プラクティス集@K8s Cluster¶
はじめに¶
本サイトにつきまして、以下をご認識のほど宜しくお願いいたします。
01. 運用¶
CDパイプライン¶
ArgoCD 自体は ArgoCD 以外でデプロイする必要がある。
GitOps を採用できないため、CIOps になる。
本番環境に対して、ローカルマシンまたは CI ツール (例:GitHub Actions、CircleCI、GitLab CI、Takton など) を使用して、ArgoCD をデプロイする。
02. アップグレード¶
アップグレードの設計規約¶
▼ マイナーバージョン単位でアップグレード¶
アップグレード時、新旧バージョンのコントロールプレーン Node が並行的に稼働する。
基本的にはいずれのコントロールプレーン Node も、並行的に稼働するコンポーネントのバージョンを前方/後方の 1 個のマイナーバージョン以内に収める必要がある。
そのため、Kubernetes のアップグレードもこれに合わせて、後方の 1 個のマイナーバージョンにアップグレードしていくことになる。
マイナーバージョンを 2 個以上跨いだアップグレードは非推奨である。
▼ コントロールプレーンNodeでダウンタイムを発生させない¶
コントロールプレーン Node でダウンタイムが発生すると、Node コンポーネントが正常に稼働しなくなる。
これにより、システム全体がダウンタイムになる可能性がある。
ただし、コントロールプレーン Node の、kube-controller-manager、kube-scheduler、ではダウンタイムが発生することは許容する。
▼ コントロールプレーンNodeのデータを損失させない¶
コントロールプレーン Node のデータを損失させないようにする。
ただし、コンテナ内のローカルストレージの損失は許容する。
▼ 廃止されるAPIグループのバージョンを確認する¶
アップグレードに伴い、kube-apiserver で API グループのバージョンが廃止されることもある。
これにより、マニフェストで API グループのバージョンを宣言できなくなってしまうため、確認が必要である。
静的解析ツール (例:pluto、kubepug) を使用すると検出しやすい。
▼ 監視ツールで廃止されるメトリクスやクエリロジックを確認する¶
アップグレードに伴い、監視系リソース (例:Prometheus、Grafana) でメトリクス名やクエリロジックが廃止されることもある。
これにより、メトリクスの元になるデータポイントを収集できなくなってしまうため、確認が必要である。
▼ アップグレード後は、PodだけでなくWorkloadのコンディションとステータスを確認する¶
動作確認として、Ready コンディションと Running ステータスを kubectl get pod で確認する。
また加えて、Pod の作成が始まらないと、kubectl get pod コマンドに Pod 自体が表示されない。
そのため、kubectl get deployment で、Pod の管理リソース (例:Deployment) のすべての Pod が Ready コンディションかどうかを確認しておく。
▼ 自動アップグレードを採用できるのであれば採用する¶
一連のコマンドを自動化できるツール (例:AWS Step Function、Fablic など) を使用して、アップグレードの実行から動作確認を自動化する。
コントロールプレーンNodeのアップグレード¶
▼ コントロールプレーンNodeのアップグレードとは¶
まず最初に、コントロールプレーン Node をアップグレードする。
必要であれば、コントロールプレーン Node のアドオン (例:AWS CoreDNS、AWS kube-proxy、Amazon VPC CNI) を別々にアップグレードする。
▼ インプレース方式¶
コントロールプレーン Node の kube-apiserver のアップグレード時間がダウンタイムに相当する。
ただし、コントロールプレーン Node がマネージドなクラウドプロバイダーのいくつか (例:AWS) では、kube-apiserver でダウンタイムの発生しないアップグレード手法を採用している。
このアップグレードでは、コントロールプレーン Node はインプレース方式でアップグレードしても、ダウンタイムは発生しないことが保証される。ワーカーNode はダウンタイムが発生する可能性もある。
▼ ローリング方式¶
記入中...
ワーカーNodeのアップグレード¶
▼ ワーカーNodeのアップグレードとは¶
コントロールプレーン Node のアップグレードが終了したら、ワーカーNode をアップグレードする。
クラウドプロバイダーのマネージド Node グループを採用している場合、ワーカーNode が新しいマシンイメージに基づいてオートスケーリングされるように設定しておく。
| 方法 | 作業時間 | 手順の煩雑さ | ダウンタイム | 補足 |
|---|---|---|---|---|
| インプレース方式 | より短い | より簡単 | より長い | ダウンタイムが許されるなら、労力も時間もかからないのでオススメ。 |
| ローリング方式 (サージ方式、ライブ方式) | ^ | ^ | v | |
| ブルー/グリーン方式 | より長い | より難しい | なし | Clusterの作成の労力が、もう 1 個実行環境を作成することに相当する。 |
▼ インプレース方式¶
既存の Node グループ内のワーカーNode をそのままアップグレードする。
ワーカーNode のアップグレード時間がそのままダウンタイムになるため、メンテナンス時間を設けられる場合にのみ使用できる。
(1)-
ワーカーNode を削除する。
(2)-
ワーカーNode を再作成する。
▼ セルフマネージドなローリング方式 (サージ方式、ライブ方式)¶
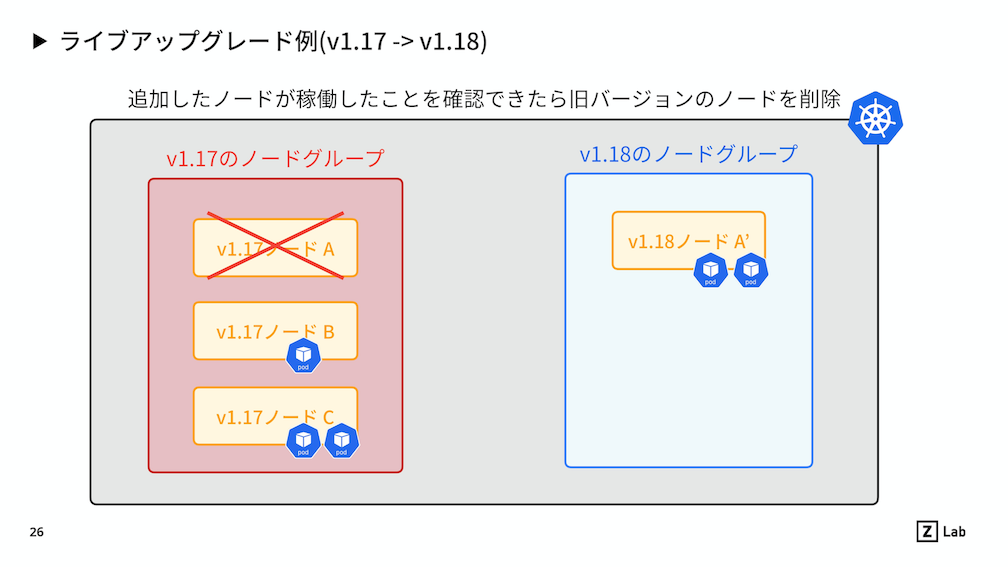
『サージ方式』『ライブ方式』ともいう。
新 Node グループを作成し、旧 Node グループ内のワーカーNode を順にドレインしていくことにより、アップグレードする。
一度にアップグレードするワーカーNode 数 (Surge 数) を増やすことにより、アップグレードの速さを調整できる。
デメリットとして、新バージョンを 1 つずつしかアップグレードできない。
(1)-
旧 Node グループ (Prod ブルー) を残したまま、新 Node グループ (Test グリーン) を作成する。
このとき、新 Node グループ内ワーカーNode 上には Pod が存在していないため、アクセスが新 Node グループにルーティングされることはない。
(2)-
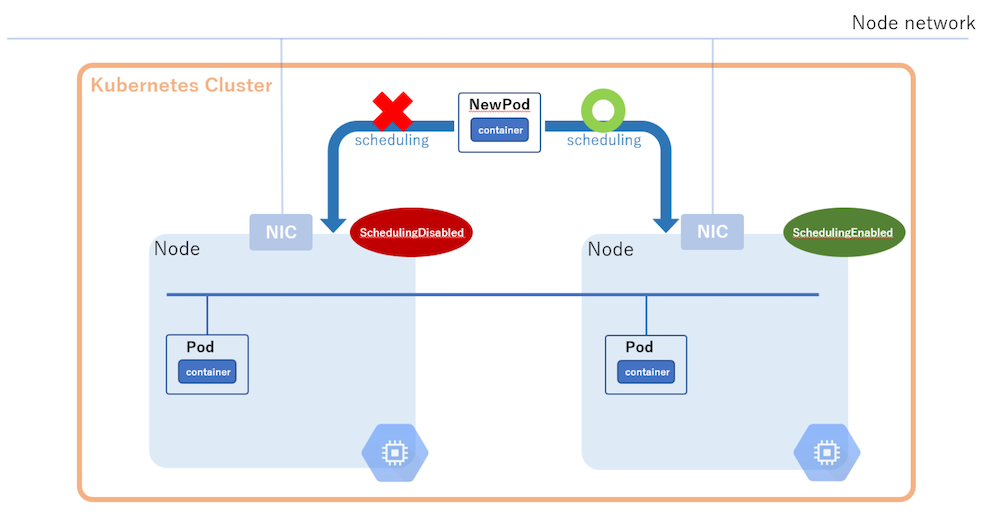
kubectl drainコマンドを実行することにより、旧 Node グループ内のワーカーNode でドレイン処理を開始させる。この時、DaemonSetのPodを退避させられるように、
--ignore-daemonsetsオプションを有効化する。また、EmptyDir Volumeを持つPodを退避させられるように
--delete-emptydir-dataオプションも有効化する。ドレイン処理によって、旧Nodeグループ内のワーカーNodeが
SchedulingDisabled状態になり、加えてこのワーカーNodeからPodが退避していく。その後、新Nodeグループ内のSchedulingEnabled状態のワーカーNode上で、Podを再スケジューリングさせる。
この時、旧Nodeグループ内ワーカーNode上にはPodが存在していないため、アクセスが旧Nodeグループにルーティングされることはない。
$ kubectl drain <旧Nodeグループ内のワーカーNode名> \
--ignore-daemonsets \
--delete-emptydir-data
(3)-
ドレイン処理が完了した後、新 Node グループ内ワーカーNode 上で Pod が正常に稼働していることを確認する。
(4)-
動作が問題なければ、旧 Node グループを削除する。
▼ マネージドなローリング方式¶
クラウドプロバイダー (例:AWS、Google Cloud) ではローリング方式をサポートしている。
クラウドプロバイダーの Node グループ (例:Amazon EKS Node グループ) では、新旧 Node グループを作成することにより、Node を入れ替える。
例えば Amazon EC2 の Auto Scaling グループであれば、アップグレードを開始すると EC2AutoScaling に新旧の起動テンプレートが紐づく。
新旧の起動テンプレート配下の EC2 Node を段階的に入れ替えることにより、ローリングアップグレードを実現する。
$ kubectl get node
NAME STATUS ROLES AGE VERSION
ip-*****.ap-northeast-1.compute.internal Ready <none> 19m v1.26.7-eks-*** # 作成した新しいK8sバージョンのNode
ip-*****.ap-northeast-1.compute.internal Ready <none> 19s v1.26.7-eks-***
ip-*****.ap-northeast-1.compute.internal NotReady,SchedulingDisabled <none> 66m v1.25.7-eks-*** # 削除中の古いK8sバージョンのNode
ip-*****.ap-northeast-1.compute.internal Ready <none> 21m v1.26.7-eks-***
ip-*****.ap-northeast-1.compute.internal NotReady,SchedulingDisabled <none> 75m v1.25.7-eks-***
ip-*****.ap-northeast-1.compute.internal NotReady,SchedulingDisabled <none> 73m v1.25.7-eks-***
▼ ブルー/グリーン方式 (マイグレーション方式)¶
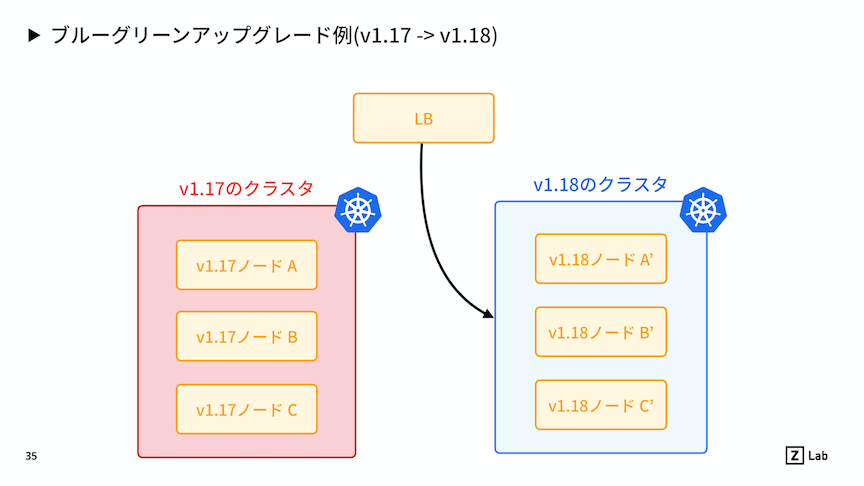
『マイグレーション方式』ともいう。
新しい Cluster を作成することにより、ワーカーNode をアップグレードする。
いずれ (例:L7 ロードバランサー) を基点にしてルーティング先を切り替えるかによって、具体的な方法が大きく異なる。
メリットとして、バージョンを 1 つずつのみでなく飛び越えてアップグレードできる。
(1)-
旧 Cluster (Prod ブルー) を残したまま、新 Cluster (Test グリーン) を作成する。新 Cluster には、すべての Kubernetes リソースが揃っている。
(2)-
社内から、新 Cluster に特定のポート番号でアクセスし、動作を確認する。
(3)-
動作が問題なければ、社外を含む全ユーザーのアクセスのルーティング先を新 Cluster に変更する。新 Cluster から旧 Cluster へロールバックする場合に備えて、旧 Cluster は削除せずに残しておく。
ツール別¶
▼ ArgoCD¶
ArgoCD の場合、チャート (ArgoCD のコンテナイメージ) と CRD の両方のアップグレードする。
ArgoCD を Namespaced スコープで分割している場合、カスタムリソースが Cluster 内に 1 つしかない CRD を共有しているため、CRD をアップグレードすると全サービスのカスタムリソースに影響が出る。
この場合、カスタムリソースへの影響を考えて、CRD の差分がないバージョンまでは ArgoCD をアップグレードできる。
kubectl diff コマンドで、現在と新 CRD の間に差分があるかどうかを確認できる。
$ kubectl diff -k "https://github.com/argoproj/argo-cd/manifests/crds?ref=<アップグレード先のArgoCDのバージョン>"
もし CRD に差分がある大きなアップグレードの場合、別の Cluster を新しく構築し、そのうえで新 ArgoCD も構築することとする。
▼ aws-loadbalancer-controller¶
aws-loadbalancer-controller の場合、チャートをアップグレードする。
各サービスの ALB への影響を考えて、CRD の差分がないバージョンまでは aws-loadbalancer-controller をアップグレードできる。
kubectl diff コマンドで、現在と新 CRD の間に差分があるかどうかを確認できる。
$ kubectl diff -k "https://github.com/kubernetes-sigs/aws-load-balancer-controller/helm/aws-load-balancer-controller/crds?ref=<アップグレード先のaws-loadbalancer-controllerのバージョン>"
▼ descheduler¶
descheduler の場合、チャートをアップグレードする。
ArgoCD のリソースに影響がないため、アップグレードは問題ない。
▼ external-dns¶
external-dns の場合、チャートをアップグレードする。
ArgoCD のリソースに影響がないため、アップグレードは問題ない。