データ@Go¶
はじめに¶
本サイトにつきまして、以下をご認識のほど宜しくお願いいたします。
01. データ型の種類¶
データ型のゼロ値¶
データ型には、値が代入されていないとき、ゼロ値が代入されている。
つまり、変数に値を設定しない限り、変数のデフォルト値はゼロ値になる。
プリミティブ型に所属するデータ型¶
| データ型 | 表記 | ゼロ値 |
|---|---|---|
| 数値 | int、float |
0 |
| 文字列 | string |
"" (空文字) |
| boolean値 | boolean |
false |
合成型に所属するデータ型¶
構造体の場合、フィールドのゼロ値はフィールドのデータ型による。
| データ型 | 表記 | ゼロ値 |
|---|---|---|
| 構造体 | struct |
|
| 配列 | [i] |
参照型に所属するデータ型¶
| データ型 | 表記 | ゼロ値 |
|---|---|---|
| ポインタ | * |
nil |
| slice | [] |
nil (要素数、サイズ:0) |
| map | nil |
|
| チャネル | nil |
02. プリミティブ型のまとめ¶
プリミティブ型とは¶
*実装例*
// 定義 (ゼロ値として『0』が割り当てられる)
var number int
// 代入
number = 5
Defined Typeによるユーザー定義のプリミティブ型¶
Defined Type を使用して、ユーザー定義のプリミティブ型を定義する。
元のプリミティブ型とは互換性がなくなる。
*実装例*
integer 型を元に、Age 型を定義する。
type Age int
*実装例*
パッケージの型を元に、MyAppWriter 型を定義する。
type MyAppWriter io.Writer
プリミティブ型とメモリの関係¶
プリミティブ型の変数を定義すると、データ型のバイト数に応じて、空いているメモリ領域に、変数が割り当てられる。
1 個のメモリアドレス当たり 1 バイトに相当する。
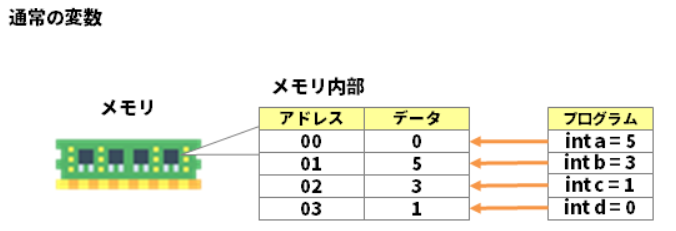
各データ型のサイズ¶
| データ型 | 型名 | サイズ(bit) | 説明 |
|---|---|---|---|
| int (符号付き整数) | int8 | 8 |
|
| int16 | 16 |
||
| int32 | 32 |
||
| int64 | 64 |
||
| int | 32 or 64 |
実装環境によって異なる。 | |
| uint (符号なし整数) | uint8 | 8 |
|
| uint16 | 16 |
||
| unit32 | 32 |
||
| uint64 | 64 |
||
| uint | 32 or 64 |
実装環境によって異なる。 | |
| float (浮動小数点) | float32 | 32 |
|
| float64 | 64 |
||
| complex (複素数) | complex64 | 64 |
実部:float32、虚部:float32 |
| complex128 | 128 |
実部:float64、虚部:float64 |
03. 構造体¶
構造体とは¶
他の言語でいう『データのみを保持するオブジェクト』に相当する。
*実装例*
構造体を定義し、変数に代入する。
var person struct {
Name string
}
Defined Typeによるユーザー定義の構造体¶
Defined Type を使用して、ユーザー定義のデータ型の構造体を定義する。
フィールド名の頭文字を大文字にした場合は、パッケージ外からのアクセスをパブリックに、小文字にした場合はプライベートになる。
*実装例*
パブリックなフィールドを持つ構造体は以下の通り。
type Person struct {
// パブリック
Name string
}
プライベートなフィールドを持つ構造体は以下の通り。
type Person struct {
// プライベート
name string
}
使用不可のフィールド名¶
小文字の『type』は予約語のため使用不可である。
大文字の Type は可能。
type Person struct {
// 定義不可エラー
type string
// 定義可能
Type string
}
初期化¶
すでに値が代入されている構造体を初期化する場合、いくつか記法がある。
そのなかでは、タグ付きリテラルが推奨される。
初期化によって作成する構造体は、ポインタ型または非ポインタ型のいずれでも問題ない。
ただし、多くの関数がポインタ型を引数型としていることから、それに合わせてポインタ型を作成することが多い。
*実装例*
まずは、タグ付きリテラル表記。
package main
import "log"
type Person struct {
Name string
}
func main() {
person := &Person{
// タグ付きリテラル表記
Name: "Hiroki",
}
log.Printf("%v", person.Name) // "Hiroki"
}
2 つ目に、タグ無しリテラル表記がある。
package main
import "log"
type Person struct {
Name string
}
func main() {
person := &Person{
// タグ無しリテラル表記
"Hiroki",
}
log.Printf("%v", person.Name) // "Hiroki"
}
3 個目に、new() 関数とデータ代入による初期化がある。
new() 関数は、データが代入されていない構造体を作成するため、リテラル表記時でも表現できる。
new() 関数は、構造体以外のデータ型でも使用できる。
ポインタ型の構造体を返却する。
package main
import "log"
type Person struct {
Name string
}
/**
* 型のコンストラクタ
* ※スコープはパッケージ内のみとする。
*/
func newPerson(name string) *Person {
// new関数を使用する。
// &Person{} に同じ。
person := new(Person)
// ポインタ型の初期化された構造体が返却される。
log.Printf("%v", person) // &main.Person{Name:""}
// フィールドに代入する
person.Name = name
return person
}
func main() {
person := newPerson("Hiroki")
log.Printf("%v", person.Name) // "Hiroki"
}
DI (依存性注入、依存オブジェクト注入)¶
構造体のフィールドとして構造体を保持することにより、依存関係を構成する。
依存される側をサプライヤー、また依存する側をクライアントという。
構造体間に依存関係を構成するには、クライアントにサプライヤーを注入する。
注入方法には、『コンストラクタインジェクション』『セッターインジェクション』『セッターインジェクション』がある。
詳しくは、以下のリンクを参考にせよ。
package main
import "fmt"
//========================
// サプライヤー側
//========================
type Name struct {
FirstName string
LastName string
}
func NewName(firstName string, lastName string) *Name {
return &Name{
FirstName: firstName,
LastName: lastName,
}
}
func (n *Name) fullName() string {
return fmt.Sprintf("%s %s", n.FirstName, n.LastName)
}
//========================
// クライアント側
//========================
type Person struct {
Name *Name
}
func NewPerson(name *Name) *Person {
return &Person{
Name: name,
}
}
func (p *Person) getName() *Name {
return p.Name
}
func main() {
name := NewName("Hiroki", "Hasegawa")
// コンストラクタインジェクションによるDI
person := NewPerson(name)
log.Printf("%v", person.getName().fullName()) // "Hiroki Hasegawa"
}
埋め込みによる委譲¶
Go には継承がなく、代わりに委譲がある。
構造体のフィールドとして別の構造体を埋め込むことにより、埋め込まれた構造体に処理を委譲する。
委譲する側の構造体を宣言するのみでなく、フィールドとして渡す必要がある。
このとき、実装者が委譲を意識しなくてよくなるように、コンストラクタのなかで初期化する。
インターフェースの委譲とは異なり、アップキャストは行えない。
つまり、委譲された構造体は委譲する構造体のデータ型にキャストでき、同じデータ型として扱えない。
*実装例*
package main
import "fmt"
//========================
// 委譲する側 (埋め込む構造体)
//========================
type Name struct {
FirstName string
LastName string
}
func (n *Name) fullName() string {
return fmt.Sprintf("%s %s", n.FirstName, n.LastName)
}
//========================
// 委譲される側 (埋め込まれる構造体)
//========================
type MyName struct {
*Name
}
func NewMyName(firstName string, lastName string) *MyName {
return &MyName{
// コンストラクタ内で委譲する構造体を初期化する。
Name: &Name{
FirstName: firstName,
LastName: lastName,
},
}
}
//================
// main
//================
func main() {
myName := NewMyName("Hiroki", "Hasegawa")
// myName構造体は、Name構造体の関数をコールできる。
log.Printf("%v", myName.fullName()) // "Hiroki Hasegawa"
}
もし、委譲する側と委譲される側に、同じ名前の関数/フィールドが存在する場合は、委譲された側のものが優先してコールされる。
package main
import "fmt"
//========================
// 委譲する側 (埋め込む構造体)
//========================
type Name struct {
FirstName string
LastName string
}
func (n *Name) fullName() string {
return fmt.Sprintf("%s %s", n.FirstName, n.LastName)
}
//========================
// 委譲される側 (埋め込まれる構造体)
//========================
type MyName struct {
*Name
}
func NewMyName(firstName string, lastName string) *MyName {
return &MyName{
// コンストラクタ内で委譲する構造体を初期化する。
Name: &Name{
FirstName: firstName,
LastName: lastName,
},
}
}
// 委譲する側と委譲される側で同じ関数
func (n *MyName) fullName() string {
return fmt.Sprintf("%s", "委譲された構造体です")
}
//================
// main
//================
func main() {
myName := NewMyName("Hiroki", "Hasegawa")
// 同じ関数がある場合、委譲された側が優先。
log.Printf("%v", myName.fullName()) // "委譲された構造体です"
}
無名構造体¶
構造体の定義と初期化を同時に実行する。
構造体に名前がなく、データ型を割り当てられないため、返却値としては使用できないことに注意する。
*実装例*
package main
import "log"
type Person struct {
Name string
}
func main() {
person := &struct {
Name string
}{
// タグ付きリテラル表記 (タグ無しリテラル表記も可能)
Name: "Hiroki",
}
log.Printf("%v", person.Name) // "Hiroki"
}
04. JSON¶
JSONと構造体のマッピング¶
構造体と JSON の間でパースを実行するとき、構造体の各フィールドと、JSON のキー名を、マッピングしておける。
*実装例*
package main
import (
"encoding/json"
"log"
)
type Person struct {
Name string `json:"name"`
}
func main() {
person := &Person{
Name: "Hiroki",
}
byteJson, err := json.Marshal(person)
if err != nil {
log.Printf("Failed to do something: %v", err)
return
}
// エンコード結果を出力
log.Printf("%v", string(byteJson)) // "{\"Name\":\"Hiroki\"}"
}
omitempty¶
値が『false、0、nil、空配列、空 slice、空 map、空文字』のときに、JSON エンコードでこれを除外できる。
構造体を除外したい場合は、nil になりうるポインタ型としておく。
*実装例*
package main
import (
"encoding/json"
"log"
)
type Person struct {
// false、0、nil、空配列、空slice、空map、空文字を除外できる。
Id int `json:"id"`
// 構造体はポインタ型としておく
Name *Name `json:"name,omitempty"`
}
type Name struct {
FirstName string `json:"first_name"`
LastName string `json:"last_name"`
}
func main() {
person := &Person{
Id: 1, // Name構造体はnilにしておく
}
byteJson, err := json.Marshal(person)
if err != nil {
log.Printf("Failed to do something: %v", err)
return
}
// エンコード結果を出力
log.Printf("%v", string(byteJson)) // "{\"id\":1}"
}
05. 配列¶
配列とは¶
要素、各要素のメモリアドレス、からなるデータのこと。
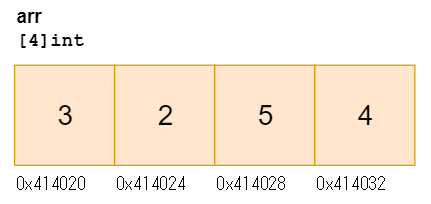
宣言と代入¶
配列を宣言し、変数に代入する。
*実装例*
宣言と代入を別々に実行する。
また、要素数の定義が必要である。
package main
import "log"
func main() {
var z [2]string
z[0] = "Hiroki"
z[1] = "Gopher"
log.Printf("%v", z) // [Hiroki Gopher]
log.Printf("%v", z) // [2]string{"Hiroki", "Gopher"}
}
宣言と代入を同時に実行する。
また、要素数の定義が必要である。
package main
import "log"
func main() {
var y [2]string = [2]string{"Hiroki", "Gopher"}
log.Printf("%v", y) // [Hiroki Gopher]
log.Printf("%v", y) // [2]string{"Hiroki", "Gopher"}
}
宣言と代入を同時に実行する。
また、型推論と要素数を省略する。
package main
import "log"
func main() {
x := [...]string{"Hiroki", "Gopher"}
log.Printf("%v", x) // [Hiroki Gopher]
log.Printf("%v", x) // [2]string{"Hiroki", "Gopher"}
}
配列とメモリの関係¶
配列型の変数を定義すると、空いているメモリ領域に、配列がまとまって割り当てられる。
1 個のメモリアドレス当たり 1 バイトに相当する。
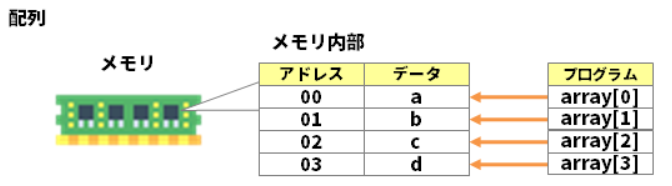
06. ポインタ¶
ポインタとは¶
メモリアドレスのこと。
ポインタ型とは¶
メモリアドレスを代入できるデータ型のこと。
参照演算子 (&)¶
定義された変数に対して、& (アンパサンド) を宣言すると、メモリアドレスを参照できる。
参照したメモリアドレス値は、ポインタ型の変数に代入する必要があるが、型推論で記述すればこれを意識しなくてよい。
*実装例*
package main
import "log"
func main() {
x := "a"
// メモリアドレスを参照する。
var p *string = &x
// p := &x と同じ
// メモリアドレスを参照する前
log.Printf("%v", x) // "a"
// メモリアドレスを参照した後
log.Printf("%v", p) // (*string)(0xc0000841e0)
}
間接参照演算子 (*)¶
ポインタ型の変数に対してアスタリスクを宣言すると、メモリアドレスに割り当てられているデータの実体を参照できる。
ポインタを使用してデータの実体を参照することを『逆参照 (デリファレンス) 』という。
*実装例*
package main
import "log"
func main() {
x := "a"
p := &x
// メモリアドレスの実体を参照する (デリファレンス) 。
y := *p
// メモリアドレスを参照する前
log.Printf("%v", x) // "a"
// メモリアドレスを参照した後
log.Printf("%v", p) // (*string)(0xc0000841e0)
// メモリアドレスに割り当てられたデータ
log.Printf("%v", y) // "a"
}
ポインタ型で扱うべきデータ型¶
| データ型 | ポインタ型で扱うべきか | 説明 |
|---|---|---|
| 構造体 | ⭕️ | ポインタ型として扱うと、構造体が持つメモリアドレスを処理するのみでよくなる。ポインタ型としない場合と比べて、少ないメモリ消費で構造体を扱える。 |
| slice、map、chan、 func | △ | データサイズの大きさによる。 |
| プリミティブ型 | ×️ | ポインタ型で扱うメリットはない。 |
07. slice¶
sliceとは¶
参照先の配列に対するポインタ、長さ、サイズを持つデータ型である。
// Goのコードより
type slice struct {
array unsafe.Pointer
len int
cap int
}
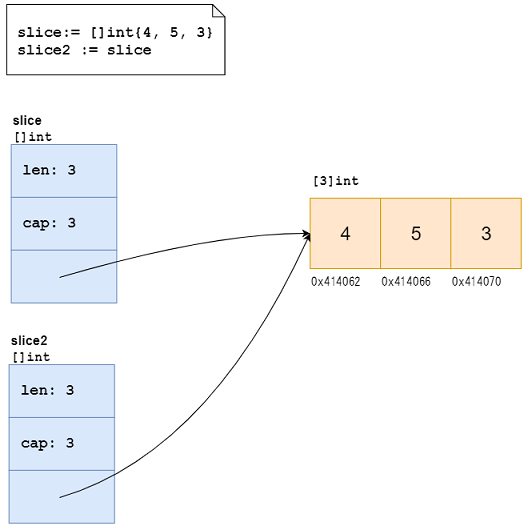
宣言と代入¶
*実装例*
宣言と代入を同時に実行する。
インターフェース型を使用してもよい。
package main
import "log"
func main() {
// var y []string = []interface{}{"Hiroki", "Gopher"} でもよい
var y []string = []string{"Hiroki", "Gopher"}
log.Printf("%v", y) // [Hiroki Gopher]
log.Printf("%v", y) // [Hiroki", "Gopher"}
}
文字列の宣言と代入を同時に実行する。
また、型推論する。
package main
import "log"
func main() {
// x := []interface{}{"Hiroki", "Gopher"} でもよい
x := []string{"Hiroki", "Gopher"}
log.Printf("%v", x) // [Hiroki Gopher]
log.Printf("%v", x) // [Hiroki", "Gopher"}
}
バイト文字列の宣言と代入を同時に実行する。
また、型推論する。
package main
import "log"
func main() {
// []byte{"abc"} でもよい
x := []byte("abc")
log.Printf("%v", x) // [97 98 99]
log.Printf("%v", x) // []byte{0x61, 0x62, 0x63}
}
構造体の slice の宣言と代入を同時に実行する。
また、型推論する。
package main
import "log"
type Person struct {
Name string
}
func main() {
// []Person{{ Name: "Hiroki" }} でもよい
person := []Person{{ Name: "Hiroki" }}
log.Printf("%v", person) // [{Name:Hiroki}]
log.Printf("%v", person) // []main.Person{main.Person{Name:"Hiroki"}}
}
配列の値の参照¶
▼ [<数値>]¶
slice で、指定したインデックスの値を参照する。
package main
import "log"
func main() {
x := []string{"あ", "い", "う", "え", "お"}
// 要素番号は0から始まることに注意する
// 4番の要素を参照する
xb := x[4]
log.Printf("%v", x) // [お]
}
▼ [<数値>:]¶
slice で、指定したインデックス以上の値を参照する。
package main
import "log"
func main() {
x := []string{"あ", "い", "う", "え", "お"}
// 要素番号は0から始まることに注意する
// 1番目以上を参照する
xb := x[1:]
log.Printf("%v", xb) // [い, う, え, お]
}
▼ [:<数値>]¶
slice で、指定したインデックス未満の値を参照する。
package main
import "log"
func main() {
x := []string{"あ", "い", "う", "え", "お"}
// 要素番号は0から始まることに注意する
// 1番目未満を参照する
xb := x[:1]
log.Printf("%v", xb) // [あ]
}
▼ [<数値>:<数値>]¶
slice で、指定したインデックスの範囲 (以上、未満) の値を参照する。
package main
import "log"
func main() {
x := []string{"あ", "い", "う", "え", "お"}
// 要素番号は0から始まることに注意する
// 1番目から3番目未満 (2番目) までを参照する
xb := x[1:3]
log.Printf("%v", xb) // [い, う]
}
要素の追加¶
▼ sliceに値を追加する¶
渡された slice で、後ろから要素を追加する。
package main
import "fmt"
func main() {
s := []int{10, 20, 30, 40}
fmt.Println(s) // [10 20 30 40]
// 要素を追加。
s = append(s, 50, 60, 70, 80)
fmt.Println(s) // [10 20 30 40 50 60 70 80]
}
▼ sliceにsliceを追加する¶
渡された slice で、後ろから要素を追加する。
slice をアンパック (...) する必要がある。
package main
import "fmt"
func main() {
s1 := []int{10, 20, 30, 40}
s2 := []int{50, 60, 70, 80}
// 要素を追加
s = append(s1, s2...)
fmt.Println(s) // [10 20 30 40 50 60 70 80]
}
08. map¶
単一のプリミティブ型を値に持つmap¶
▼ 文字列:任意の値¶
インターフェース型により、任意の型とする。
インターフェースのエイリアスである any 型でもよい。
package main
import "fmt"
func main() {
// 『文字列:任意の値』のmap
m := map[string]interface{}{
"foo": "FOO",
"bar": 1,
"baz": true,
}
fmt.Println(m) // map[0:Hiroki 1:Hiroko 2:Hiroshi]
}
▼ インデックス番号:文字列¶
map の定義と代入を同時に実行する。
package main
import "fmt"
func main() {
// 『数値:文字列』のmap
m := map[int]string{
0: "Hiroki",
1: "Hiroko",
2: "Hiroshi",
}
fmt.Println(m) // map[0:Hiroki 1:Hiroko 2:Hiroshi]
}
定義と代入を別々に実行する。
package main
import "fmt"
func main() {
// 『数値:文字列』のmap
m := map[int]string{}
m[0] = "Hiroki"
m[1] = "Hiroshi"
m[2] = "Hiroshi"
fmt.Println(m) // map[0:Hiroki 1:Hiroko 2:Hiroshi]
}
または、make() 関数を使用して map を作成もできる。
package main
import "fmt"
func main() {
// 『数値:文字列』のmap
m := make(map[int]string)
m[0] = "Hiroki"
m[1] = "Hiroshi"
m[2] = "Hiroshi"
fmt.Println(m) // map[0:Hiroki 1:Hiroko 2:Hiroshi]
}
slice型を値に持つmap¶
package main
import "fmt"
func main() {
// 『文字列:slice』のmap
m := map[string][]string{
"errors": {
0: "エラーメッセージ0",
1: "エラーメッセージ1",
2: "エラーメッセージ2",
},
}
fmt.Println(m) // map[errors:[エラーメッセージ0 エラーメッセージ1 エラーメッセージ2]]
}
複数のデータ型を持つmap¶
map 型データの値をインターフェース型とすることにより、複数のデータ型を表現できる。
package main
import "fmt"
func main() {
// 『文字列:複数のプリミティブ型』のmap
m := map[string]interface{}{
"id": 1,
"name": "Hiroki Hasegawa",
}
fmt.Println(m) // map[id:1 name:Hiroki Hasegawa]
}
map値の抽出¶
package main
import "fmt"
func main() {
m := map[int]string{
1: "Hiroki",
2: "Hiroko",
3: "Hiroshi",
}
// 値の抽出
v, ok := m[1]
// エラーハンドリング
if !ok {
fmt.Println("Value is not found.") // Value is not found.
}
fmt.Println(v) // Hiroki
}
09. インターフェース¶
委譲¶
▼ 暗黙的に実装する¶
インターフェースを満たす関数を構造体に紐付けると、インターフェースを暗黙的に実装した構造体を作成できる。
構造体の委譲とは異なり、アップキャストを行える。
つまり、委譲された構造体は委譲するインターフェースのデータ型にキャストでき、同じデータ型として扱える。
*実装例*
InspectImpl 構造体に Animal インターフェースを埋め込み、構造体に Eat() 関数、Sleep() 関数、Mating() 関数の処理を委譲する。
package main
import "fmt"
// インターフェースとその関数を定義する。
type AnimalInterface interface {
Name() string
Eat() string
Sleep() string
}
type InsectImpl struct {
name string
}
type FishImpl struct {
name string
}
type MammalImpl struct {
name string
}
// コンストラクタ
func NewInsect(name string) (*InsectImpl, error) {
return &InsectImpl{
name: name,
}, nil
}
// インターフェースを満たす関数 (ここでいうName、Eat、Sleep) を構造体に紐付ける
// インターフェースを暗黙的に実装した構造体を作成できる
func (i *InsectImpl) Name() string {
return i.name
}
func (i *InsectImpl) Eat() string {
return "食べる"
}
func (i *InsectImpl) Sleep() string {
return "眠る"
}
func main() {
insect, err := NewInsect("カブトムシ")
if err != nil {
log.Printf("Failed to do something: %v", err)
return
}
// 関数を実行する。
fmt.Println(insect.Name())
fmt.Println(insect.Eat())
fmt.Println(insect.Sleep())
}
▼ インターフェースを構造体に埋め込む¶
構造体のフィールドとして別のインターフェースを埋め込むことにより、埋め込まれた構造体に処理のすべてを委譲する。
▼ インターフェースを実装する構造体を構造体に埋め込む¶
アップキャストの可否を利用した検証¶
もし、構造体で実装された関数に不足があると、委譲が自動的に取り消される。
エラーは発生しないため、実装された関数が十分であることを実装者が知らなければならない。
アップキャストの可否を使用して、意図的にエラーを発生させるテクニックがある。
package main
import "fmt"
// アップキャストの可否を使用して、構造体がインターフェースを満たしているを検証する。
var _ AnimalInterface = &InsectImpl{} // もしくは (*InsectImpl)(nil)
// インターフェースとその関数を定義する。
type AnimalInterface interface {
Name() string
Eat() string
}
type InsectImpl struct {
name string
}
// コンストラクタ
func NewInsect(name string) (*InsectImpl, error) {
return &InsectImpl{
name: name,
}, nil
}
// 構造体に関数を紐付ける。インターフェースを暗黙的に実装する。
func (i *InsectImpl) Name() string {
return i.name
}
func main() {
insect, err := NewInsect("カブトムシ")
if err != nil {
log.Printf("Failed to do something: %v", err)
return
}
// 関数を実行する。
fmt.Println(insect.Name())
}
# Eat関数を紐付けていない場合
cannot use insect (type Insect) as type Animal in assignment:
Insect does not implement Animal (missing Eat method)
緩い型としてのインターフェース¶
さまざまな値をインターフェース型として定義できる。
エイリアスとして、any 型でも定義できる。
また、他の型に変換もできる。
*実装例*
package main
import "log"
func main() {
var foo interface{}
foo = 1
log.Printf("%v", foo) // 1
foo = 3.14
log.Printf("%v", foo) // 3.14
foo = "Hiroki"
log.Printf("%v", foo) // "Hiroki"
foo = [...]uint8{1, 2, 3, 4, 5}
log.Printf("%v", x) // [5]uint8{0x1, 0x2, 0x3, 0x4, 0x5}
}
注意点として、インターフェース型は演算できない。
package main
import "log"
func main() {
var foo, bar interface{}
// インターフェース型
foo, bar = 1, 2
log.Printf("%v", foo) // 1
log.Printf("%v", bar) // 2
// エラーになってしまう。
// invalid operation: foo + bar (operator + not defined on interface)
baz := foo + bar
log.Printf("%v", baz)
}
型アサーション¶
インターフェース型を他の型に変換する。
インターフェース型の変数で『.(データ型)』を宣言する。
package main
import "log"
func main() {
var foo, bar interface{}
// インターフェース型
foo, bar = 1, 2
// インターフェース型からinteger型に変換 (変換しないと演算できない)
foo := foo.(int)
bar := bar.(int)
baz := foo + bar
log.Printf("%v", baz)
}
errorインターフェース¶
Go には、標準搭載されているインターフェースがある。
このインターフェースが強制する関数を実装した構造体を定義すると、自動的に委譲が行われる。
*例*
type error interface {
Error() string
}
stringインターフェース¶
構造体に String() 関数を定義しておくと、Print 系関数に構造体を渡したときに、これが実行される。
*実装例*
package main
import "fmt"
type Foo struct{}
func (f *Foo) String() string {
return "String関数を実行しました。"
}
func main() {
f := &Foo{}
fmt.Println(f)
}
10. nil¶
nilとは¶
いくつかのデータ型におけるゼロ値のこと。
ポインタの場合¶
*実装例*
package main
import "log"
func main() {
x := "x"
// ポインタ型の定義のみ
var p1 *string
// ポインタ型の変数を定義代入
var p2 *string = &x
log.Printf("%v", p1) // (*string)(nil)
log.Printf("%v", p2) // (*string)(0xc0000841e0)
}
インターフェースの場合¶
*実装例*
package main
import "log"
func main() {
var foo interface{}
log.Printf("%v", foo) // <nil>
}