プラクティス集@RDBMS¶
はじめに¶
本サイトにつきまして、以下をご認識のほど宜しくお願いいたします。
01. テーブル設計¶
テーブルの種類¶
▼ masterテーブル¶
初期開発時に作成して以降、めったに変更処理を実行せず、読み出し処理を主とするテーブル。
ドメインのうちで、ID、識別コード、名前などに関するデータを管理する。
▼ transactionテーブル¶
初期開発時に作成して以降、頻繁に変更処理を実行するテーブル。
ドメインのうちで、履歴、数量、日付などに関するデータを管理する。
命名規則¶
▼ masterテーブルとtransactionテーブルがわかるようにすること¶
master テーブルと transaction テーブルがわかるようにする命名する。
例えば、mstr_foos、trx_bars とする。
▼ テーブル名は複数形にすること¶
テーブル名は複数形にして命名する。
例えば、foos とする。
▼ カラム名には単数系接頭辞をつけること¶
カラム名には単数系接頭辞をつけて命名する。
例えば、foo_id、foo_name、foo_type とする。
ただし、子テーブルの外部キーと紐付くカラムがある場合、そのカラムの接頭辞は、子テーブル名の単数形とする。
例えば、bar_id とする。
例外として、ActiveRecord パターンのフレームワーク (例:Laravel など) では使用しないほうがよいかもしれない。
これらのフレームワークでは、単数形テーブル名の接頭辞がないカラム名を想定して機能が備わっていることがある。
この場合、DB との連携で毎回カラム名を明示する必要があったり、デフォルトではないカラム名を使用することによる不具合が発生したり、不便なことが多かったりするため、おすすめしない。
| foo_id | bar_id | foo_name | foo_type |
|---|---|---|---|
1 |
1 |
foo |
2 |
正規化¶
▼ 正規化とは¶
繰り返し要素のある表を『正規形』、その逆を『非正規形』という。
非正規形の表から、他と連動するカラムを独立させ、正規形の表に変更することを『正規化』という。
正規化によって、テーブルの冗長性を排除できる (マスターテーブルとトランザクションテーブルの分離を含む) 。
▼ 方法¶
*例*
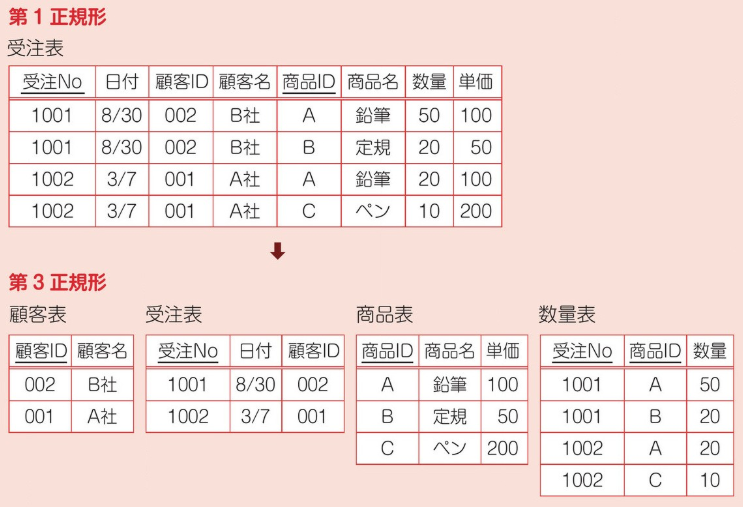
まず、主キーが受注 No と商品 ID の 2 つであることを確認。
これらの主キーは、複合主キーではないとする。
(1)-
エクセルで表を作成する。 エクセルで作られた以下の表があると仮定する。
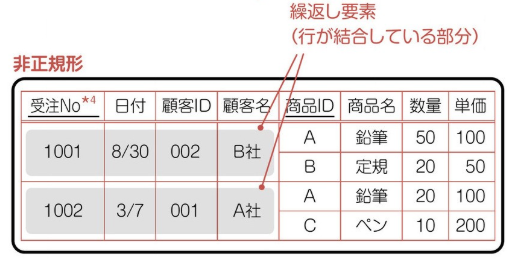
(2)-
第一正規化 (繰り返し要素の排除) を実施する。レコードを 1 つずつに分割する。
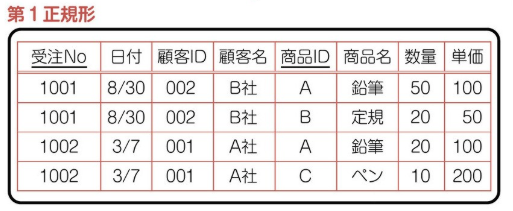
(3)-
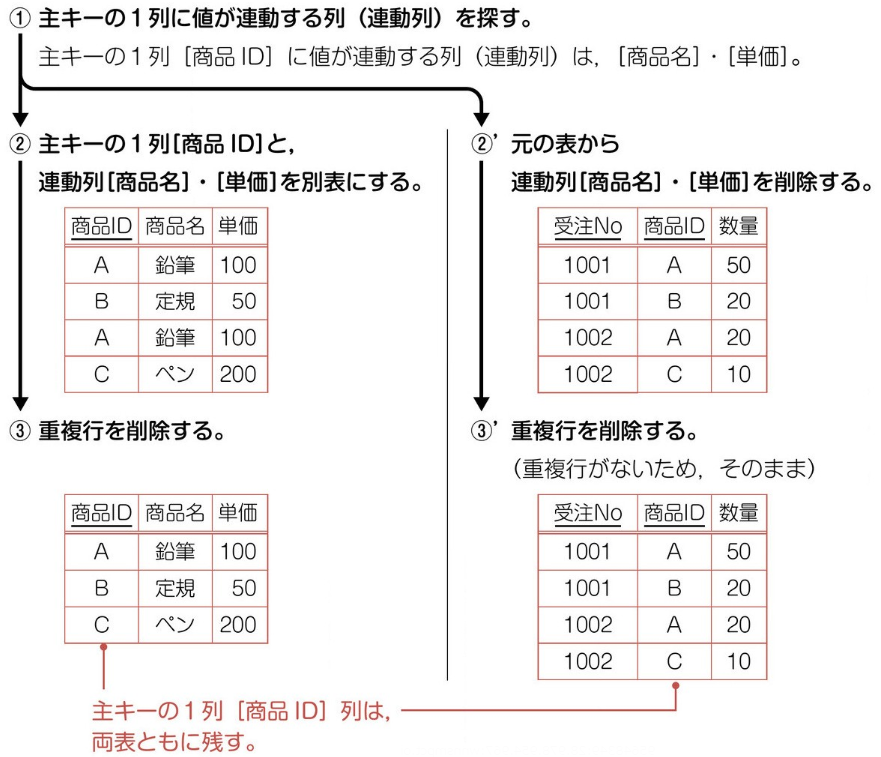
第二正規化 (主キーの関数従属性を排除) を実施する。主キーと特定のカラムは連動することがある (関数従属性あり) 。その場合は、カラムを左表として独立させる。今回、主キーは 2 つあるため、まず受注 No から関数従属性を排除していく。受注 No と他 3 カラムは連動しており、左表として独立させる。主キーと連動していたカラムを除いたものを右表とする。最後に、主キーの重複行を削除する。
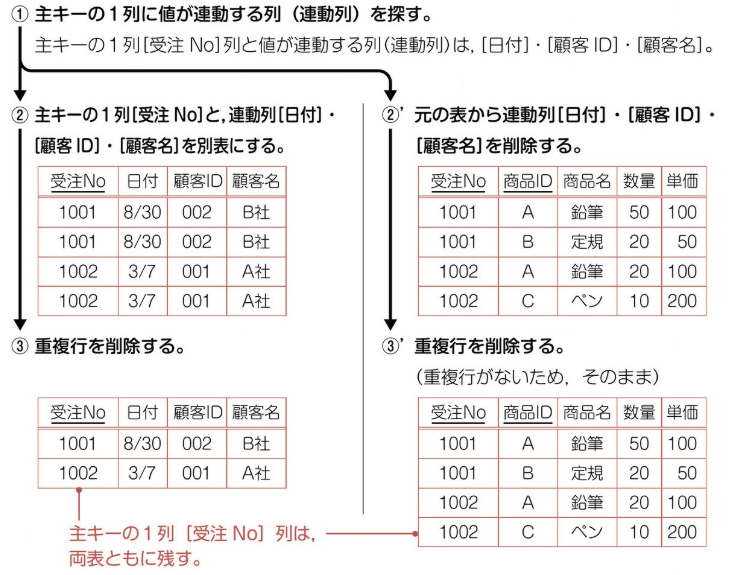
(4)-
商品 ID の関数従属性を排除していく。商品 ID と他 2 カラムに関数従属性があり、左表として独立させる。主キーと連動していたカラムを除いたものを右表とする。また、主キーが重複するローを削除する。これで、主キーの関数従属性の排除は終了。
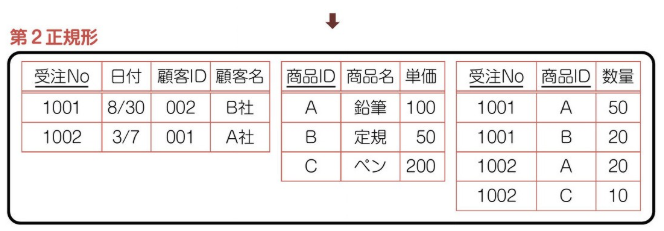
(5)-
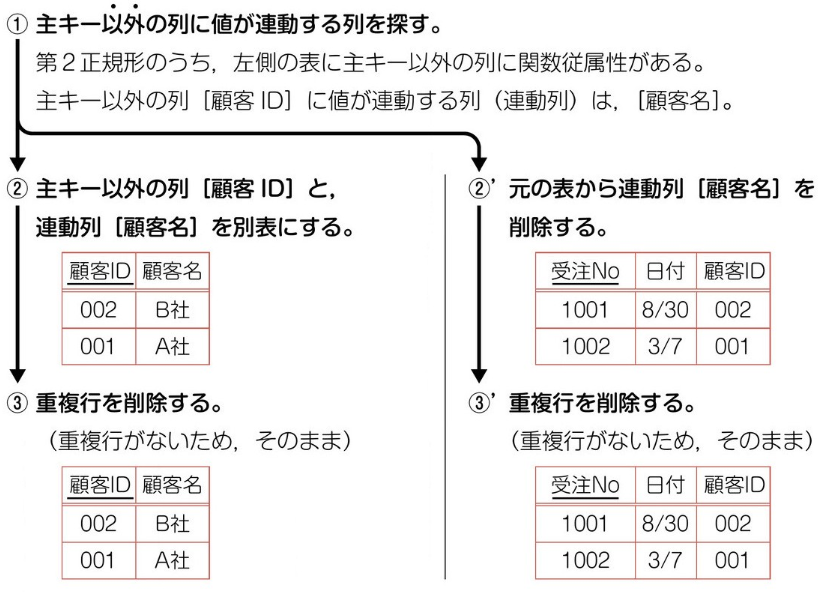
第三正規化 (主キー以外のカラムの関数従属性を排除) を実施する。 主キー以外のカラムの関係従属性を排除していく。上記で独立させた
3個の表のうち、一番左の表で、顧客 ID と顧客名に関数従属性があるため、顧客 ID を新しい主キーに設定し、左表として独立させる。主キーと連動していたカラムを除いたものを右表とする。
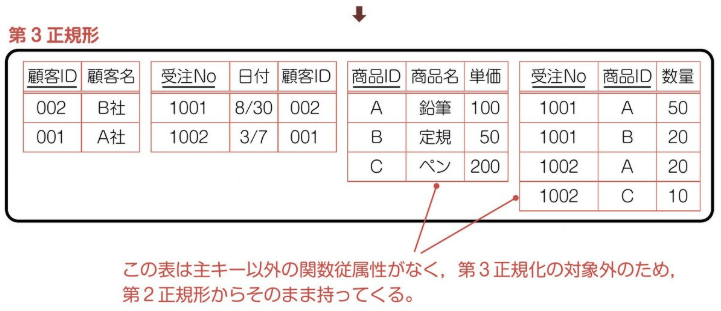
(6)-
主キーの関係従属性の排除によって、受注表、商品表、数量表に分割できた。また、主キー以外の関係従属性の排除によって、顧客 ID を新しい主キーとした顧客表に分割できた。
*例*
(1)-
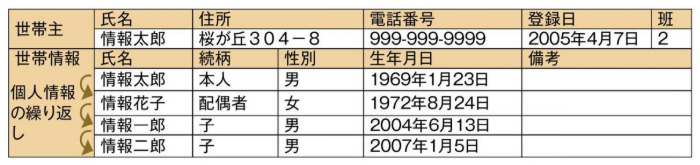
エクセルで表を作成する。以下のような表の場合、行を分割し、異なる表と見なす。
(2)-
第一正規化 (繰り返し要素の排除) を実施する。
データの追加/削除¶
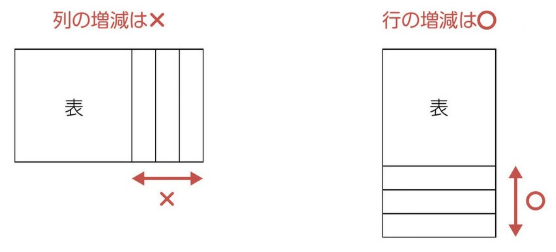
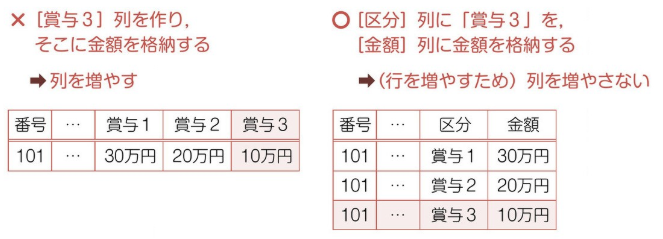
DB データを作成するあるいは削除する場合、カラムではなく、レコードの増減をする。
カラムの増減の処理には時間がかかる。
一方で、レコードの増減の処理には時間がかからない。
*例*
賞与を年 1 回から、2 回・3 回と変える場合、主キーを繰り返し、新しく賞与区分と金額区分を作る。
02. アルゴリズム設計¶
突き合わせ処理¶
▼ 突き合わせ処理とは¶
ビジネスの基盤となるマスタデータ (例:商品データ、取引先データなど) と、日々更新されるトランザクションデータ (例:販売履歴、入金履歴など) を突き合わせ、新しいデータを作成する処理のこと。
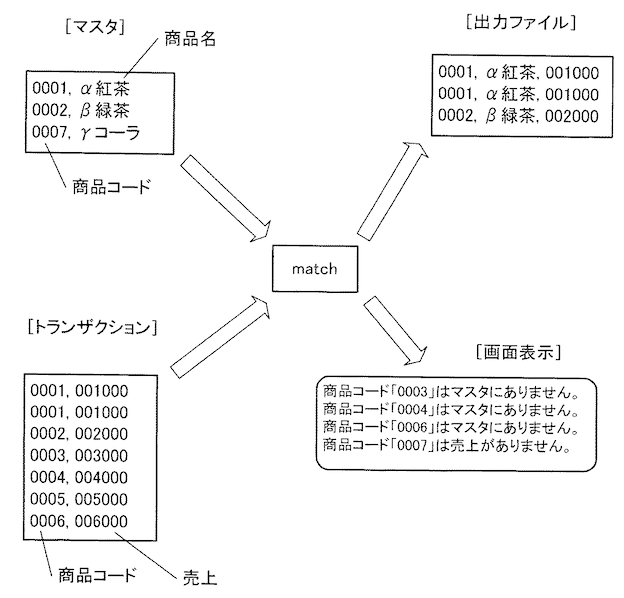
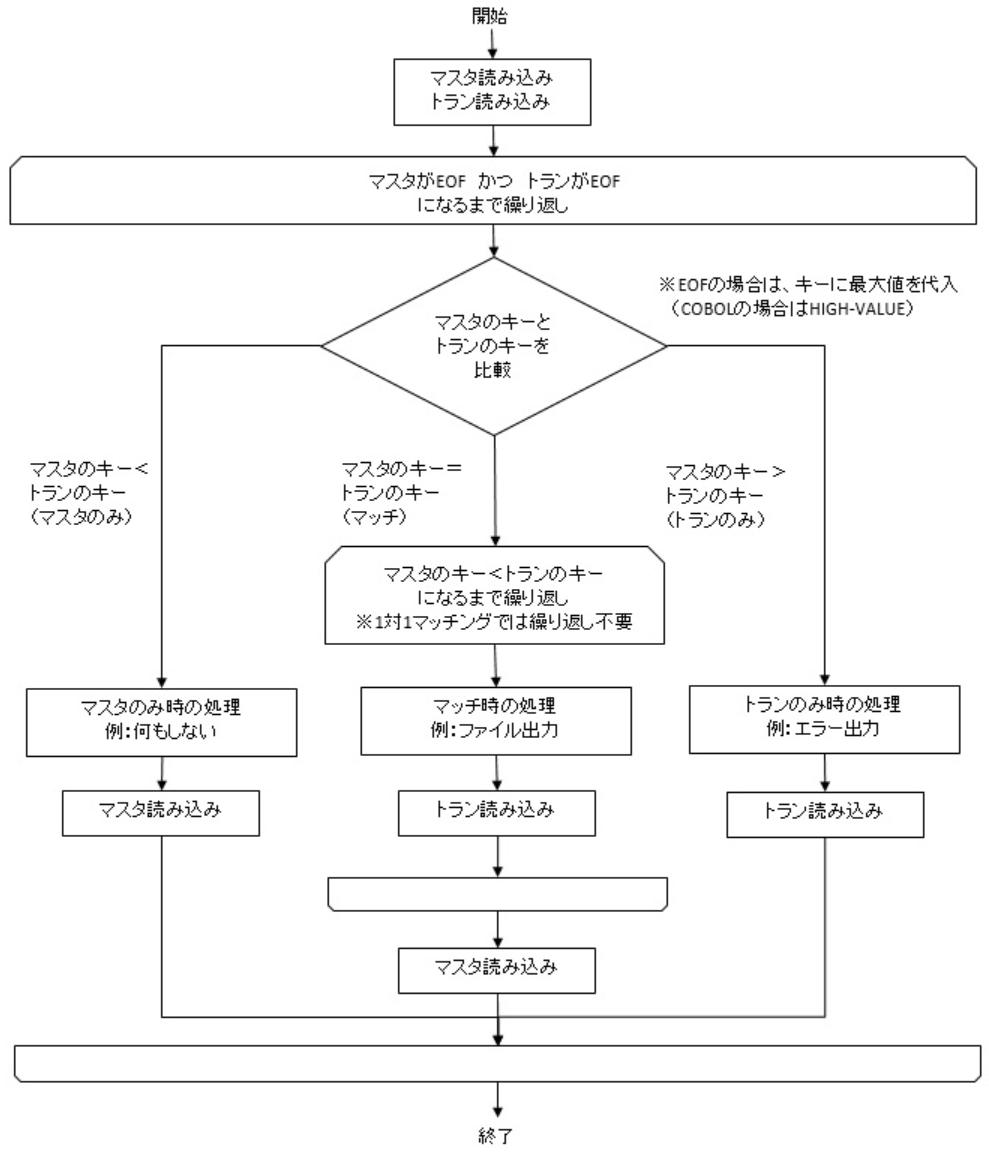
▼ アルゴリズム¶
▼ 具体例¶
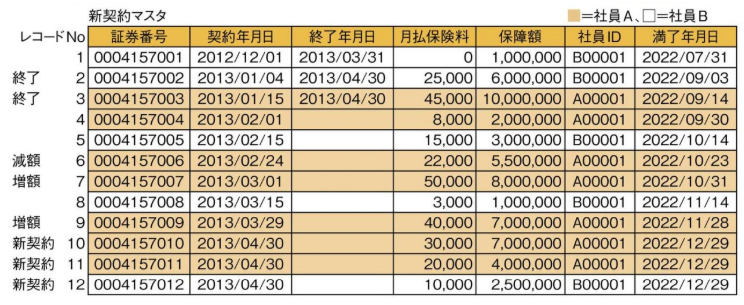
とある生命保険会社では、顧客の保険契約データを契約マスタテーブルで管理している。またそれとは別に、保険契約データの変更点 (異動事由) を異動トランザクションテーブルで管理している。
毎日、契約マスタテーブルと異動トランザクションテーブルにおける前日レコードを突き合わせ、各契約の異動事由に応じて、変更後契約データとして、新契約マスタテーブルに挿入する。
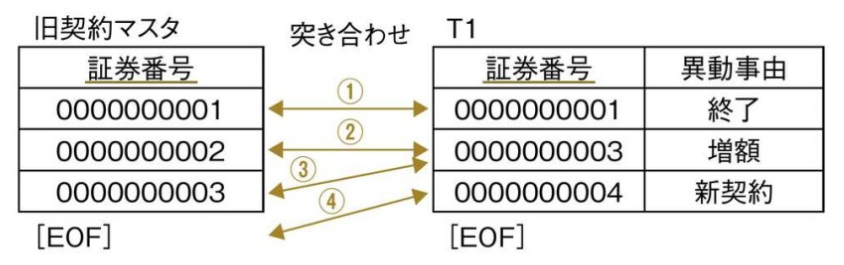
前処理として、契約マスタデータと異動トランザクションデータに共通する識別子が同じ順番で並んでいる必要がある。
(1)-
契約マスタデータの 1 レコード目と、異動トランザクションデータの 1 レコード目の識別子を突き合わせる。『
契約マスタデータ = 異動トランザクションデータ』のとき、異動トランザクションデータを基に契約マスタデータを更新し、それを新しいデータとして変更後契約マスタデータに挿入する。 (2)-
契約マスタデータの 2 レコード目と、異動トランザクションデータの 2 レコード目の識別子を突き合わせる。『
マスタデータ < トランザクションデータ』の場合、マスタデータをそのまま変更後マスタテーブルに挿入する。 (3)-
マスタデータの 3 レコード目と、固定したままのトランザクションデータの 2 レコード目の識別子を突き合わせる。『
マスタデータ = トランザクションデータ』のとき、トランザクションデータを基にマスタデータを更新し、それを変更後データとして変更後マスタテーブルに挿入する。 (4)-
『
契約マスタデータ < 異動トランザクションデータ』になるまで、データを突き合わせる。 (5)-
最終的に、変更後マスタテーブルは以下の通りになる。