MySQL@RDB¶
はじめに¶
本サイトにつきまして、以下をご認識のほど宜しくお願いいたします。
01. DBエンジン¶
インメモリ方式¶
▼ MEMORY¶
メモリ上にデータを保管する。
揮発的なため、MySQL を再起動するとデータが削除されてしまう。
オンディスク方式¶
▼ InnoDB¶
ディスク上にデータを永続化する。
02. エンドポイント¶
プロトコル¶
MySQL は、TCP スリーウェイハンドシェイクで TCP 接続を確立し、MySQL プロトコルのクエリを受信する。
つまり、アプリケーションは DB への接続時に TCP スリーウェイハンドシェイクを実行し、MySQL にクエリを送信するときは MySQL プロコトルを使用することになる。
03. テーブル¶
エクスポート、インポート¶
▼ テーブルのエクスポート¶
DB からテーブルをエクスポートする。
エクスポートしたいテーブルの数だけ、テーブル名を連ねる。
$ mysqldump --force -h "<DBのホスト名>" -u "<ユーザー名>" -p'<パスワード>' "<DB名>" "<テーブル名1>" "<テーブル名2>" > table.sql
▼ テーブルのインポート¶
DB にテーブルをインポートする。
force オプションで、エラーが出ても強制的にインポート。
$ mysql --force -h "<DBのホスト名>" -u "<ユーザー名>" -p'<パスワード>' "<DB名>" < table.sql
データ型¶
▼ integer型¶
数値型である。
integer 値がどのくらい増えるかによって、3 個を使い分ける。
符号なし (Unsigned) を有効化した場合、マイナス値を使用しなくなった分、使用できるプラス値が増える。
| データ型 | 例 | 設定可能範囲 | 符号なし (Unsigned) を有効化した場合 |
|---|---|---|---|
| TINYINT | 0 |
-128~ +127 |
0~ +255 |
| INT | 0 |
2147483648~ +2147483647 |
0~ +4294967295 |
| BIGINT | 0 |
-9223372036854775808~ +9223372036854775807 |
0~ +18446744073709551615 |
▼ string型¶
文字列型である。
文字数がどのくらい増えるかによって、3 個を使い分ければよい。
VARCHAR では、文字量に応じて VARCHAR(31)や VARCHAR(255)をよく使用するが、どんな数字でもいい。
ただ、文字量が多いのであれば、VARCHAR よりも TEXT や MEDIUMTEXT を使用するほうがいい。
| データ型 | 例 |
|---|---|
| VARCHAR(n) | foo |
| TEXT | はじめまして。長谷川広樹です。 |
| MEDIUMTEXT | <ここに長いログメッセージ> |
▼ datetime型¶
日時型である。
日時を文字列として永続化でき、文字列として並び替えなどもできる。ただし、日時型として保存したほうがよりよい。
データ型((n) は保存する小数点を表す) |
例 |
|---|---|
| DATETIME | 2026-01-23 15:04:05 |
| DATETIME(3) | 2026-01-23 15:04:05.123 |
| DATETIME(6) | 2026-01-23 15:04:05.123456 |
Collation (照合順序)¶
▼ string型の照合順序とは¶
string 型のカラムに関して、WHERE 句の比較における値の特定、ORDER BY 句における並び替えの昇順降順、JOIN 句における結合、GROUP BY におけるグループ化のルールを定義する。
カラム/テーブル/DB 単位で設定でき、比較するカラム同士では同じ照合順序が設定されている必要がある。
▼ 照合順序の種類¶
寿司とビールの絵文字が区別されないことを『寿司ビール問題』という。
大文字 A と小文字 a を区別しないことは、CI:Case Insensitive と表現され、照合順序名にも特徴として CI の文字が含まれている。
| 照合順序名 | A/a | :sushi:/:beer: | は/ぱ/ば | や/ゃ |
|---|---|---|---|---|
| utf8mb4_unicode_ci | = |
= |
= |
= |
| utf8mb4_unicode_520_ci | = |
≠ |
= |
= |
| utf8mb4_general_ci | = |
= |
≠ |
≠ |
| utf8mb4_bin | ≠ |
≠ |
≠ |
≠ |
特殊文字¶
▼ 改行¶
MySQL では、\r\n を使用して、レコード内の値を改行する。
INSERT INTO foo_table (id,description) VALUES (1,'前の行\r\n後の行');
制約¶
▼ 制約とは¶
DB で、アプリケーションの CRUD 処理に対するバリデーションのルールを定義する。
しかし、必ずしも制約を使用する必要はなく、代わりのロジックをアプリケーション側で実装してもよい。
その制約を、DB とアプリケーションのいずれの責務とするかを考え、使用するか否かを判断する。
▼ プライマリーキー制約¶
プライマリーキーとするカラムにはプライマリーキー制約を課すようにする。
プライマリーキー制約によって、UNIQUE 制約と NOT NULL 制約の両方が課される。
▼ NOT NULL制約¶
レコードに挿入される値のデータ型を指定しておくことによって、データ型不一致や Null のための例外処理を実装しなくてもよくなる。
▼ 外部キー制約¶
親テーブルのカラムを参照する子テーブルのカラムを『外部キー』という。このとき、子テーブルに課す制約を『外部キー制約』という。
子テーブルにおける外部キー制約によって、親子テーブル間に以下の整合性ルールが課される。
- 親テーブルの参照元カラムに存在しない値は、子テーブルに登録できない。
- 子テーブルの外部キーが参照する値は、親テーブルの参照元カラムに存在する場合、参照元カラムを削除できない。
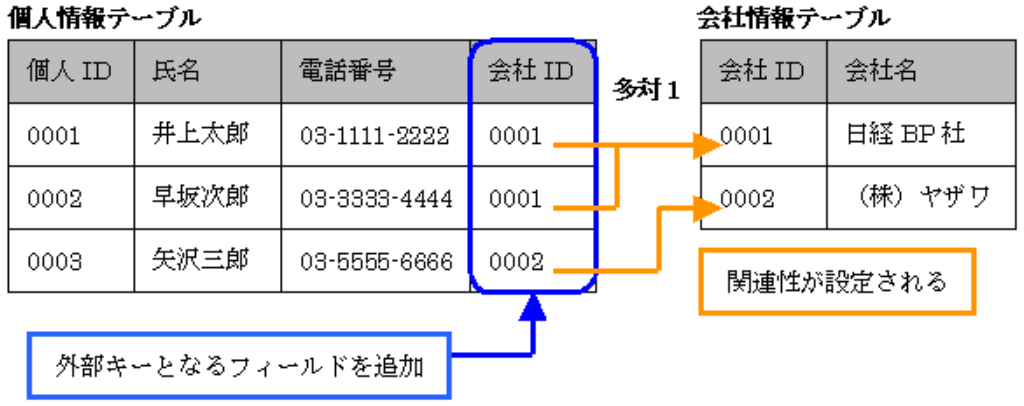
*例*
会社情報テーブル (親テーブル) と個人情報テーブル (子テーブル) があるとする。
子テーブルの会社 ID カラムを外部キーとして、親テーブルの会社 ID カラムを参照する。
親テーブルの参照元カラムに存在しない ID は、子テーブルの外部キーに登録できない。
また、親テーブルの参照元カラムは外部キーに参照されているため、参照元カラムは削除できない。
*例*
| SQL | 外部キー制約がおこる場合 |
|---|---|
| INSERT | Orders テーブル (子テーブル) のcustomer_idが、Customersテーブル (親テーブル) のidを参照しているとする。指定した customer_id がCustomersテーブルに存在しない場合、外部キー制約違反が発生する。 |
| UPDATE | Orders テーブルの customer_id が Customers テーブルの id を参照しているとする。Customers テーブルに存在しない ID に更新しようとした場合、外部キー制約違反が発生する。 |
| DELETE | Customers テーブル (親テーブル) の id が、Orders テーブル (子テーブル) の customer_id によって参照されているとする。 の customer_id に対応する Customers テーブルのレコードを削除しようとすると、外部キー制約違反が発生する。 |
プライマリーキー¶
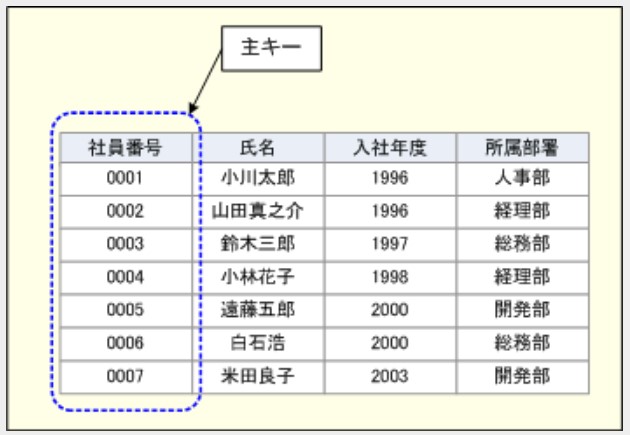
▼ プライマリーキーとは¶
テーブルのなかで、レコードを一意に識別できる値を『プライマリーキー』の値と呼ぶ。
▼ プライマリーキーとして使用できるもの¶
一意に識別できるものあれば、何をプライマリーキーとして使用しても問題なく、基本的に以下が使用される。
| プライマリーキーになるもの | 説明 | 補足 |
|---|---|---|
| MySQLのAuto Increment機能によって増加する番号カラム | プライマリーキー制約を課したカラムのAuto Increment機能を有効化しておく。CREATE 処理でドメインモデルを作成するときに、『0』または『null』をモデルのID値として割り当てる。これにより、処理によって新しいレコードが追加されるときに、現在の最新番号に+1した番号が割り当てられるようになる。これはプライマリーキー制約を満たす。・https://dev.mysql.com/doc/refman/8.0/en/example-auto-increment.html |
・ドメインモデルとDBがより密結合になり、Active Recordパターンと相性がよい。 MySQLの環境変数として『 NO_AUTO_VALUE_ON_ZERO』を設定すると、『0』の割り当てによる自動連番が拒否されるようになる。 |
UUID (例:3cc807ab-8e31-3071-aee4-f8f03781cb91) |
CREATE 処理でモデルを作成するときに、アプケーションで作成したUUID値をドメインモデルのID値として割り当てる。UUID値が重複することは基本的に発生し得ないため、プライマリーキー制約を満たす。UUID値の作成関数は言語の標準パッケージとして用意されている。 |
・ドメインモデルとDBがより疎結合にでき、Repositoryパターンと相性がよい。 UUID値は文字列として管理されるため、DBアクセス処理の負荷が高まってしまう。 プライマリーキーを使用してソートできない。 |
▼ 複合プライマリーキー¶
プライマリーキー(例:Auto Increment、UUID)は複数設定できる。
複合プライマリーキーの場合、片方のフィールドの値が異なれば、異なるプライマリーキーとして見なされる。
DB インデックス数が減るため、処理性能が高まったり、レコードごとに一意となるため、重複データの作成を抑制できる可能性もある。
次のように、冪等性が求められるテーブル、複合的なデータを持つテーブル、イベントデータを持つテーブルで役立つ
- 冪等性が求められるバッチ処理の結果を書き込むテーブル
- DB リレーションのためにテーブル間を紐づける中間テーブル
- 時系列データのテーブル
- 履歴テーブルなど
*例*
ユーザーID と期間開始日付を複合プライマリーキーとすると、一人のユーザーが複数の期間を持つことを表現できる。
| user_id | period_start_date | period_end_date | fee_yen |
|---|---|---|---|
| 1 | 2019-04-03 | 2019-05-03 | 200 |
| 1 | 2019-10-07 | 2019-11-07 | 400 |
| 2 | 2019-10-11 | 2019-11-11 | 200 |
▼ 採番テーブル¶
各テーブルのプライマリーキー(例:Auto Increment、UUID)を統合的に管理するテーブルを採番テーブルという。
各テーブルのプライマリーキーは採番テーブルを元に割り当てられるため、連番ではなく飛び飛びになる。
あらかじめ、最初のレコードのみ手動で挿入しておく。
-- 採番テーブルの作成する。
CREATE TABLE id_sequence (id BIGINT NOT NULL);
-- 最初のレコードを手動で挿入する。
INSERT INTO id_sequence VALUES (0);
CREATE 処理時には、事前に、採番テーブルに新しくプライマリーキーを作成する。
INSERT 文のプライマリーキーに『0』や『null』を割り当てるのではなく、採番テーブルから取得した ID を割り当てるようにする。
-- 新しくプライマリーキーを作成する。
UPDATE id_sequence SET id = LAST_INSERT_ID(id + 1);
-- プライマリーキーを取得する。
SELECT LAST_INSERT_ID();
04. 環境変数¶
| 環境変数 | 説明 |
|---|---|
MYSQL_DATABASE |
DBを作成する。二つ目は、CREATE を実行する必要がある。 |
MYSQL_USER |
一般ユーザーのユーザーを作成する。GRANT ALL の権限を持つ。 |
MYSQL_ALLOW_EMPTY_PASSWORD |
root ユーザーのパスワードを空文字にできる。 |
MYSQL_ROOT_PASSWORD |
root ユーザーのパスワードを設定する。デフォルトではランダム値になる。 |
MYSQL_PASSWORD |
一般ユーザーのパスワードを設定する。 |
05. ログ¶
一般ログ¶
記入中...
スロークエリログ¶
記入中...
エラーログ¶
▼ Aborted connection¶
MySQL クライアントが接続を切断した場合、MySQL 側では Aborted connection エラーとなる。
[Note] Aborted connection 251 to db: 'db_name' user: 'user_name' host: 'host_name' (Got an error reading communication packets)
06. テーブルの統計情報¶
統計情報とは¶
テーブルがもつメタデータであり、innodb_table_stats テーブルで管理されている。
SELECT * from mysql.innodb_table_stats;
+----------------------------+--------------------------+---------------------+---------+----------------------+--------------------------+
| database_name | table_name | last_update | n_rows | clustered_index_size | sum_of_other_index_sizes |
+----------------------------+--------------------------+---------------------+---------+----------------------+--------------------------+
| foo | BAR | 2024-03-06 07:11:55 | 50 | 1 | 2 |
...
オプティマイザーは以下の統計情報を参照し、SQL の実行計画を決定する。
- レコード数 (
n_rows) - DB インデックスのカーディナリティ
- DB インデックスのページ数 (
clustered_index_size、sum_of_other_index_sizes) - ヒストグラム統計
統計情報の更新¶
▼ 手動¶
ANALYZE TABLE <テーブル名> を手動で実行する。
▼ 自動¶
特定の行数があるテーブルでは、レコードが追加されていくと、特定の閾値で統計情報が更新される。
レコード数が大きくなると、相対基準では統計情報の更新タイミングが少なくなるため、絶対基準を適用するような仕組みになっている。
例えば、10 万行あるテーブルでは、相対基準として 10%の 1 万行が累積すると(つまり 11 万行になると)、統計情報が自動更新される。
例えば、100 万行あるテーブルでは、絶対基準として約 8 万行の変化(つまり 108 万行になると)、統計情報が自動更新される。
| レコード数 | 相対基準更新 (10%) | 絶対基準更新 (8万) |
|---|---|---|
| 10万 | ✅ | |
| 100万 | ✅ | |
| 1000万 | ✅ |
DBインデックスとの関係性¶
オプティマイザーは統計情報を参照し、以下を判断しながら DB インデックスを使用する稼働かを判断する。
- DB インデックスを使用するか、あるいはインデックスを使用せずにテーブルを読み込むか
- どの DB インデックスを使用するか
- 各テーブルの
JOIN順序をどうするのか
統計情報が古いと、テーブルの DB インデックスを使用するべきところを使用しなくてよいと、オプティマイザーが誤って判断してしまうことがある。
そのため、定期的 (DB レコードの大量更新時、定期 DB メンテナンス時、DB マイグレーション時) で ANALYZE TABLE <テーブル名> を実行し、テーブルの統計情報を更新しておくとよい。