監視@可観測性¶
はじめに¶
本サイトにつきまして、以下をご認識のほど宜しくお願いいたします。
01. 監視の要素¶
監視とは¶
テレメトリーを基に、システムにおける想定内の不具合の発生を未然に防ぐこと。
想定内という点で、可観測性と区別できる。
監視¶
▼ テレメトリーの作成¶
データソースが、テレメトリーを作成する。
| テレメトリー | データ |
|---|---|
| ログ | ログファイルである。 |
| メトリクス | データポイントである。メトリクス名と数値のセット (例:Prometheusであれば foo{x=1, y=2}) で表す。 |
| トレース | タイムスタンプとスパンである。 |
▼ テレメトリーの収集¶
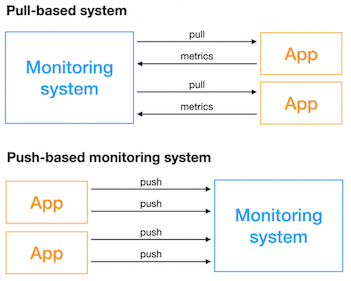
プル型の場合、監視バックエンド自体がテレメトリーを収集する。
一方でプル型の場合、監視バックエンドがエージェントを提供しており、これがテレメトリーを監視バックエンドに送信する。
メトリクスはプル型またはプッシュ型の収集ツールからなり、ログと分散トレースはプッシュ型の収集ツールのみからなる。
▼ テレメトリーの保管¶
収集したテレメトリーを監視バックエンドのストレージに保管する。
保管期間は、90 日が個人的には推奨である。
| 要件 | 説明 |
|---|---|
| ストレージ容量 | ログファイルのメトリクスのストレージのサイズを決める。メトリクスの場合、データポイント数を抑えて (例:収集間隔の拡大、ダウンサンプリング、重複排除) 、データサイズを小さくするとよい。 |
| バックアップしないログ | すべてのログを保管するとストレージ容量を圧迫してしまうため、一部のログ (例:ヘルスチェックのアクセスログ) は捨てるように決めておくとよい。 |
| バックアップの保管期間 (リテンション) | ログファイルのメトリクスのバックアップを実施し、また保管期間ポリシー (例:3 ヶ月) を決めておくとよい。 |
| ローテーション | ログローテーションによって、ファイルを小さく分割して保管しておく。ログファイルやメトリクスのローテーション期間 (例:7 日) をポリシーとして決めておくとよい。ローテションされた過去のログやメトリクスのファイルでは、ファイル名の末尾に最終日付 (例:-20220101) をつけておく。 |
| 世代数 | ローテションの結果作成されるファイルの世代数 (例:5) をポリシーとして決めておくとよい。ただ、これは設定できないツールがある。 |
▼ テレメトリーの可視化¶
監視バックエンドで収集したテレメトリーを監視フロントエンドで可視化する。
保管したテレメトリーを集約し、メトリクス (例:意味付けされた新しいメトリクス、ビジネス成果) として扱う。
注意点として、アラートのための集約は、これに含まれない。
▼ 分析とレポート¶
算出値をグラフ化として、レポートを作成する。
▼ アラートの発火と通知¶
テレメトリーに異常がある場合、これをエラーイベントとして一次オンコール担当の開発者にアラートを通知する。
すべての異常値をアラートする必要はなく、異常値とみなすための重要度レベルを決めておく。
また、エラーイベントの場所を特定できるようにするとよい。
▼ オンコール¶
通知したアラートに基づいて、責任者 (インシデントコマンダー) にオンコールする。
責任者は、エラーイベントがインシデントか否かを判断する。
▼ インシデント管理¶
責任者 (インシデントコマンダー) は、オンコールの対応を担当者に割り振る。
オンコール担当者は、エラーを解決するためのタスクを作成し、完了させる。
エラーがインシデントの場合、担当者はこれを迅速に解決する必要がある。
▼ サービスレベルとの照合¶
インシデントによって、サービス利用者に提供できたサービスがサービスレベルに満たなかった場合、サービス利用者に利用料を返金する。
監視フロントエンド¶
| OSSツール | ログ | メトリクス | トレース | イベント | ネットワーク | ユーザー体験 | ビジネス指標 | セキュリティ |
|---|---|---|---|---|---|---|---|---|
| Grafana | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | |
| Kibana | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ||
| OpenSearch Dashboards | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ||
| Redash | ✅ | ✅ | ||||||
| Apache Superset | ✅ | ✅ | ||||||
| Netdata | ✅ | ✅ | ✅ | ✅ |
02. ユーザー体験の監視¶
ユーザー体験の監視とは¶
アプリケーションのフロントエンド領域 (特にブラウザ) を対象として、監視を実施する。
メトリクスの場合¶
▼ メトリクスの種類¶
| メトリクスの種類 | 説明 |
|---|---|
| Histogram系 | 時間を単位とするアプリケーションのフロントエンド領域のメトリクス |
| Count系 | 数を単位とするアプリケーションのフロントエンド領域のメトリクス |
▼ リアルユーザー監視 (RUM)¶
特にページ性能に関するメトリクスの元になるデータポイントを収集し、監視する。
Web ページのローディング時に、Navigation-timing-API に対してリクエストを送信すると、Web ページ性能に関するメトリクスの元になるデータポイントを収集できる。
JavaScript に Navigation-timing-API へのリクエスト送信処理を組み込むと、ページ性能に関するメトリクスの元になるデータポイントを収集できる。
*技術ツール例*
- Datadog RUM
- Grafana Faro
ページローディング時間は特に重要である。
Amazon の自社調査では、ローディング時間が 100ms 短くなるごとに、売り上げは 1%増加することが明らかになった。
4 秒以下を目指すとよい。
▼ Googleアナリティクスによる監視¶
特にサイト訪問後のユーザーエンゲージメントのデータポイントを収集し、監視する。
リアルユーザー監視の一種ともみなせるが、性能の監視が主目的ではなく、リアルユーザー監視と補完し合う監視方法である。
▼ Googleサーチコンソールによる監視¶
検索エンジン上 (サイト訪問前) のユーザーエンゲージメントのデータポイントを収集し、監視する。
▼ 合成監視 (外部監視、外形監視)¶
『外部監視、外形監視』ともいう。
実際のユーザーを模した一連の操作 (フロントエンドへのリクエスト) を実施し、またレスポンスに関するメトリクスの元になるデータポイントを収集し、監視する。
ユーザーを模したリクエストを作成するという意味合いで、『合成』という。
ユーザー視点で監視できる。
特に、クリティカルユーザージャーニーの一連の操作を監視するとよい。
*技術ツール例*
- Datadog ブラウザテスト
- Grafana Cloud Synthetic
- Amazon CloudWatch Synthetics
ログの場合¶
ブラウザのコンソールログを収集し、監視する。
| ログの種類 | 説明 |
|---|---|
コンソールログ (Chromeの場合は console.log ファイル) |
ブラウザのコンソールログを出力する。 |
03. バックエンドの監視¶
バックエンドの監視とは¶
アプリケーションのバックエンド領域を対象として、監視を実施する。
メトリクスの場合¶
▼ メトリクスの種類¶
アプリケーションのメトリクスの元になるデータポイントを収集し、監視する。
| メトリクスの種類 | データポイントの内容 | 説明 |
|---|---|---|
| Count系 | データポイントのタイムスタンプ、数 | 数を単位とするアプリケーションのバックエンド領域のメトリクス (例:リクエストの受信数、ログイン数) |
| Histogram系 | データポイントのタイムスタンプ、処理時間 | 時間を単位とするアプリケーションのバックエンド領域のメトリクス (例:SQLにかかる時間、ビルドまたはデプロイの開始/完了時間、外部APIコールにかかる時間) |
▼ 性能 (APM)¶
『APM (アプリケーション性能監視) 』ともいう。
特に性能に関わるメトリクス (例:CPU 使用率、レスポンスタイム、分散トレースにおけるマイクロサービス間のスループット、エラー率、リクエスト数、連続稼働時間) のデータポイントを収集し、監視する。
▼ カスタムメトリクス¶
サーバー内に StatsD エージェントをデーモンとして常駐させ、アプリケーションで statsd パッケージを使用すると、ユーザーの定義したカスタムメトリクスの元になるデータポイントを収集できる。
Amazon CloudWatch では、StatsD からのメトリクスの送信をサポートしている。
ログの場合¶
▼ ログの種類¶
アプリケーションのログを収集し、監視する。
| ログの種類 | 説明 |
|---|---|
システムログ (/var/log/message ファイル) |
基本的にはOSやミドルウェアの処理のログの出力先ではあるが、場合よってはアプリケーション処理のログも出力する。 ・https://thinkit.co.jp/article/724/1 |
| アプリケーションログ (ログファイルはフレームワークによる) | アプリケーションの任意の重要な処理 (アクセスログ、ログイン、ログアウトなど) のログを出力する。 |
クエリログ (/var/log/<ベンダー名>/general-query.log ファイル) |
アプリケーションからDBへのクエリ処理の内容をログとして出力する。 |
分散トレースの場合¶
記入中...
セキュリティの場合¶
記入中...
04. サーバー/コンテナの監視¶
サーバー/コンテナの監視とは¶
インフラ領域のうちで、サーバー/コンテナを対象として、監視を実施する。
メトリクスの場合¶
| メトリクスの種類 | 説明 |
|---|---|
| RATE系 | 割合を単位とするサーバー/コンテナのメトリクス (例:CPU使用率、メモリ使用率、ディスク使用率) |
| Histogram系 | 時間を単位とするサーバー/コンテナのメトリクス |
| Count系 | 数を単位とするサーバー/コンテナのメトリクス |
ログの場合¶
▼ ログの種類¶
| ログの種類 | 説明 |
|---|---|
システムログ (/var/log/message ファイル) |
OSやミドルウェアの処理ログを出力する。 ・https://thinkit.co.jp/article/724/1 |
セキュリティログ (/var/log/secure ファイル) |
OSのセキュリティ処理のログを出力する。 |
cronログ (/var/log/cron ファイル) |
OSのジョブ処理 (例:Unixであればcron) のログを出力する。 |
メールログ (/var/log/maillog ファイル) |
OSのメール処理のログを出力する。 |
印刷ログ (/var/log/spooler ファイル) |
OSの印刷処理のログを出力する。 |
OSブートログ (/var/log/boot.log ファイル) |
OSの起動処理のログを出力する。 |
セキュリティの場合¶
記入中...
05. ネットワークの監視¶
ネットワークの監視とは¶
インフラ領域のうちで、ネットワークを対象として、監視を実施する。
メトリクスの場合¶
記入中...
セキュリティの場合¶
記入中...
06. アクティブヘルスチェック¶
アクティブヘルスチェックとは¶
ヘルスチェックのため、宛先にリクエストを送信し、レスポンスを検証する。
ヘルスチェックのためのリクエストを送信するという点で、『パッシブヘルスチェック』とは異なる。
アプリケーション、サーバー/コンテナ、ネットワークの場合¶
▼ ヘルスチェックの方法¶
ロードバランサーからヘルスチェックエンドポイントに専用のリクエストを送信し、ターゲットが正しく動作しているか否かを確認する。
OSI 参照モデルのいずれのレイヤーまでの動作を確認するかによって、ヘルスチェックに種類がある。
| ヘルスチェックの種類 | ヘルスチェックの範囲 | 方法 |
|---|---|---|
L3 チェック |
L1 から L3 (ネットワーク層) まで |
サーバー/コンテナのIPアドレスにPingリクエスト (ICMPエコーリクエスト) を送信し、レスポンスを検証する。Pingのレスポンスがまさしく返信されれば、サーバー/コンテナまでのネットワークが正しく動作していると判断できる。 ・https://milestone-of-se.nesuke.com/nw-basic/ip/icmp/ |
L4 チェック |
L1 から L4 (トランスポート層) まで |
サーバー/コンテナのポートにTCPスリーウェイハンドシェイクを実行し、TCP接続を確立できるかを検証する。TCP接続の確立が成功すれば、サーバー/コンテナの開放ポートまでのネットワークが正しく動作していると判断できる。 |
L7 チェック |
L1 から L7 (アプリケーション層) まで |
サーバー/コンテナ上のアプリケーションのエンドポイントにHTTPリクエストを送信し、HTTPレスポンスを検証する。正しいHTTPレスポンスが返信されれば、アプリケーション自体とその開放ポートが正しく動作していると判断できる。 |
ジョブの場合¶
▼ ヘルスチェックの方法¶
ジョブ (定期的なバッチ処理) が正常に動作しているか否かを監視する。
ジョブの実装方法としては、例えば Unix の Cron がある。
▼ Healthchecks.io¶
Cron の処理結果を監視する。
ジョブの最後に、ジョブの標準出力/標準エラー出力の内容を Healthchecks.io に送信する。
これにより、ジョブの開始から最後のリクエストまでが、一定の時間内に完了するか否かを確認する。
# cronの定義
8 6 * * * /foo-cron.sh && <ここで、Healthchecksにジョブの標準出力/標準エラー出力を送信する>
▼ curl コマンドを使用して結果を送信する場合¶
送信に curl コマンドを使用する。
# curlコマンドを使用して、Cronの実行結果をHealthchecks.ioに直接的に送信する場合
8 6 * * * /foo-cron.sh && curl -fsS --retry 5 -o /dev/null https://hc-ping.com/ping/<healthchecksのID>
▼ Runitorを使用して結果を送信する場合¶
送信に Runitor を使用すると、標準出力/標準エラー出力の内容を人間がわかりやすいように整形してくれる。
Runitor を使用しない場合、Cron の標準出力/標準エラー出力の内容をそのまま healthchecks.io へ送信することになる。
# Runitorを使用して、Cronの実行結果をHealthchecks.ioに直接的に送信する場合
# -api-url:healthchecks.ioのエンドポイント
# -uuid:healthchecks.ioのID
# --:ジョブの実行
8 6 * * * /usr/local/bin/runitor -api-url https://hc-ping.com/ping -uuid <healthchecksのID> -- /foo-cron.sh
クラウドプロバイダーの場合¶
▼ ヘルスチェックの方法¶
クラウドプロバイダーが正常に動作しているか否かを監視する。
クラウドプロバイダーの多くがステータスページを公開しているため、これを監視する。
06-02. パッシブヘルスチェック¶
パッシブヘルスチェックとは¶
ヘルスチェックのために宛先へリクエストを送信するのではなく、実際のユーザーのリクエストに対するレスポンスを検証する。
ヘルスチェックのためのリクエストを送信しないという点で、『アクティブヘルスチェック』とは異なる。
07. ビジネス成果の監視¶
ビジネス成果の監視とは¶
ビジネス成果メトリクスを対象として、監視を実施する。
ビジネス成果 (例:KPI、業務プロセスに関する現在のステータス) の監視に特化した監視バックエンドを、特に『BI ツール (例:Redash、Metabase、Google Cloud Looker など) 』ともいう。
なお、BI ツールは DB からビジネスに関するテレメトリーを収集し、監視できるようにする。
08. セキュリティ監視¶
記入中...
09. イベント監視¶
記入中...