cluster-autoscaler@ハードウェアリソース管理系¶
はじめに¶
本サイトにつきまして、以下をご認識のほど宜しくお願いいたします。
01. cluster-autoscaler¶
アーキテクチャ¶
cluster-autoscaler は、クラウドプロバイダーの Node グループ (例:Amazon EKS Node グループ) の API をコールし、Node の自動水平スケーリングを実行する。
cluster-autoscaler を使用しない場合、クラウドプロバイダーの Node 数は固定である。
自動水平スケーリングの条件を何にするかに応じて、アーキテクチャが異なる。
コントロールプレーン Node に配置することが推奨である。
クラウドプロバイダーのコンソール画面から Node の希望数を手動で増やし、しばらくすると cluster-autoscaler がこれを適切な数に自動的に元に戻すことから、動作を確認できる。
条件に応じたアーキテクチャ¶
▼ Podのスケジューリングの可否が条件の場合¶
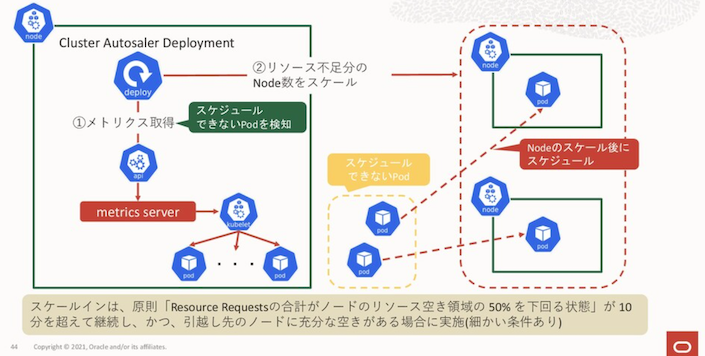
cluster-autoscaler は、ハードウェアリソース不足が原因でスケジューリングできない Pod があるとき、Node をスケーリングする。
これのために、合わせて metrics-server を使用する。
取得した Pod のハードウェアの最大リソース消費量 (.spec.containers[*].resources キーの合計値) と、Node 全体のリソースの空き領域を定期的 (10 分ほど) に比較し、Node をスケーリングさせる。
このとき、現在の空きサイズでは Pod を新しく作成できないようであれば Node をスケールアウトする。反対に空き容量へ余裕があればスケールインする。
そのため、Pod のスケジューリングの可否を条件とする場合には、metrics-server も採用する必要がある。
- https://esakat.github.io/esakat-blog/posts/eks-advent-calender-2020/#pod%E3%81%AE%E8%B2%A0%E8%8D%B7%E9%87%8F%E3%81%AB%E5%90%88%E3%82%8F%E3%81%9B%E3%81%A6%E3%82%B9%E3%82%B1%E3%83%BC%E3%83%AA%E3%83%B3%E3%82%B0hpametricsserverclusterautoscaler
- https://github.com/kubernetes/autoscaler/blob/master/cluster-autoscaler/FAQ.md#when-does-cluster-autoscaler-change-the-size-of-a-cluster
▼ Kubernetes以外のメトリクスを条件すると仮定する場合¶
Kubernetes 以外のメトリクス (例:Amazon CloudWatch、Google Cloud Monitoring) を条件とする場合は、metrics-server は不要である。
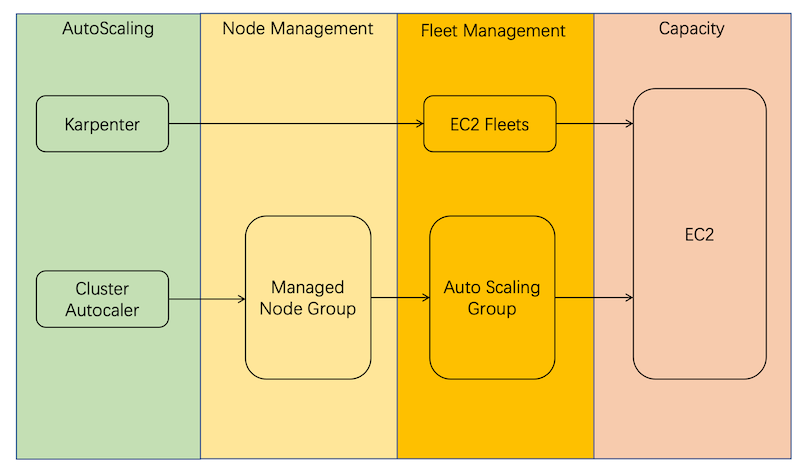
Karpenterとの違い¶
Karpenter は、EC2 のグループ (例:Amazon EC2 フリート) に関する API をコールする。
一方で cluster-autoscaler は、クラウドプロバイダーの Node グループ (例:Amazon EKS Node グループ) に関する API をコールする。
01-02. マニフェスト¶
マニフェストの種類¶
cluster-autoscaler は、Deployment (cluster-autoscaler) 、ConfigMap (cluster-autoscaler-status) などのマニフェストから構成されている。
Deployment配下のPod¶
▼ cluster-autoscaler¶
Node グループ名やこれのタグ値を使用して、コールする Node グループをフィルタリングする。
apiVersion: v1
kind: Pod
metadata:
name: cluster-autoscaler
namespace: kube-system
spec:
containers:
- command:
- ./cluster-autoscaler
# クラウドプロバイダーを設定する。
- "--cloud-provider=aws"
- "--namespace=kube-system"
# Nodeグループが設定されたClusterを設定する。
- "--node-group-auto-discovery=asg:tag=k8s.io/cluster-autoscaler/enabled,k8s.io/cluster-autoscaler/<Cluster名>"
- "--logtostderr=true"
- "--stderrthreshold=info"
- "--v=4"
env:
- name: AWS_REGION
value: ap-northeast-1
image: "registry.k8s.io/autoscaling/cluster-autoscaler:v1.23.0"
name: aws-cluster-autoscaler
ports:
- containerPort: 8085
protocol: TCP
ConfigMap¶
▼ cluster-autoscaler-status¶
cluster-autoacler のステータスが設定される。
動作確認に使用できる。
$ kubectl get configmap -n kube-system cluster-autoscaler-status -o yaml
---
apiVersion: v1
kind: ConfigMap
metadata:
name: cluster-autoscaler-status
namespace: kube-system
data:
status: |
...
.data.status キー配下に、以下のような情報を持つ。
Cluster-autoscaler status at 2023-03-27 10:38:18.725943178 +0000 UTC:
Cluster-wide:
Health: Healthy (ready=10 unready=0 (resourceUnready=0) notStarted=0 longNotStarted=0 registered=10 longUnregistered=0) LastProbeTime: 2023-03-27 10:38:18.722053187 +0000 UTC ...
LastTransitionTime: 2023-03-27 10:25:12.791878569 +0000 UTC ...
ScaleUp: NoActivity (ready=10 registered=10)
LastProbeTime: 2023-03-27 10:38:18.722053187 +0000 UTC ...
LastTransitionTime: 2023-03-27 10:25:12.791878569 +0000 UTC ...
ScaleDown: CandidatesPresent (candidates=2)
LastProbeTime: 2023-03-27 10:38:18.722053187 +0000 UTC ...
LastTransitionTime: 2023-03-27 10:29:04.227287209 +0000 UTC ...
# Nodeグループ名
NodeGroups:
Name: foo-node-group
# registered:Nodeの現在数 # cloudProviderTarget:Nodeの必要数。cloudProviderTargetのNode数に合わせてスケーリングする。
# LastProbeTime:直近で確認した時間
# LastTransitionTime:直近でスケーリングを実施した時間
Health: Healthy (ready=4 unready=0 (resourceUnready=0) notStarted=0 longNotStarted=0 registered=4 longUnregistered=0 cloudProviderTarget=4 (minSize=3, maxSize=10))
LastProbeTime: 2023-03-27 10:38:18.722053187 +0000 UTC ...
LastTransitionTime: 2023-03-27 10:25:12.791878569 +0000 UTC ...
# InProgress (スケーリング中)、Backoff (失敗後のコールド期間)、NoActivity (何もしていない)
# スケールアウトに関する情報
ScaleUp: NoActivity (ready=4 cloudProviderTarget=4)
LastProbeTime: 2023-03-27 10:38:18.722053187 +0000 UTC ...
LastTransitionTime: 2023-03-27 10:25:12.791878569 +0000 UTC ...
# スケールインに関する情報
# CandidatesPresent (スケーリングのNode候補がいる)、NonCacdidates (スケーリングのNode候補がいる)
ScaleDown: CandidatesPresent (candidates=2)
LastProbeTime: 2023-03-27 10:38:18.722053187 +0000 UTC ...
LastTransitionTime: 2023-03-27 10:29:04.227287209 +0000 UTC ...
...
02. セットアップ¶
AWS側¶
| アドオン名 | タグ | 値 | 説明 |
|---|---|---|---|
| cluster-autoscaler | k8s.io/cluster-autoscaler/<Amazon EKS Cluster名> |
owned |
cluster-autoscalerを使用する場合、cluster-autoscalerがEC2ワーカーNodeを検出するために必要である。 - https://docs.aws.amazon.com/eks/latest/userguide/autoscaling.html |
| 同上 | k8s.io/cluster-autoscaler/enabled |
true |
同上 |
03. スケーリングの仕組み¶
スケールアウトの場合¶
例えば、以下のような仕組みで、Node の自動水平スケーリングのスケールアウトを実行する。
(1)-
Pod が、Node の
70%にあたるハードウェアリソースを要求する。しかし、Nodeが
1台では足りない。70 + 70 = 140%になるため、既存のNodeの少なくとも1.4倍のスペックが必要となる。 (2)-
事前にスペックを指定した Node を
1台追加で作成する。 (3)-
新しく作成した Node で Pod をスケジューリングさせる。
(4)-
結果として、
2台それぞれで70%を消費する Pod をスケジューリングさせている。
スケールインの場合¶
例えば、以下のような仕組みで、Node の自動水平スケーリングのスケールインを実行する。
(1)-
Pod が、Node の
30%にあたるハードウェアリソースを要求する。30 + 30 = 60%になるため、既存のNodeが1台あれば足りる。 (2)-
Node が
2台以上あれば、1台になるように Node を停止する。 (3)-
停止する Node 上にいる Pod は Draining する。
(4)-
結果として、
1台で60%を消費する Pod をスケジューリングさせている。
04. 共通項目¶
metadata.annotations¶
| キー | 値の例 | 説明 |
|---|---|---|
cluster-autoscaler.kubernetes.io/scale-down-disabled |
true |
cluster-autoscalerのスケールインで削除させないNodeに設定する。 |