サービスレベル@監視¶
はじめに¶
本サイトにつきまして、以下をご認識のほど宜しくお願いいたします。
01. SLI:Service Level Indicator (サービスレベル指標)¶
SLIとは¶
サービスレベルの指標とするメトリクスのこと。
SLIの決め方¶
▼ ユーザージャーニー (カスタマージャーニー)¶
『カスタマージャーニー』とも言う。
ユーザーが問題を解決するために辿る一連の行動のこと。
▼ クリティカルユーザージャーニーとSLI¶
ユーザージャーニーのなかでも、特にビジネスの収益への影響力が多いもののこと。
クリティカルジャーニーで実行されるアプリケーション機能に関するページのメトリクス (例:ステータスコード、レイテンシー) を SLI とする。
*例*
EC サイトであれば、以下の一連の行動がクリティカルユーザージャーニーとなる。
(1)-
商品を検索する。
(2)-
該当の商品を閲覧する。
(3)-
商品をカートに追加する。
(4)-
商品を購入する。
SLIの例¶
▼ メトリクスの例 (Google)¶
クリティカルユーザージャーニーの満足度に影響を与えるメトリクス (リクエストとレスポンスの可用性/遅延/品質、データ処理のカバレッジ/正確性/鮮度/スループット、ストレージのスループット/遅延など) を SLI とするとよい。
▼ メトリクスの例 (Microsoft)¶
MTtx メトリクスを SLI とし、そのダッシュボードを作成するとよい。
その他、可用性や QoS:Quality of Service に関するメトリクスを SLI に選択するとよい。
具体的には、可用性は稼働時間を基に定量化できる。
▼ REDメトリクス¶
RED メトリクスを SLI として使用する。
02. SLO:Service Level Objective (サービスレベル目標)¶
SLOとは¶
SLA に基づく指標の目標値のこと。
ユーザーの視点で策定する必要があるが、ブラウザやユーザー起因の問題を加味したメトリクスを使用することは大変なため、基本的には自身のシステムのみを対象としたメトリクスを使用することが多い。
SLO は 一定期間における 99.9%の成功率を目標とすることが多い。
その一方で、SLO 達成の業務のせいで機能変更業務が全くできず、リリースを完全に止めざるを得ない場合がある。
これは SLO が厳しすぎる状況であるため、下方修正してもよい。
SLO だけがユーザーの満足度を決めるわけではなく、新機能のリリースがユーザーの満足度を高めることがあるため、問題ない。
また、サイトの一部の機能が社内部署向け (例:マーケティング部) の場合は、社内向けの SLO となる。
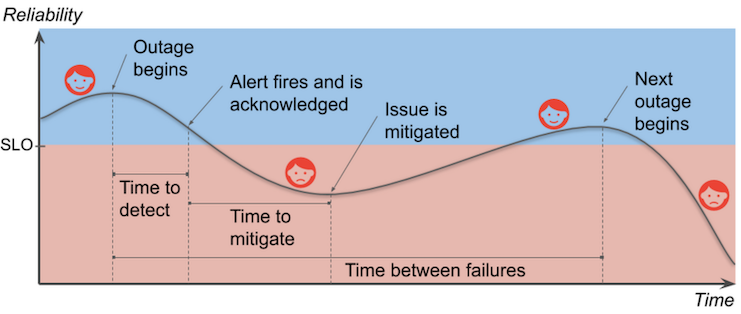
エラーバジェット¶
▼ エラーバジェットとは¶
年月当たりで SLO 違反 (エラー、ダウンタイムなど) の累計許容割合こと。
エラーやダウンタイムの発生によって、システムの信頼性に影響を与える可能性があった場合、その累計をエラーバジェットとする。
年月当たりでエラーバジェットが許容範囲内であれば、技術を優先する。
ビジネスより技術を優先する場合に素早く意思決定できる。
(エラーバジェット) < 100% - SLO%
例
稼働時間を SLI とし、1 ヶ月間 (720 時間) の稼働時間の SLO を 99%とした場合、エラーバジェットは 1% (7.2 時間) になる。
累計 7.2 時間の SLO 違反は許容できる。
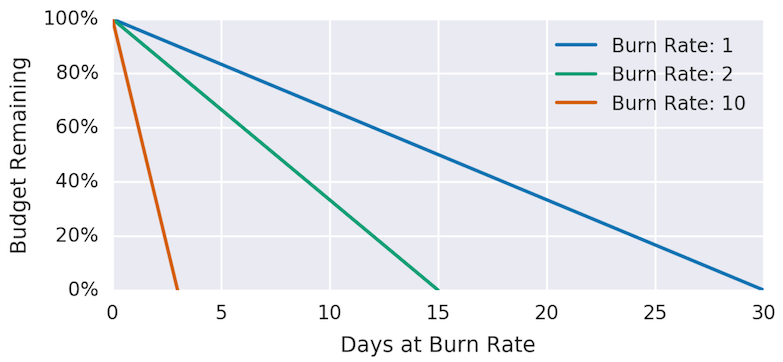
▼ バーンレート¶
エラーバジェットの消費速度を表すメトリクスのこと。
バーンレートを使用すれば、エラーバジェットの消費速度をエラーイベントとして通知できる。
バーンレートはどんなに大きくても、1 ヶ月分の SLO を 1 ヶ月で消費する大きさ出なければならない。
もし、バーンレートが 2 倍の大きさになれば、半月で SLO を消費してしまうことになる。
SLOの決め方¶
▼ 前提¶
SLA (顧客との合意) に基づいて、SLO を決める。
KPI (組織内での合意) に基づいた性能目標値とは区別したい。
▼ 目標値の例 (自社プロダクト)¶
| 項目 | 100% | 目標値 |
|---|---|---|
| 計画停止 | 計画停止は、1 ヶ月当たり 1 回まで、1 回当たり 3 時間まで、とする。 |
|
| サーバー稼働率 | サーバーが 24 時間稼働する。 |
0.01% (0.24 時間) 以内の時間にダウンタイムを抑えること。 |
| レスポンス速度 | 全リクエストの平均レスポンス速度が 3000ms (3 秒) である。 |
リクエストの 50%が 3000ms より早くレスポンスできること。 |
| 秒当たりの平均トランザクション数 | 登録 (100TPS) 、参照 (100TPS) 、変更 (100TPS) 、削除 (100TPS) とする。 |
|
| 障害対応 | 検知時間 (10 分以内) 、ビジネス側への発生報告 (20 分以内) 、障害一次対処 ( 1 時間以内) とする。 |
|
| RPO | 2 時間前以内とする。 |
|
| RTO | 2 時間以内とする。 |
|
| バックアップ保管期間 | 12 ヶ月とする。 |
|
| 復元時点 | 1 日前までとする。 |
|
| ログ保管期間 | 3 ヶ月とする。 |
|
| パケットのアプリケーションデータの暗号化強度 | SSL/TLSによる暗号化とする。 | |
| 問い合わせ | 国の定める祝日を除く月から金までの 9:00 ~ 17:00 とする。 |
▼ 目標値の例 (Datadog)¶
SLO を期間のパーセントで定めることにより、状況によらず、一定の基準を設けることができる。
目標値は、予測値を使用するとよい。
Datadog では、平常時のメトリクスのデータから予測値を算出してくれる。
| 指標 | 100% | 目標値 |
|---|---|---|
| サーバー稼働率 | サーバーが 24 時間稼働する。 |
0.01% (0.24 時間) 以内の時間にダウンタイムを抑えること。 |
| DB稼働率 | DBが 24 時間稼働する。 |
0.01% (0.24 時間) 以内の時間にダウンタイムを抑えること。 |
| レスポンス速度 | 全リクエストの平均レスポンス速度が 300msである。 |
リクエストの 50%が 300ms より早くレスポンスできること。 |
| レスポンスのステータスコード率 | 24 時間当たりの全リクエストが 200 ステータスである |
50% 以上のリクエストが 200 ステータスになること。 |
| スループット | 24 時間で、スループットが 50 件/秒 |
24 時間で、0.1% 以下の時間にスループット低下を抑えること。 |
▼ 目標値の例 (Google)¶
SLOの事後評価¶
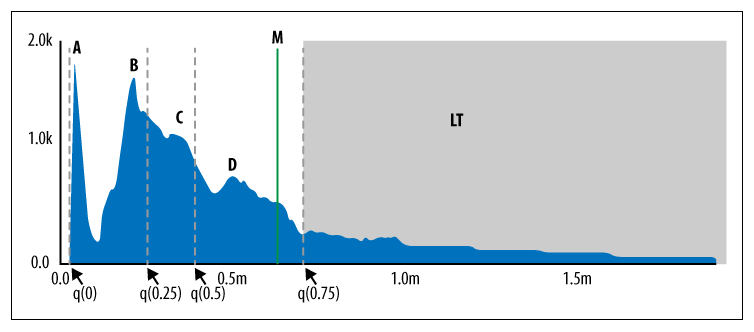
▼ 評価方法の例 (Circonus)¶
SLO を達成したか否かを判断する場合、ヒストグラムが有効である。
以下の図では、横軸に各リクエストのレイテンシー (ミリ秒) と縦軸にリクエスト数 (個) を表している。
また、分位ボックス (q(n)) により全データのうち何パーセントの集合かを表す。例えば、q(0.99) は、99% が 5ms 未満であることを示す。
LT (ロングテール) の先にある見えない最大値は 120ms である。
単なる最小値/最大値/中央値/平均値であると表面的な結果しか得られない。
しかし、このようなヒストグラムを使用すれば、各リクエストがどの程度のレイテンシー (≒レスポンスタイム) に、どのくらい分布しているかを正確に知られる。
例えば、SLO を『5ms 未満のレイテンシー (≒レスポンスタイム) 』に設定としたとして、ヒストグラムから 99.4597%がこれを満たしていると結論付けられる。
03. SLA:Service Level Agreement (サービスレベル合意)¶
SLAとは¶
インターネットサービスに最低限のサービスのレベルを保証し、これを下回った場合には返金する、といった契約のこと。
SLA として、例えば以下がある。
| 項目 | 説明 | レベル例 | 返金率 |
|---|---|---|---|
| サーバー稼働率 | サーバーの時間当たりの稼働率 | 99.9%以上 |
10% |
| 障害回復時間 | 障害が起こってから回復するまでの時間 | 2 時間以内 |
10% |
| 障害お問い合わせ | 障害発生時のお問い合わせ可能時間帯 | 24 時間 365 日 |
10% |
SLAの決め方¶
▼ 前提¶
KPI (組織内の合意) とは区別したい
▼ SLA導入前準備の例 (経産省)¶
経産省が SLA のガイドラインを策定している。
▼ 返金率の例 (AWS)¶
AWS ではサービスレベルの項目として、サーバー稼働率を採用している。
これに対して、ほとんどの AWS リソースで、以下の SLA が設定されている。
各リソースに SLA が定義されている。
*例*
Amazon EC2、AWS EBS、Amazon ECS、Amazon EKS の例を示す。
| 毎月の稼働率 | 発生したダウンタイム | 返金率 |
|---|---|---|
99.0%以上、99.99%未満 |
87.6~0.876 時間 |
10% |
95.0%以上、99.0%未満 |
438~87.6 時間 |
30% |
95.0%未満 |
438 時間以上 |
100% |
▼ 対応開始時間の例 (PureCloud)¶
記入中...
▼ 保証期間の例 (Google)¶
SLA は、サイト提供会社と利用者の合意で決める目標値である。
違反の規約が無ければ、SLA でなく SLO である。
SLA の補償期間は一日単位で設定するとよい。
SLA 違反の場合には、返金を補償とする場合があるが、これ以外の補償方法でもよい。