AutoScaling@AWSリソース¶
はじめに¶
本サイトにつきまして、以下をご認識のほど宜しくお願いいたします。
01. オートスケーリングとは¶
AWS ALB を使用して、起動テンプレートを基にした Amazon EC2 の自動水平スケーリングを実行する。
注意点として、オートスケーリングに紐付ける AWS ALB では、ターゲットを登録する必要はなく、起動テンプレートに応じたインスタンスが自動的に登録される。
言い換えると、オートスケーリングにターゲットグループを紐付けて初めて、ターゲットへルーティングできるようになる。
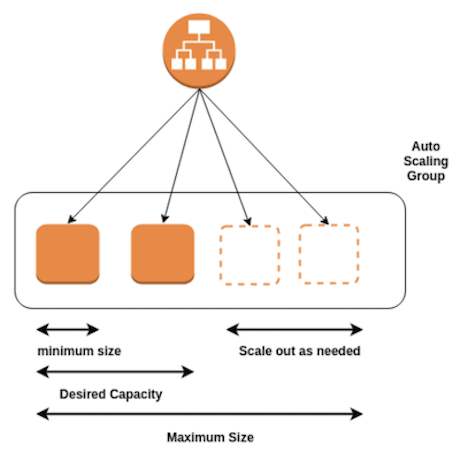
02. セットアップ (コンソールの場合)¶
設定項目と説明¶
| 項目 | 説明 | 補足 |
|---|---|---|
| スケーリンググループ | スケーリングのグループ構成を定義する。各グループで最大最小必要数を設定できる。 | |
| 起動テンプレート | スケーリングで起動するインスタンスの詳細 (例:マシンイメージ、インスタンスタイプなど) を設定する。 | |
| ネットワーク | いずれのAZのサブネットでインスタンスを作成するかを設定する。 | 選択したAZの個数よりも少ない個数のAmazon EC2を作成する場合、作成先のAZをランダムに選択する。 |
| ロードバランシング | オートスケーリングに紐づけるAWS ALBを設定する。 | |
| ヘルスチェック | ヘルスチェックの実行方法を設定する。 | |
| スケーリングポリシー | スケーリングの方法を設定する。 | |
| アクティビティ通知 | スケーリング時のイベントをSNSに通知するように設定する。 |
02. セットアップ (Terraformの場合)¶
スケーリンググループ¶
# オートスケーリンググループ
resource "aws_autoscaling_group" "foo" {
name = "foo-group"
max_size = 5
min_size = 2
health_check_grace_period = 300
health_check_type = "EC2"
desired_capacity = 4
force_delete = true
vpc_zone_identifier = ["subnet-*****", "subnet-*****"]
target_group_arns = [
aws_alb_target_group.foo.arn
]
# Nodeグループの種類だけ、起動テンプレートを設定する
launch_template {
id = aws_launch_template.foo1.id
version = "$Latest"
}
launch_template {
id = aws_launch_template.foo2.id
version = "$Latest"
}
timeouts {
delete = "15m"
}
tag {
key = "Name"
value = "foo-instance"
# オートスケーリングで起動したAmazon EC2にタグを伝搬する
propagate_at_launch = true
}
tag {
key = "Service"
value = "foo"
# オートスケーリングで起動したAmazon EC2にタグを伝搬する
propagate_at_launch = true
}
tag {
key = "Env"
value = "prd"
# オートスケーリングで起動したAmazon EC2にタグを伝搬する
propagate_at_launch = true
}
}
# AWS ALBターゲットグループ
resource "aws_lb_target_group" "foo" {
...
}
# 起動テンプレート
resource "aws_launch_template" "foo" {
...
}
起動テンプレート¶
# 起動テンプレート
resource "aws_launch_template" "foo" {
name = "foo-instance"
block_device_mappings {
device_name = "/dev/sdf"
ebs {
volume_size = 20
}
}
cpu_options {
core_count = 4
threads_per_core = 2
}
ebs_optimized = true
iam_instance_profile {
name = aws_iam_role.instance_iam_role.name
}
# 最適化AMIを使用する
# AMIのバージョンを固定するために、SSMから取得したAMI IDを自前で管理する
image_id = data.aws_ami.eks_node.image_id
instance_market_options {
market_type = "spot"
}
instance_type = "t2.micro"
metadata_options {
http_endpoint = "enabled"
http_tokens = "required"
http_put_response_hop_limit = 1
instance_metadata_tags = "enabled"
}
monitoring {
enabled = true
}
network_interfaces {
associate_public_ip_address = true
security_groups = [
"sg-*****",
"sg-*****",
"sg-*****",
]
}
tag_specifications {
resource_type = "instance"
tags = {
Name = "test"
}
}
user_data = base64encode(templatefile(
"${path.module}/templates/userdata.sh.tpl",
{}
))
}
▼ アクティビティ通知¶
# アクティビティ通知
resource "aws_autoscaling_notification" "foo" {
group_names = [
aws_autoscaling_group.bar.name,
aws_autoscaling_group.baz.name,
]
# 通知したいイベントを設定する
notifications = [
"autoscaling:EC2_INSTANCE_LAUNCH",
"autoscaling:EC2_INSTANCE_TERMINATE",
"autoscaling:EC2_INSTANCE_LAUNCH_ERROR",
"autoscaling:EC2_INSTANCE_TERMINATE_ERROR",
]
topic_arn = aws_sns_topic.foo.arn
}
# オートスケーリンググループ
resource "aws_autoscaling_group" "bar" {
...
}
resource "aws_autoscaling_group" "baz" {
...
}
# Amazon SNS
resource "aws_sns_topic" "foo" {
...
}
03. スケーリングの種類¶
シンプルスケーリング¶
▼ シンプルスケーリングとは¶
特定のメトリクスに単一の閾値を設定し、それに応じてスケールアウトとスケールインを行う。
ステップスケーリング¶
▼ ステップスケーリングとは¶
特定のメトリクスに段階的な閾値を設定し、それに応じて段階的にスケールアウトを実行する。
スケールアウトの実行条件となる閾値期間は、Amazon CloudWatch Metrics の連続期間として設定できる。
AWS としては、ターゲット追跡スケーリングの使用を推奨している。
*例*
CPU 平均使用率に段階的な閾値を設定する。
40%のときに Amazon EC2 が1個スケールアウト70%のときに Amazon EC2 を2個スケールアウト90%のときに Amazon EC2 を3個スケールアウト
▼ Amazon ECSの場合¶
記入中...
ターゲット追跡スケーリング¶
▼ ターゲット追跡スケーリングとは¶
特定のメトリクス (CPU 平均使用率やメモリ平均使用率など) のターゲット値を設定する。そして、設定値へ収束するよう、自動的にスケールインとスケールアウトを実行する。
ステップスケーリングとは異なり、スケーリングの実行条件となる閾値期間を設定できない。
*例*
- Amazon ECS サービスの Amazon ECS タスク数
- DB クラスターの Amazon Aurora のリードレプリカ数
- Lambda のスクリプト同時実行数
▼ Amazon ECSの場合¶
ターゲット値の設定に応じて、自動的にスケールアウトやスケールインが起こるシナリオ例を示す。
(1)-
最小 Amazon ECS タスク数を
2、必要 Amazon ECS タスク数を4、最大数を6、CPU 平均使用率を40%に設定する例を考える。 (2)-
平常時、CPU 使用率
40%に維持される。 (3)-
リクエストが増加し、CPU 使用率
55%に上昇する。 (4)-
Amazon ECS タスク数が
6個にスケールアウトし、CPU 使用率40%に維持される。 (5)-
リクエスト数が減少し、CPU 使用率が
20%に低下する。 (6)-
Amazon ECS タスク数が
2個にスケールインし、CPU 使用率40%に維持される。
| 設定項目 | 説明 | 補足 |
|---|---|---|
| ターゲット追跡スケーリングポリシー | 監視対象のメトリクスがターゲット値を超過しているか否かを基に、Amazon ECSタスク数のスケーリングが実行される。 | |
| Amazon ECSサービスメトリクス | 監視対象のメトリクスを設定する。 | 『平均CPU』、『平均メモリ』、『Amazon ECSタスク当たりのAWS ALBからのリクエスト数』を監視できる。SLIに対応するAmazon CloudWatch Metricsも参考にせよ。 |
| ターゲット値 | Amazon ECSタスク数のスケーリングが実行される収束値を設定する。 | ターゲット値を超過している場合、Amazon ECSタスク数がスケールアウトされる。反対に、ターゲット値未満 (正確にはターゲット値の 90%未満) の場合、Amazon ECSタスク数がスケールインされる。 |
| スケールアウトクールダウン期間 | スケールアウトを完了してから、次回のスケールアウトを発動できるまでの時間を設定する。 | ・期間を短くし過ぎると、ターゲット値を超過する状態が断続的に続いた場合、余分なスケールアウトが連続して実行されてしまうため注意する。 ・期間を長く過ぎると、スケールアウトが不十分になり、Amazon ECSの負荷が緩和されないため注意する。 |
| スケールインクールダウン期間 | スケールインを完了してから、次回のスケールインを発動できるまでの時間を設定する。 | |
| スケールインの無効化 |
スケーリングなし¶
▼ スケーリングなしとは¶
ややわかりにくい機能名であるが、スケジューリングスケーリングと予測スケーリングを指す。
負荷に合わせて動的にスケーリングするのではなく、一定の間隔で規則的にスケーリングする。
04. ヘルスチェック¶
仕組み¶
Amazon EC2ヘルスチェック¶
Amazon EC2 が自身をヘルスチェックし、異常な Amazon EC2 があれば、必要に応じて Amazon EC2 を作成し直す。
running が正常である。
impaired、stopping、stopped、shutting-down、terminated が異常である。
ロードバランサー¶
AWS ALB が Amazon EC2 をヘルスチェックし、異常な Amazon EC2 があれば、必要に応じて Amazon EC2 を作成し直す。
Healthy が正常である。
Unhealthy が異常である。
AWS EBS¶
AWS EBS が自身をヘルスチェックし、異常なボリュームがあれば、必要に応じて Amazon EC2 を作成し直す。