内のファイルに以下を実行する。
- 指定した番号のユーザーグループを作成する
- ファイルのユーザーグループ権限を指定したユーザーグループ番号に設定する
- ファイルのアクセス権限を
0660に設定する
設定しない場合、ボリュームのファイルの権限は root ユーザー (コンテナのデフォルトユーザー) になる。
例えば、999 にすれば、999 というユーザーグループが作成され、999 番グループしかファイルを利用できなくなる。
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: app
image: app:1.0.0
securityContext:
fsGroup: 999
.spec.serviceAccountName¶
▼ serviceAccountNameとは¶
Pod に ServiceAccount を紐付ける。
Pod のプロセスに認証済みの ID が付与され、Kubernetes と通信できるようになる。
*実装例*
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: app
image: app:1.0.0
serviceAccountName: foo-service-account
.spec.terminationGracePeriodSeconds¶
▼ terminationGracePeriodSecondsとは¶
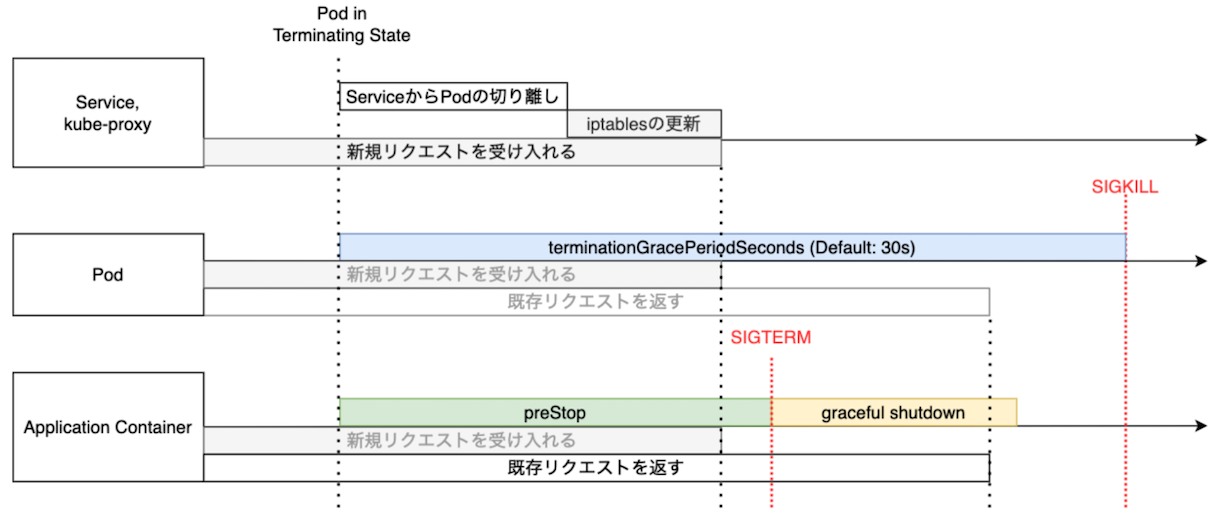
Pod の終了プロセスを開始するまで待機時間を設定する。
この時間を超えても Pod を終了できていない場合は、コンテナを強制的に停止する。
なお、.spec.containers[*].xxxProbe.terminationGracePeriodSeconds キーでコンテナ単位での待機時間を設定できる。
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: app
image: app:1.0.0
terminationGracePeriodSeconds: 45
▼ コンテナが複数個ある場合¶
Pod 内にアプリ以外のコンテナ (istio-proxy など) がある場合、すべてのコンテナの終了プロセスの時間を考慮する必要がある。
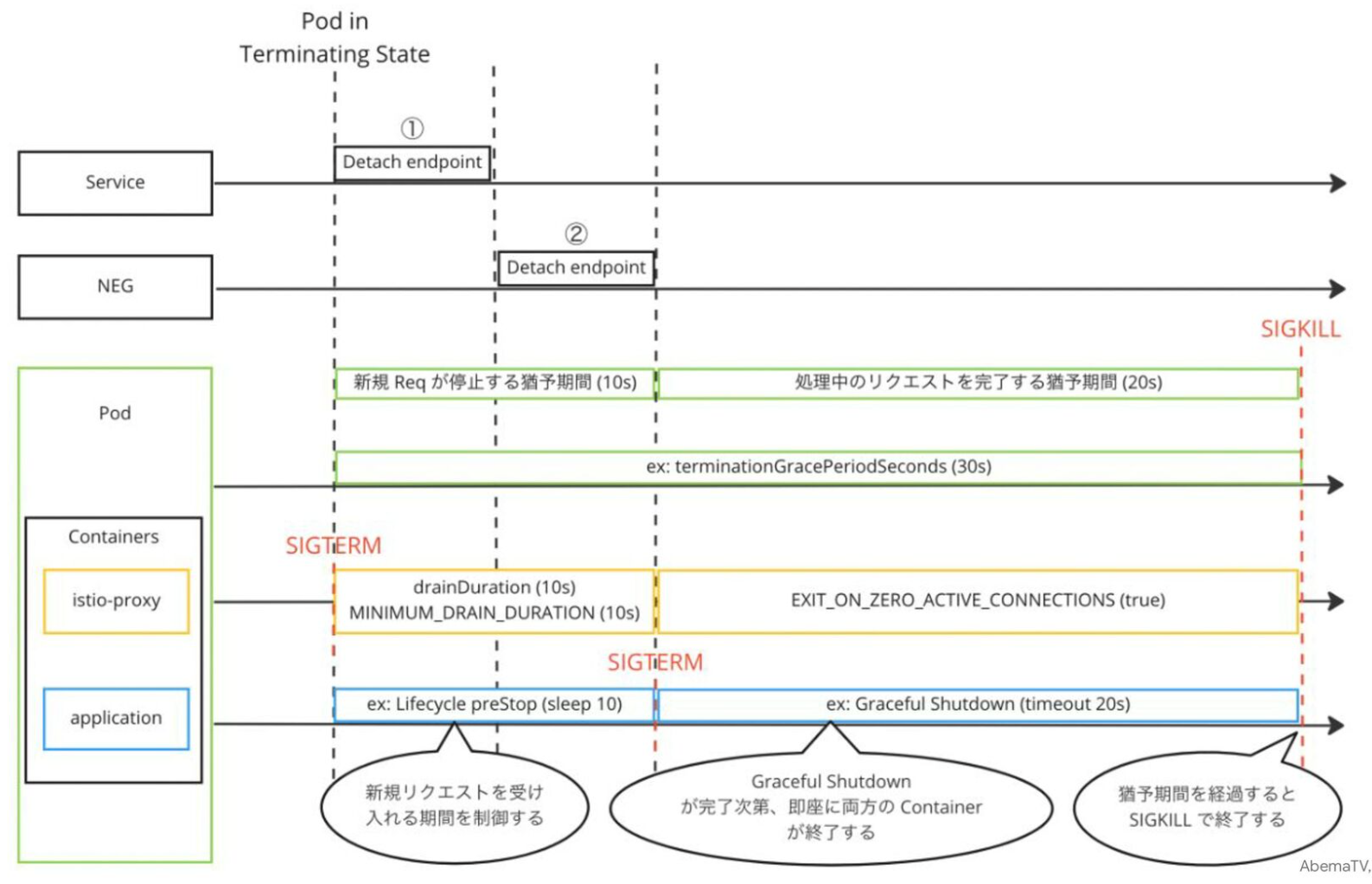
.spec.tolerations¶
▼ tolerationsとは¶
Taints と Tolerations を使用すると、指定した条件に合致する Pod 以外を Node にスケジューリングさせないようにできる。
例えば、Workload が少ない Node グループ (monitoring、ingress など) に Taint を設定し、Workload が多い Node グループ (app、system など) にはこれを設定しないようにする。
すると、.spec.tolerations キーを設定しない限り、Pod が多い Node グループのほうに Pod がスケジューリングされる。
そのため、NodeSelector や NodeAffinity を使用するより、スケジューリング対象の Node を設定する手間が省ける。
以下の方法で設定する。
事前に Node へ Taint を設定しておく。
# 非マネージドの場合
$ kubectl taint node foo-node group=monitoring:NoSchedule
# マネージドの場合
# NodeグループやNodeプールで一括してTaintを設定する
Taint への耐性を .spec.tolerations キーで設定する。
apiVersion: v1
kind: Pod
metadata:
name: prometheus
spec:
containers:
- name: app
image: app:1.0.0
# Taintへの耐性をtolerationsで定義する
tolerations:
- key: <キー>
operator: Equal
value: <値>
effect: <エフェクト>
合致する条件の .spec.tolerations キーを持つ Pod しか、Taint を持つ Node にスケジューリングさせられない。
.spec.affinity キーとは反対の条件である。
デフォルトでは、Pod は Node の metadata.labels キーを条件としてスケジューリングされる。そのため、kube-scheduler は該当の値を持たない Node に Pod をスケジューリングさせる。
▼ NoSchedule¶
指定した条件に合致する Node にはスケジューリングさせない。
なお、実行中の Pod が違反していた場合でも、再スケジューリングさせない。
*実装例*
kube-system で管理したいような重要な Pod に CriticalAddonsOnly キーの Tolerations を設定する。
合わせて Node の Taint にも CriticalAddonsOnly キーを設定することで、Taint に耐性のある Pod (CriticalAddonsOnly キー) しか、この Node にスケジューリングできなくなる。
apiVersion: v1
kind: Pod
metadata:
name: foo-coredns
namespace: kube-system
spec:
containers:
- name: coredns
image: coredns
imagePullPolicy: IfNotPresent
# Taintへの耐性をtolerationsで定義する
tolerations:
- key: CriticalAddonsOnly
operator: Exists
*実装例*
$ kubectl taint node foo-node group=monitoring:NoSchedule
apiVersion: v1
kind: Pod
metadata:
name: prometheus
spec:
containers:
- name: prometheus
image: prom/prometheus
imagePullPolicy: IfNotPresent
# Taintへの耐性をtolerationsで定義する
tolerations:
- key: group
operator: Equal
value: monitoring
effect: NoSchedule
▼ NoExecute¶
指定した条件に合致する Node にはスケジューリングさせない。
なお、実行中の Pod が違反していた場合、再スケジューリングさせる。
*実装例*
$ kubectl taint node foo-node group=monitoring:NoExecute
apiVersion: v1
kind: Pod
metadata:
name: prometheus
spec:
containers:
- name: prometheus
image: prom/prometheus
imagePullPolicy: IfNotPresent
# Taintへの耐性をtolerationsで定義する
tolerations:
- key: group
operator: Equal
value: monitoring
effect: NoExecute
.spec.topologySpreadConstraints¶
▼ topologySpreadConstraintsとは¶
異なるリージョン、AZ、Node、に Pod を分散させる。
.spec.nodeSelector キーや .spec.affinity キーのスーパーセットであり、これと比べて、Pod のスケジューリングをより柔軟に定義できる。
▼ maxSkew¶
.spec.topologySpreadConstraints[*].topologyKey キーで指定した分散の単位の間で、Pod の個数差を設定する。
*実装例*
AZ が 2 個あるとすると、各 AZ 間の Pod の個数差を 1 個にする。
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: app
image: app:1.0.0
topologySpreadConstraints:
- maxSkew: 1
# 異なるゾーンに分散させる
topologyKey: topology.kubernetes.io/zone
▼ topologyKey¶
Pod の分散の単位を設定する。
*実装例*
AZ を分散の単位に設定する。
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: app
image: app:1.0.0
topologySpreadConstraints:
# 異なるゾーンに分散させる
- topologyKey: topology.kubernetes.io/zone
▼ whenUnsatisfiable¶
分散の条件に合致する Node がない場合の振る舞いを設定する。
*実装例*
分散の条件に合致する Node がない場合、この Pod をスケジューリングさせない。
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: app
image: app:1.0.0
topologySpreadConstraints:
- whenUnsatisfiable: DoNotSchedule
▼ labelSelector¶
分散させる Pod の条件を設定する。
*実装例*
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: app
image: app:1.0.0
topologySpreadConstraints:
- labelSelector:
app.kubernetes.io/name: foo-pod
.spec.volumes¶
▼ volumesとは¶
Pod 内で使用するボリュームを設定する。
▼ configMap¶
ConfigMap の .data キー配下のキーをファイルとしてマウントする。
Secret をマウントする場合は、.spec.volumes.secret キーで設定することに注意する。
*実装例*
ConfigMap の持つキー (ここでは fluent-bit.conf キー) をコンテナにファイルとしてマウントする
そのため、コンテナには fluent-bit.conf ファイルが配置されることになる。
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: foo-fluent-bit
image: fluent/fluent-bit:1.0.0
volumeMounts:
- name: foo-fluent-bit-conf-volume
# ConfigMapの持つキー (ここではfluent-bit.confキー) をコンテナにファイルとしてマウントする
mountPath: /fluent-bit/etc/
volumes:
- name: foo-fluent-bit-conf-volume
configMap:
# ファイルを持つConfigMap
name: foo-fluent-bit-conf-config-map
# ファイルの実行権限
defaultMode: 420
apiVersion: v1
kind: ConfigMap
metadata:
name: foo-fluent-bit-conf-config-map
data:
fluent-bit.conf: |
[SERVICE]
Flush 1
Log_Level info
[OUTPUT]
Name cloudwatch
Match *
region ap-northeast-1
log_group_name /prd-foo-k8s/log
log_stream_prefix container/fluent-bit/
auto_create_group true
▼ emptyDir¶
Volume の一種である EmptyDir Volume を作成する。
『Pod』が削除されると、この EmptyDir Volume も同時に削除される。
*実装例*
オンディスクストレージを設定する。
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: app
image: app:1.0.0
volumeMounts:
- name: app-volume
mountPath: /go/src
volumes:
- name: app-volume
emptyDir: {}
*実装例*
インメモリストレージを設定する。
注意点として、Pod が使用できる上限メモリサイズを設定しない場合、Pod はスケジューリングされた Node のメモリ領域を最大限に使ってしまう。
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: app
image: app:1.0.0
volumeMounts:
- name: app-volume
mountPath: /go/src
volumes:
- name: app-volume
emptyDir:
medium: Memory
sizeLimit: 1Gi
▼ hostPath¶
Volume の一種である HostPath Volume を作成する。
PersistentVolume の一種である HostPath Volume とは区別すること。
『Node』が削除されると、この HostPath Volume も同時に削除される。
HostPath Volume 自体は本番環境で非推奨である。
*実装例*
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: app
image: app:1.0.0
volumeMounts:
- name: app-volume
mountPath: /go/src
volumes:
- name: app-volume
hostPath:
path: /data/src/foo
# コンテナ内にディレクトリがなければ作成する
type: DirectoryOrCreate
▼ name¶
要求によって作成するボリューム名を設定する。
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: app
volumeMounts:
- name: app-volume
mountPath: /go/src
volumes:
- name: app-volume
▼ projected¶
複数のソース (Secret、downwardAPI、ConfigMap、ServiceAccount の Token) を同じ Volume 上のディレクトリに配置する。
*実装例*
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: app
volumeMounts:
- name: app-volume
mountPath: /go/src
volumes:
- name: app-volume
projected:
sources:
- configMap:
name: foo-cm
- configMap:
name: bar-cm
- configMap:
name: baz-cm
▼ persistentVolumeClaim¶
PersistentVolume を使用する場合、PersistentVolumeClaim を設定する。
*実装例*
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: app
volumeMounts:
- name: app-volume
mountPath: /go/src
volumes:
- name: app-volume
persistentVolumeClaim:
claimName: foo-standard-volume-claim
PersistentVolumeClaim と PersistentVolume はあらかじめ作成しておく必要がある。
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: foo-standard-volume-claim
spec:
storageClassName: standard
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 2Gi
apiVersion: v1
kind: PersistentVolume
metadata:
name: foo-persistent-volume
spec:
storageClassName: standard
capacity:
storage: 2Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
hostPath:
path: /data/src/foo
type: DirectoryOrCreate
▼ secret¶
Secret の .data キー配下のキーをファイルとしてマウントする。
.spec.containers[*].envFrom キー (環境変数をコンテナに出力する) とは異なり、Secret からファイルを設定する。
ConfigMap をマウントする場合は、.spec.volumes.configMap キーで設定することに注意する。
*実装例*
Secret が持つ資格情報ファイル (ここでは credentials.json キー) をコンテナにファイルとしてマウントする
そのため、コンテナには資格情報ファイルが配置されることになる。
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: foo-fluent-bit
image: fluent/fluent-bit:1.0.0
volumeMounts:
- name: foo-fluent-bit-credentials-volume
# Secretの持つキー (ここではcredentials.jsonキー) をコンテナにファイルとしてマウントする
mountPath: /credentials
- name: foo-fluent-bit-conf-volume
mountPath: /fluent-bit/etc/
volumes:
- name: foo-fluent-bit-secret-volume
secret:
# ファイルを持つSecret
secretName: foo-fluent-bit-credentials
# ファイルの実行権限
defaultMode: 420
- name: foo-fluent-bit-conf-volume
configMap:
name: foo-fluent-bit-conf-config-map
defaultMode: 420
apiVersion: v1
kind: Secret
metadata:
name: foo-fluent-bit-credentials
data:
credentials.json: *****
PodDisruptionBudget¶
.spec.maxUnavailable¶
古い Pod を Node から退避させるときに、Node で退避できる Pod の最大数を設定する。
これを設定しないと、特定の Workload (例:Deployment、DaemonSet、StatefulSet、Job など) 配下の Pod をすべて退避してしまう問題が起こる。
まずは .spec.minAvailable キーでスケジューリングさせられる新しい Pod の個数を制御し、その後に .spec.minAvailable キーで退避できる古い Pod の個数を制御する。
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: foo-pod-disruption-budget
spec:
# PodをNodeから退避させる時に、Pod1個のみを退避できる。
maxUnavailable: 1
.spec.minAvailable¶
古い Pod を Node から退避させるときに、起動し続ける利用可能な Pod の最小数を設定する。
他の Node で新しい Pod のスケジューリングの完了を待機してから、古い Pod を退避させられる。
まずは .spec.minAvailable キーでスケジューリングさせられる新しい Pod の個数を制御し、その後に .spec.minAvailable キーで退避できる古い Pod の個数を制御する。
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: foo-pod-disruption-budget
spec:
# PodをNodeから退避させる時に、他のNodeで新しいPod3個のスケジューリングが完了するまで待機できる。
minAvailable: 3
.spec.selector¶
古い Pod を Node から退避させるときに、Pod の metadata.labels キーを設定する。
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: foo-pod-disruption-budget
spec:
selector:
matchLabels:
# 対象のPodのラベル
app.kubernetes.io/name: foo-pod
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
name: foo-pod
spec:
template:
metadata:
# Podのラベル
labels:
app.kubernetes.io/name: foo-pod
PriorityClass¶
globalDefault¶
▼ globalDefaultとは¶
グローバルスコープにするかどうかを設定する。
true の場合、PriorityClass を指定していない Workload に対しても、PriorityClass を一律に設定する。
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: foo-priority-class
globalDefault: false
preemptionPolicy¶
▼ preemptionPolicyとは¶
スケジューリングの優先度が競合した場合に、どのような優先度にするかを設定する。
▼ Never¶
Never とすると、必ず他の Pod のスケジューリングを優先するようになる。
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: foo-priority-class
preemptionPolicy: Never
value¶
▼ valueとは¶
ユーザー定義の PriorityClass で優先度を設定する。
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: foo-priority-class
value: 1000000
▼ -1¶
-1 とすると、優先度が最低になる。
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: foo-priority-class
value: 1000000
ReplicaController¶
旧 Deployment。
非推奨である。
Role、ClusterRole¶
rules.apiGroups¶
▼ apiGroupsとは¶
resource キーで指定する Kubernetes リソースの API グループの名前を設定する。
空文字はコアグループを表す。
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: foo-role
rules:
- apiGroups: [""]
rules.resources¶
▼ resourcesとは¶
アクション可能な Kubernetes リソースの範囲 (認可スコープ) を設定する。
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: foo-role
rules:
- apiGroups: ["", "apps"]
# Namespace、Deployment、に対してアクションを可能にする。
resources: ["namespaces", "deployments"]
rules.verbs¶
▼ verbsとは¶
実行可能なアクション範囲 (認可スコープ) を設定する。
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: foo-role
rules:
- apiGroups: [""]
resources: ["pods"]
# Get、Watch、Listのアクションを実行可能にする。
verbs: ["get", "watch", "list"]
全 Kubernetes リソースへの全アクションを許可する認可スコープの場合、以下の通りとなる。
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: foo-role
rules:
- apiGroups: ["*"]
resources: ["*"]
verbs: ["*"]
RoleBinding、ClusterRoleBinding¶
roleRef.name¶
▼ roleRef.nameとは¶
RoleBinding を使用して紐付ける Role の名前を設定する。
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: foo-role-binding
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: foo-role
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: foo-cluster-role-binding
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: foo-cluster-role
subjects.name¶
▼ subjects.nameとは¶
Role の紐付け先の Account の名前を設定する。
ServiceAccount 名に関しては、ユーザー名でもよい。
apiVersion: io.k8s.api.rbac.v1
kind: RoleBinding
metadata:
name: foo-role-binding
subjects:
- apiGroup: ""
# ServiceAccountに紐付ける。
kind: ServiceAccount
# ServiceAccountのユーザー名 (system:useraccounts:foo-service-account) でもよい。
name: foo-service-account
apiVersion: io.k8s.api.rbac.v1
kind: ClusterRoleBinding
metadata:
name: foo-cluster-role-binding
subjects:
- apiGroup: rbac.authorization.k8s.io
# UserAccountに紐付ける。
kind: User
name: foo-user-account
Secret¶
data¶
▼ dataとは¶
Kubernetes リソースに渡す機密な変数を設定する。
▼ 変数の管理¶
Secret で保持する string 型変数を設定する。
使用時に base64 方式で自動的にデコードされるため、あらかじめ base64 方式でエンコードしておく必要がある。
apiVersion: v1
kind: Secret
metadata:
name: foo-secret
type: Opaque
data:
# base64方式でエンコードされた値
username: *****
password: *****
string 型の変数しか設定できないため、base64 方式でデコード後に integer 型や boolean 型になってしまう値は、ダブルクオーテーションで囲う必要がある。
apiVersion: v1
kind: Secret
metadata:
name: foo-secret
type: Opaque
data:
enableFoo: "*****"
number: "*****"
▼ 機密なファイルの管理¶
パイプ (|) を使用すれば、ファイルを変数として設定できる。
apiVersion: v1
kind: Secret
metadata:
name: foo-secret
type: Opaque
data:
# サーバー証明書
foo.crt: |
MIIC2DCCAcCgAwIBAgIBATANBgkqh ...
# サーバー証明書とペアになる秘密鍵
foo.key: |
MIIEpgIBAAKCAQEA7yn3bRHQ5FHMQ ...
stringData¶
▼ stringDataとは¶
Kubernetes リソースに渡す機密な変数を設定する。
▼ 機密な変数の管理¶
Secret で保持する string 型の変数を設定する。
平文で設定しておく必要がある。
apiVersion: v1
kind: Secret
metadata:
name: foo-secret
stringData:
username: bar
password: baz
string 型の変数しか設定できないため、そのままだと integer 型や boolean 型になってしまう値は、ダブルクオーテーションで囲う必要がある。
apiVersion: v1
kind: Secret
metadata:
name: foo-secret
stringData:
# ダブルクオーテーションで囲う。
enableFoo: true
number: "1"
▼ 機密なファイルの管理¶
パイプ (|) を使用すれば、ファイルを変数として設定できる。
apiVersion: v1
kind: Secret
metadata:
name: foo-secret
type: Opaque
data:
config.yaml: |
apiUrl: "https://my.api.com/api/v1"
username: bar
password: baz
type¶
▼ typeとは¶
Secret の種類を設定する。
▼ kubernetes.io/basic-auth¶
ベーシック認証のための変数を設定する。
apiVersion: v1
kind: Secret
metadata:
name: foo-basic-auth-secret
type: kubernetes.io/basic-auth
data:
username: bar
password: baz
▼ kubernetes.io/dockerconfigjson¶
イメージレジストリの資格情報を設定する。
apiVersion: v1
kind: Secret
metadata:
name: foo-dockerconfigjson-secret
type: kubernetes.io/dockerconfigjson
data:
.dockercfg: |
UmVhbGx5IHJlYWxs ...
▼ kubernetes.io/service-account-token¶
Kubernetes の v1.24 以降では、Secret が自動的に作成されないようになっている。
.metadata.annotations キーと .type キーを設定した Secret を作成すると、Kubernetes はこれの data キー配下にトークン文字列を自動的に追加する。
このトークンには、失効期限がない。
apiVersion: v1
kind: Secret
metadata:
name: foo-service-account-token
annotations:
# ServiceAccountの名前を設定する
kubernetes.io/service-account.name: foo-service-account
# トークンを管理するSecretであることを宣言する
type: kubernetes.io/service-account-token
# 自動的に追加される
data:
token: xxxxxxxxxx
ServiceAccount では、Pod がこの Secret を使用できるように、その名前を設定する。
apiVersion: v1
kind: ServiceAccount
metadata:
name: foo-service-account
secrets:
- name: foo-service-account-token
▼ kubernetes.io/tls¶
SSL/TLS を使用するための変数を設定する。
サーバー証明書、サーバー証明書とペアになる秘密鍵の文字列が必要である。
ユースケースとしては、変数を Ingress に割り当て、Ingress と Service の間を HTTPS プロトコルでパケットを送受信する例がある。
apiVersion: v1
kind: Secret
metadata:
name: foo-basic-auth-secret
type: kubernetes.io/tls
data:
# サーバー証明書
tls.crt: |
MIIC2DCCAcCgAwIBAgIBATANBgkqh ...
# 秘密鍵
tls.key: |
MIIEpgIBAAKCAQEA7yn3bRHQ5FHMQ ...
▼ Opaque¶
任意の変数を設定する。
ほとんどのユースケースに適する。
apiVersion: v1
kind: Secret
metadata:
name: foo-opaque-secret
type: Opaque
data:
username: bar
password: baz
Service¶
.spec.externalIPs¶
Service の IP アドレスを固定する。
Service に紐づく Pod を外部へ直接公開したい場合 (例:POP/IMAP コンテナ) に役立つ。
apiVersion: v1
kind: Service
metadata:
name: foo-imap-service
spec:
externalIPs:
# 複数のIPアドレスを設定できる
- *.*.*.*
- *.*.*.*
- *.*.*.*
.spec.externalTrafficPolicy¶
▼ externalTrafficPolicyとは¶
記入中...
▼ Local¶
Service の SNAT 処理を無効化し、送信元 IP アドレスを変換しなようにする。
代わりに、その Service が属する Node 上の Pod にしかルーティングできない。
NodePort Service と LoadBalancer Service で使用でき、ClusterIP Service では使用できない。
apiVersion: v1
kind: Service
metadata:
name: foo-service
spec:
type: NodePort
externalTrafficPolicy: Local
apiVersion: v1
kind: Service
metadata:
name: foo-service
spec:
type: LoadBalancer
externalTrafficPolicy: Local
.spec.ports¶
▼ portsとは¶
受信する通信を設定する。
▼ appProtocol¶
受信する通信のプロトコルを設定する。
.spec.ports.protocol キーとは異なり、アプリケーション層のプロトコルを明示的に指定できる。
apiVersion: v1
kind: Service
metadata:
name: foo-service
spec:
ports:
- appProtocol: http
port: 80
apiVersion: v1
kind: Service
metadata:
name: foo-service
spec:
ports:
- appProtocol: tcp
port: 9000
▼ name¶
プロトコルのポート名を設定する。
apiVersion: v1
kind: Service
metadata:
name: foo-service
spec:
ports:
- name: http
port: 80
apiVersion: v1
kind: Service
metadata:
name: foo-service
spec:
ports:
- name: tcp-foo
port: 9000
▼ protocol¶
受信する通信のプロトコルを設定する。
*実装例*
apiVersion: v1
kind: Service
metadata:
name: foo-service
spec:
ports:
- protocol: TCP
port: 80
apiVersion: v1
kind: Service
metadata:
name: foo-service
spec:
ports:
- protocol: UDP
port: 53
apiVersion: v1
kind: Service
metadata:
name: foo-service
spec:
ports:
- protocol: SCTP
port: 22
▼ port¶
インバウンド通信を待ち受けるポート番号を設定する。
*実装例*
apiVersion: v1
kind: Service
metadata:
name: foo-service
spec:
ports:
- port: 80
apiVersion: v1
kind: Service
metadata:
name: foo-service
spec:
ports:
- port: 9000
▼ targetPort¶
受信した通信を Pod へフォワーディングするとき、いずれのポート番号を指定するか否かを設定する。
Pod 内で最初にインバウンド通信を受信するコンテナの containerPort の番号に合わせる。
デフォルトでは、.spec.ports.port キーと同じ値になる。
*実装例*
apiVersion: v1
kind: Service
metadata:
name: foo-service
spec:
ports:
- port: 8080
targetPort: 8080 # デフォルトでは、spec.ports.portキーと同じ値になる。
apiVersion: v1
kind: Service
metadata:
name: foo-service
spec:
ports:
- port: 9000
targetPort: 9000 # デフォルトでは、spec.ports.portキーと同じ値になる。
.spec.loadBalancerSourceRanges¶
▼ loadBalancerSourceRangesとは¶
LoadBalancer Service のみで設定できる。
プロビジョニングされる L4 ロードバランサーのインバウンド通信で許可する CIDR を設定する。
*実装例*
apiVersion: v1
kind: Service
metadata:
name: foo-service
spec:
type: NodePort
ports:
- name: http-foo
protocol: TCP
nodePort: 30000
port: 8080
targetPort: 8080
loadBalancerSourceRanges:
- *.*.*.*/*
.spec.selector¶
▼ selectorとは¶
インバウンド通信のフォワーディング先とする Pod の .metadata.labels キー名と値を設定する。
*実装例*
apiVersion: v1
kind: Service
metadata:
name: foo-service
spec:
selector:
app.kubernetes.io/name: foo-pod
.spec.sessionAffinity¶
▼ sessionAffinityとは¶
Pod へのルーティング時にセッションを維持する (スティッキーセッション) かどうかを設定する。
セッション ID は、Node 上に保管する。
なお、Ingress にも同じ機能がある。
▼ ClientIP¶
同じセッション内であれば、特定のクライアントからのリクエストを Service 配下の同じ Pod にルーティングし続けられる。
*実装例*
apiVersion: v1
kind: Service
metadata:
name: foo-service
spec:
sessionAffinity: ClientIP
▼ None¶
sessionAffinity を無効化する。
*実装例*
apiVersion: v1
kind: Service
metadata:
name: foo-service
spec:
sessionAffinity: None
.spec.sessionAffinityConfig¶
▼ sessionAffinityConfigとは¶
.spec.sessionAffinity キーを使用している場合に、セッションのタイムアウト時間を設定する。
タイムアウト時間を過ぎると、Node 上に保管したセッション ID を削除する。
*実装例*
apiVersion: v1
kind: Service
metadata:
name: foo-service
spec:
sessionAffinityConfig:
clientIP:
timeoutSeconds: 3600
.spec.type¶
▼ typeとは¶
Service のタイプを設定する。
▼ ClusterIPの場合¶
ClusterIP Service を設定する。
.spec.clusterIP キーで Cluster-IP を指定しない場合は、ランダムに IP アドレスが割り当てられる。
apiVersion: v1
kind: Service
metadata:
name: foo-service
spec:
type: ClusterIP
ports:
- name: http-foo
protocol: TCP
port: 8080 # Serviceが待ち受けるポート番号
targetPort: 8080 # ルーティング先のポート番号 (containerPort名でもよい)
selector:
app.kubernetes.io/name: foo-pod
# clusterIP: *.*.*.*
▼ ExternalNameの場合¶
ExternalName Service を設定する。
Cluster 内 DNS 名と Cluster 外 CNAME を紐づける。
apiVersion: v1
kind: Service
metadata:
name: foo-db-service
spec:
type: ExternalName
# foo-db-service.default.svc.cluster.local を指定すると、*****.rds.amazonaws.comに問い合わせる
externalName: *****.rds.amazonaws.com
▼ NodePortの場合¶
NodePort Service を設定する。
Service が待ち受けるポート番号とは別に、Node の NIC で待ち受けるポート番号 (30000 〜 32767) を指定する。
これを指定しない場合、コントロールプレーン Node がランダムでポート番号を決める。
apiVersion: v1
kind: Service
metadata:
name: foo-service
spec:
type: NodePort
ports:
- name: http-foo
protocol: TCP
# Nodeが待ち受けるポート番号
# 指定しなければ、コントロールプレーンNodeがランダムで決める。
nodePort: 30000
# Serviceが待ち受けるポート番号
port: 8080
# ルーティング先のポート番号 (containerPort名でもよい)
targetPort: 8080
selector:
app.kubernetes.io/name: foo-pod
NodePort のポート番号は、30000 〜 32767 番である必要がある。
spec.ports[0].nodePort: Invalid value: 80: provided port is not in the valid range. The range of valid ports is 30000-32767
▼ LoadBalancerの場合¶
LoadBalancer Service を設定する。
クラウドプロバイダーで LoadBalancer Service を作成すると、External-IP を宛先 IP アドレスとするロードバランサーを自動的にプロビジョニングする。
同時に、.status.loadBalancer キーが自動的に追加される。
.status.loadBalancer.ingress キーは、Kubernetes の Ingress とは無関係であり、インバウンドを表す『ingress』である。
.status.loadBalancer.ingress.ip キーには、ロードバランサーで指定する Service の External-IP が設定される。
apiVersion: v1
kind: Service
metadata:
name: foo-service
spec:
type: LoadBalancer
ports:
- name: http-foo
protocol: TCP
port: 8080 # Serviceが待ち受けるポート番号
targetPort: 8080 # ルーティング先のポート番号 (containerPort名でもよい)
selector:
app.kubernetes.io/name: foo-pod
# Kubernetesが自動的に追加するキー
status:
loadBalancer:
# インバウンド通信の意味のingressである
ingress:
# External-IP
- ip: 192.0.2.127
ServiceAccount¶
automountServiceAccountToken¶
▼ automountServiceAccountTokenとは¶
ServiceAccount の Pod 内のコンテナへのマウントを有効化する。
デフォルト値は true である。
apiVersion: v1
kind: ServiceAccount
metadata:
name: foo-service-account
automountServiceAccountToken: true
service-account-admission-controller は、AdmissionWebhook の仕組みで Pod の作成時にマニフェストを変更する。
これにより、Volume 上の /var/run/secrets/kubernetes.io/serviceaccount ディレクトリをコンテナに自動的にマウントするようになる。
apiVersion: v1
kind: Pod
metadata:
name: foo-pod
spec:
containers:
- name: app
image: app:1.0.0
volumeMounts:
# service-account-admission-controllerは、コンテナに自動的にマウントする
- mountPath: /var/run/secrets/kubernetes.io/serviceaccount
name: kube-api-access-*****
readOnly: true
- mountPath: /var/run/secrets/eks.amazonaws.com/serviceaccount
name: aws-iam-token
readOnly: true
volumes:
# kube-apiserverへのリクエストに必要なトークンが設定される
- name: kube-api-access-*****
projected:
defaultMode: 420
sources:
# ServiceAccountのトークン
- serviceAccountToken:
expirationSeconds: 3607
path: token
# kube-apiserverにリクエストを送信するためのサーバー証明書
- configMap:
items:
- key: ca.crt
path: ca.crt
name: kube-root-ca.crt
- downwardAPI:
items:
- fieldRef:
apiVersion: v1
fieldPath: metadata.namespace
path: namespace
# Amazon EKSを使用している場合、AWS-APIへのリクエストに必要なトークンも設定される
- name: aws-iam-token
projected:
defaultMode: 420
sources:
- serviceAccountToken:
# IDプロバイダーによるトークンの発行対象
audience: sts.amazonaws.com
expirationSeconds: 86400
path: token
マウント後、トークンの文字列はコンテナの /var/run/secrets/kubernetes.io/serviceaccount/token ファイルに記載されている。
もし、Amazon EKS を使用している場合、加えて /var/run/secrets/eks.amazonaws.com/serviceaccount/token ファイルにもトークンの文字列が記載されている。
[root@<foo-pod:/] $ cat /var/run/secrets/kubernetes.io/serviceaccount/token | base64 -d; echo
{
"alg":"RS256",
"kid":"*****"
}
# Amazon EKSを使用している場合
[root@<foo-pod:/] $ cat /var/run/secrets/eks.amazonaws.com/serviceaccount/token | base64 -d; echo
{
"alg":"RS256",
"kid":"*****"
}
- https://kakakakakku.hatenablog.com/entry/2021/07/12/095208
- https://kubernetes.io/docs/reference/access-authn-authz/service-accounts-admin/#serviceaccount-admission-controller
- https://qiita.com/hiyosi/items/35c22507b2a85892c707
- https://aws.amazon.com/jp/blogs/news/diving-into-iam-roles-for-service-accounts/
imagePullSecrets¶
▼ imagePullSecretsとは¶
プライベートイメージリポジトリの資格情報を持つ Secret を設定する。
これにより、ServiceAccount が紐付けられた Pod は、プライベートイメージリポジトリの資格情報を使用できるようになる。
apiVersion: v1
kind: ServiceAccount
metadata:
name: foo-service-account
imagePullSecrets:
- name: foo-repository-credentials-secret
secrets¶
▼ secretsとは¶
ServiceAccount に紐付けた Pod が使用できる Secret の一覧を設定する。
ServiceAccount にトークンを持つ Secret を紐づけるために使用することがある。
apiVersion: v1
kind: ServiceAccount
metadata:
name: foo-service-account
secrets:
- name: foo-service-account-token
Secret では、ServiceAccount の名前を指定する。
apiVersion: v1
kind: Secret
metadata:
name: foo-service-account-token
annotations:
kubernetes.io/service-account.name: foo-service-account
type: kubernetes.io/service-account-token
data:
token: xxxxxxxxxx
StatefulSet¶
.spec.serviceName¶
▼ serviceNameとは¶
StatefulSet によって管理される Pod にルーティングする Service を設定する。
*実装例*
apiVersion: apps/v1
kind: StatefulSet
spec:
selector:
matchLabels:
app.kubernetes.io/name: foo-pod
app.kubernetes.io/component: db
serviceName: foo-mysql-service
template:
metadata:
labels:
app.kubernetes.io/name: foo
app.kubernetes.io/component: db
spec:
containers:
- name: mysql
image: mysql:5.7
imagePullPolicy: IfNotPresent
ports:
- containerPort: 3306
volumeMounts:
- name: foo-mysql-host-path-persistent-volume-claim
mountPath: /var/volume
volumeClaimTemplates:
- metadata:
name: foo-standard-volume-claim
labels:
app.kubernetes.io/name: foo
app.kubernetes.io/component: db
spec:
storageClassName: standard
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 2Gi
.spec.template (設定項目はPodと同じ)¶
▼ templateとは¶
StatefulSet で維持管理する Pod を設定する。
設定項目は Pod と同じである。
*実装例*
apiVersion: apps/v1
kind: StatefulSet
spec:
selector:
matchLabels:
app.kubernetes.io/name: foo-pod
app.kubernetes.io/component: db
serviceName: foo-mysql-service
template:
metadata:
labels:
app.kubernetes.io/name: foo-pod
app.kubernetes.io/component: db
spec:
containers:
# MySQLコンテナ
- name: mysql
image: mysql:5.7
imagePullPolicy: IfNotPresent
ports:
- containerPort: 3306
env:
- name: MYSQL_ROOT_PASSWORD
value: root
- name: MYSQL_DATABASE
value: dev_db
- name: MYSQL_USER
value: dev_user
- name: MYSQL_PASSWORD
value: dev_password
volumeMounts:
- name: foo-mysql-host-path-persistent-volume-claim
mountPath: /var/volume
volumeClaimTemplates:
- metadata:
name: foo-standard-volume-claim
labels:
app.kubernetes.io/name: foo
app.kubernetes.io/component: db
spec:
storageClassName: standard
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 2Gi
.spec.volumeClaimTemplates¶
▼ volumeClaimTemplatesとは¶
PersistentVolumeClaim を作成する。
設定の項目は kind: PersistentVolumeClaim の場合と同じである。
StatefulSet が削除されても、これは削除されない。
*実装例*
apiVersion: apps/v1
kind: StatefulSet
spec:
selector:
matchLabels:
app.kubernetes.io/name: foo-pod
app.kubernetes.io/component: db
serviceName: foo-mysql-service
template:
metadata:
labels:
app.kubernetes.io/name: foo-pod
app.kubernetes.io/component: db
spec:
containers:
- name: mysql
image: mysql:5.7
ports:
- containerPort: 3306
volumeMounts:
- name: foo-mysql-host-path-persistent-volume-claim
mountPath: /var/volume
volumeClaimTemplates:
- metadata:
name: foo-standard-volume-claim
labels:
app.kubernetes.io/name: foo
app.kubernetes.io/component: db
spec:
storageClassName: standard
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 2Gi
StorageClass¶
allowVolumeExpansion¶
対応する PersistentVolumeClaim のサイズを拡張した場合に、対応する外部 Volume も自動的に拡張するようにする。
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: foo-storage-class
parameters:
type: gp3
allowVolumeExpansion: true
parameters¶
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: foo-storage-class
parameters:
type: gp3
provisioner¶
Node 外ストレージツールのプロビジョナーを設定する。
プロビジョナーは、StorageClass に合致する PersistentVolume を自動的に作成する。
本番環境ではクラウドの Node 外ストレージツールのプロビジョナーで PersistentVolume を作成し、一方で開発環境では開発ツール (例:Minikube) のプロビジョナーを使用するとよい。
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: aws-ebs-csi
# AWS EBS CSIドライバー
provisioner: ebs.csi.aws.com
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: standard
# Minikube CSIドライバー
provisioner: k8s.io/minikube-hostpath
reclaimPolicy¶
PersistentVolumeClaim が削除されたときに、Node 外ストレージツール (例:AWS EBS、NFS、iSCSI、Ceph など) が提供する Volume を削除する否かを設定する。
PersistentVolume にも同様の機能がある。
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: foo-storage-class
reclaimPolicy: Delete
volumeBindingMode¶
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: foo-storage-class
volumeBindingMode: WaitForFirstConsumer