アンチパターン@SREing¶
はじめに¶
本サイトにつきまして、以下をご認識のほど宜しくお願いいたします。
01. アンチパターン集 (Dropbox)¶
はじめに¶
1. サイトリライアビリティオペレーション¶
▼ パターンの概要¶
今までのシステム運用 (例:NOC) を SREing と言い換えるだけの方法のこと。
▼ 問題点¶
- SREer の作業内容には、システム運用だけなく、開発も含まれる。またこの開発では、できるだけ人の手を離れていて、障害の発生頻度が少ないようなシステムを構築する必要がある。
- NOC のような場所は、作業に集中できる環境ではない。
- ヒーローパターンはアンチパターン。
- ヒーローパターンでは作業が属人化するため、チームが育たず、またドキュンメントが残らずに本人がいなくなってしまうことがある。
-

▼ 解決策¶
- 作業時間の最適化
- SREer は、勤務時間の半分以上を、システム運用ではなく開発に割り当てる。
- 作業場所の最適化
- NOC のように、24 時間 365 日、システムのすぐそばでオンコール担当者がこれの面倒を見るのではなく、リモートでどこからでもすぐに対応可能にする。
- オンコール担当者がメトリクスのとき系列データの共有リンクをインシデントに関心がある人に共有すれば、共通の視点でインシデントを見ることができる。
2. 画面を見つめる人間¶
▼ パターンの概要¶
- 自動検出されたエラーイベントからアラートを手動で作成すること。
- 作成したすべてのアラートを通知し、手動でインシデントか否かを判断してしまうこと。
▼ 問題点¶
インシデントの解決作業のせいで、それ以外の業務に集中できない。
▼ 解決策¶
- アラート通知前の自動解決
- エラーイベントのアラートが作成されたとき、すぐにオンコール担当者に通知するのでなく、システムに自動的に解決する。
- Kubernetes の LivenessProbe ヘルスチェックや Node 停止時の Pod の移動は、この自動的解決の
1個である。
- Kubernetes の LivenessProbe ヘルスチェックや Node 停止時の Pod の移動は、この自動的解決の
- エラーイベントのアラートが作成されたとき、すぐにオンコール担当者に通知するのでなく、システムに自動的に解決する。
- 通知後の自動タスク化
- 解決できなかったエラーイベントをインシデントかどうかを判断してタスク化する作業も自動化する。
3. 群衆によるインシデント対応¶
▼ パターンの概要¶
インシデントの担当者を無秩序に配置してしまうこと。
▼ 問題点¶
- さまざまな仮説が入り混じり、むしろ解決が長引く。
- インシデントの解決作業のせいで、それ以外の業務に集中できない。
▼ 解決策¶
- インシデントが発生したときに、無秩序的ではなく、組織的に担当者を配置する。
- インシデントコマンドシステムを採用し、インシデントの対応の組織化する。
4. 根本原因 = ヒューマンエラー¶
▼ パターンの概要¶
ヒューマンエラーが、インシデントの根本原因 (ただ 1 個の原因) であると見なしてしまうこと。
▼ 問題点¶
ヒューマンエラーが根本原因だったとしても、人間にはさまざまな状況が背景にあり、不正確な原因しか突き止められない。
▼ 解決策¶
- インシデントの発生時には解決に注力する
- インシデントが発生したとき、ヒューマンエラーを原因と見なし、原因となった犯人を突き止めようとしない。
- 犯人を突き止めても、インシデントを解決した気にならないように心がける。
- あくまで、インシデントそのものを解決することだけに専念する。
- 事後評価ではインシデントの原因が
1個だと考えない- インシデントの事後評価では、ヒューマンエラー、ソフトウェア、ハードウェア、といった特定の何か
1個が根本の原因と判断しない。 - あらゆる側面から、複雑に絡み合う複数の原因や、寄与要因 (潜在的な原因) を突き止める。
- インシデントの事後評価では、ヒューマンエラー、ソフトウェア、ハードウェア、といった特定の何か
5. ページャーの引き渡し¶
▼ パターンの概要¶
開発に携わっていない人にオンコールを任せてしまうこと。
(ページャー:ポケベル)
▼ 問題点¶
- 自分自身の開発したシステムが本番環境でどのように振る舞うのか、といったことを学ぶ機会を奪う。
- アプリ領域に関係するインシデントを迅速に解決できなくなる。
▼ 解決策¶
- オンコールはすべてのエンジニアの仕事であり、アプリ開発チームは SREer にオンコールをすべて丸投げしないようにする。
- アプリ開発者もオンコールの担当になるようなルール (例:交代制、二次オンコール担当) を設ける。
6. マジックスモークを消すのは私だ!¶
▼ パターンの概要¶
インシデントの発生を予防するためのさまざまな行動よりも、インシデントの解決をもっとも高く評価すること。
▼ 問題点¶
- 現場のエンジニアが、忍耐的な作業にモチベーションを感じてしまう
- インシデントの担当者は適切に休めず、幸福度が下がる。
▼ 解決策¶
- インシデントを予防できる仕組みを作る。
- インシデントの解決よりも、予防する仕組みを作ることをより高く評価する文化を普及させる。
7. アラートリライアビリティエンジニアリング¶
▼ パターンの概要¶
あらゆるものをエラーベントと見なし、アラートを通知してしまうこと。
▼ 問題点¶
アラートが通知されるたびに、それ以外の作業が中断されてしまう。
▼ 解決策¶
ユーザーの満足度に影響を与える問題 (例:UX、単一障害点の異常、レプリカ数の過剰な減少) が発生した場合は、アラートを通知する。
8. ペットを散歩させてくれるドッグウォーカーを雇う¶
▼ パターンの概要¶
インフラのプロビジョニングツールを、イミュータブルなインフラを構築するためではなく、既存のミュータブルなインフラを冗長化させるために使用してしまうこと。
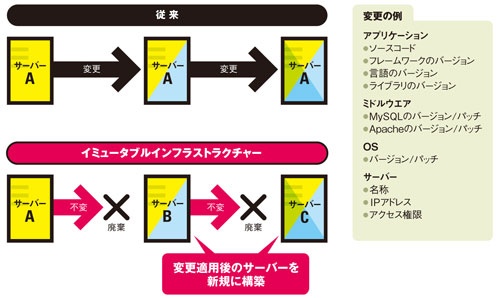
▼ 問題点¶
- プロビジョニングツールの使い方が間違っている。
- 状態の管理が煩雑になるため、ミュータブルなインフラはやめよう (個人的見解)
▼ 解決策¶
インフラのプロビジョニングツールは、イミュータブルなインフラを構築するために使用する。
9. スピードバンプエンジニアリング¶
▼ パターンの概要¶
信頼性を高めようと慎重になり、機能変更からリリースまでの間に、関門になるステップを設けてしまうこと。
▼ 問題点¶
- 関門となるステップ (例:変更管理委員会) が、必ずしも、機能変更のリリースによい付加効果をもたらすわけでもなく、またユーザーからの評価を提供してくれるわけでもない。
- 不要なステップがあると、変更、リリース、ユーザー評価のサイクルの速度が落ちるため、システムの信頼性が高まりにくくなる。
▼ 解決策¶
- 最小限の関門ステップ
- 関門ステップを設けるとしても、特定の状況下 (例:機能ではなくプロダクト全体のリリース) で、プロダクトの内容には無関係なステップ (例:キャパシティプランニングなど) のみにする。
- エラーバジェットの導入
- エラーバジェットを導入し、優先順位決めや承認のスピードを上げる。
10. 設計の難所¶
▼ パターンの概要¶
システム設計時の SREer のコンサルがボトルネックになってしまう。
▼ 問題点¶
SREer の役割の 1 個として、システムの設計段階でレビュー (例:派遣型、窓口型) を行う必要がある。
一方で、システムの数が多くなると、コンサルのステップがボトルネックになり、リリースの頻度が低くなる。
▼ 解決策¶
コンサルをフレームワーク化 (例:チェックリスト) したり、ツールで自動的にコンサル可能にする。
11. 棒が多すぎてニンジンが不足¶
▼ パターンの概要¶
SREing の実現に必要なツールをアプリ開発チームに導入したいとき、まず提案するのではなく、使用を強制してしまうこと。
▼ 問題点¶
- SREing はプッシュ型ではなくプル型であり、アプリ開発チームから課題を聞き出す必要がある。
- ツールをプッシュ型で強制的に導入した結果、エンジニアの開発がより非効率になることがある。
▼ 解決策¶
アプリ開発者チームから、開発の効率性に関する課題を聞き出し、それに合ったツールを提案する。
12. プロダクションの延期¶
▼ パターンの概要¶
リリース前にエラーイベントの原因になりそうなことを未然にすべて解決しようとしてしまうこと。
▼ 問題点¶
機能変更からリリースまでに必要以上に時間がかかると、ユーザーからの評価が遅くなる。
▼ 解決策¶
- テストの自動化
- あらゆるエラーイベントを予防するために、機能変更のリリース前にテストを実施することは重要である。しかし、リリースまでに必要以上に時間がかからないようにする。そのために、テストを自動化して時間を短縮する。
- ユーザーからの評価を素早く得る
- ユーザーからの評価を素早く得られる Testing in production を含むデプロイ手法 (例:ダークローンチ、カナリアリリース) を採用する。
- ロールフォワード、ロールバックの自動化
- リリース前の予防を完璧にしない。代わりに、リスクヘッジとして、リリース後のロールフォワードとロールバックを自動で実行できるようにする。
- Progressive Delivery を採用し、SLO を判定基準とした自動ロールバックを実現する。
-
- リリース前の予防を完璧にしない。代わりに、リスクヘッジとして、リリース後のロールフォワードとロールバックを自動で実行できるようにする。
13. リカバリー時間ではなく障害回避の最適化 (MTTF > MTTR)¶
▼ パターンの概要¶
MTTF を重要視し、MTTR を軽視してしまうこと。
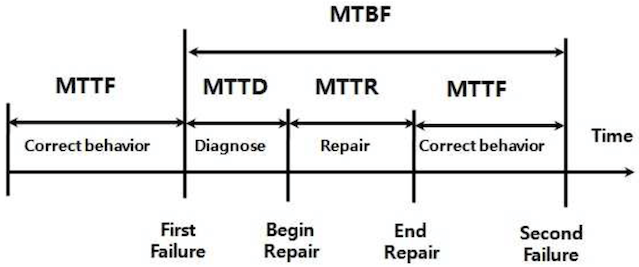
▼ 問題点¶
障害が発生するのは避けられず、MTTF の最適化は現実的でない。よって、MTTR を短縮するべきである。
▼ 解決策¶
- 障害の範囲の縮小
- 障害範囲 (あるいは blast-radius) を最小限にする。
- 回復力の向上
- 人間による修復は時間がかかるため、人間ができるだけ介入せずに修復できるように心がける。
- 回復力の維持
- Testing in production (例:カナリアリリース中のテスト、カオスエンジニアリング) を定期的に実行することにより、システムがデグレーションしないようにし、回復力を維持する。
14. 依存性地獄¶
▼ パターンの概要¶
システムが新旧さまざまなコンポーネントからなる場合、コンポーネント間の依存関係が闇になってしまっていること。
▼ 問題点¶
新旧コンポーネント間の依存関係が闇になっており、とある機能変更の影響範囲を人間が予測不可能である。
▼ 解決策¶
機能変更によって、コンポーネント間にどのような依存関係が新しく追加されるかを自動的に検出し、記録可能にする。
15. 小回りの利かないガバナンス¶
▼ パターンの概要¶
組織単位ではなく、プロジェクト単位で承認/予算策定/成果が設計されてしまうこと。
▼ 問題点¶
プロジェクト単位で承認/予算割り当て/成果が求められると、種々の問題が起こり、アジャイル開発を実現できない。例えば、予算割り当てに時間がかる、不要な機能がそのまま残る、開閉が繰り返されるプロジェクトなどである。
▼ 解決策¶
組織単位で承認/予算割り当て/成果を設計する。
また、各組織は、目標 (例:方針管理、Catchball、OKR) までのプロセスに対して、自由に承認/予算策定/成果を設計する。
16. 不適切な「おやおや」のSLO¶
▼ パターンの概要¶
ビジネスとは無関係に SLO を決めてしまっていること。
また、一度決まった SLO が更新されないままになってしまうこと。
▼ 問題点¶
ユーザーニーズに基づいた SLO ではないため、いずれシステムの不備 (例:スループット不足、過負荷、ハードウェアキャパシティ不足) が浮き彫りになる。
また、SLO が最新の状況に則していないと、ユーザーからの評価を下げることになる。
▼ 解決策¶
ビジネス側と話し合い、ユーザーニーズ、ビジネスの収益、に基づいた SLO を設定する。
ビジネスと SLO の双方向で、定期的に更新する (例:SLO に合わせて営業時間を更新する) 。
また SLO は高過ぎればよいということもなく、例えば 99.5%と 99.9%の信頼性の間でユーザー評価が変わらないのであれば、労力をかけて 99.99%にする必要はない。
17. ファイアウォール越しにAPIを投げ渡す¶
▼ パターンの概要¶
パートナーに機能 (例:API) を提供するようなビジネスをしている場合、パートナーの SLO に無関心で、自社の SLO のみを守ろうとしてしまうこと。
▼ 問題点¶
自社がパートナーの問題への関心を欠くと、チーム間の無関心で起こる問題と同様のことが起こる。
▼ 解決策¶
- 共通認識からなる SLI と SLO の設定
- 自社とパートナーの間で SLI を共有し、自社とパートナーのシステムを合わせた SLO を設定する。
- インシデントを共通管理
- 自社とパートナーの間でインシデントを共通管理し、協働的に解決できるようにする。例えば、対処の権限をお互いに与える。
18. 運用チームの修復¶
▼ パターンの概要¶
運用手法のみを改善すれば SREing を実践できる、と考えてしまうこと。
▼ 問題点¶
SREing の実践のために、運用だけではなく、ビジネス、システム、チームも改善する必要がある。例えば、優先順位付け、計画と実行、意思決定、設計、構築、トイル、ヒューマンエラー、コミュニケーションなどである。
SREing の最終目標はシステムの信頼性を高めることであり、これらはその手段である。
▼ 解決策¶
上層部から理解が得られず、SREing を十分に実践できなくとも、少なくともシステムとチームは改善できる。
19. 最後にもう一言¶
- SREing のアンチパターンは、変化し続ける。
- 筆者が集めたアンチパターンは、全体のほんの一部分でしかない。
- SREing の失敗事例を、自社内外問わず、共有していく必要がある。
- 失敗事例があれば、Twitter アカウント
@BlakeBisset宛に、#SREantipatternsをつけて共有してほしい。