ネットワーク@Kubernetes¶
はじめに¶
本サイトにつきまして、以下をご認識のほど宜しくお願いいたします。
01. Nodeネットワーク¶
Nodeネットワークとは¶
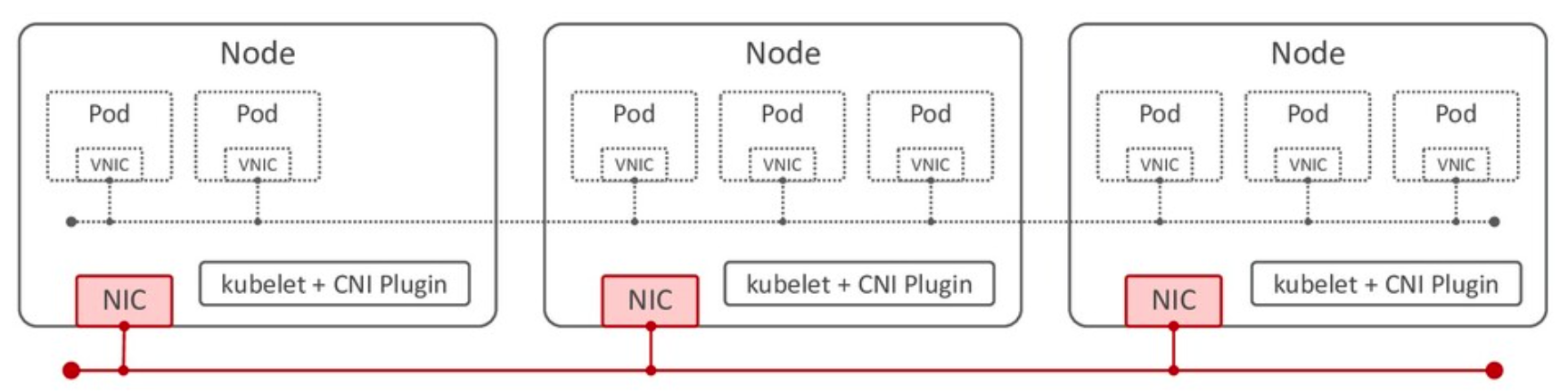
同じサブネットマスク内にある Node の NIC 間を接続するネットワーク。
Node ネットワークの作成は、Kubernetes の実行環境のネットワークが担う。
02. Serviceネットワーク¶
Serviceネットワークとは¶
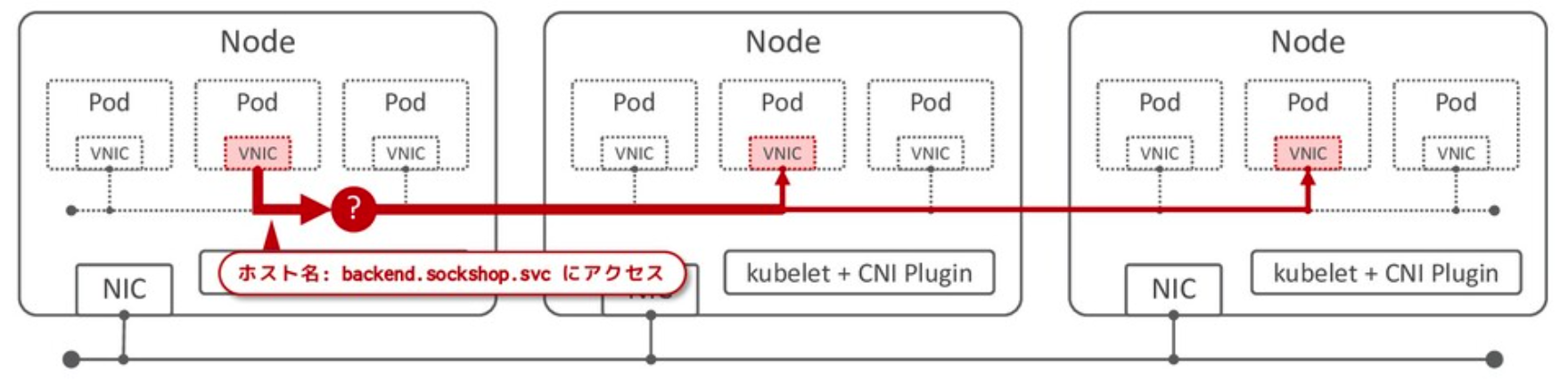
Pod のアウトバウンド通信に割り当てられたホスト名を認識し、そのホスト名を持つ Service までリクエストを送信する。
Service ネットワークの作成は、Kubernetes が担う。
03. Clusterネットワーク¶
Clusterネットワークとは¶
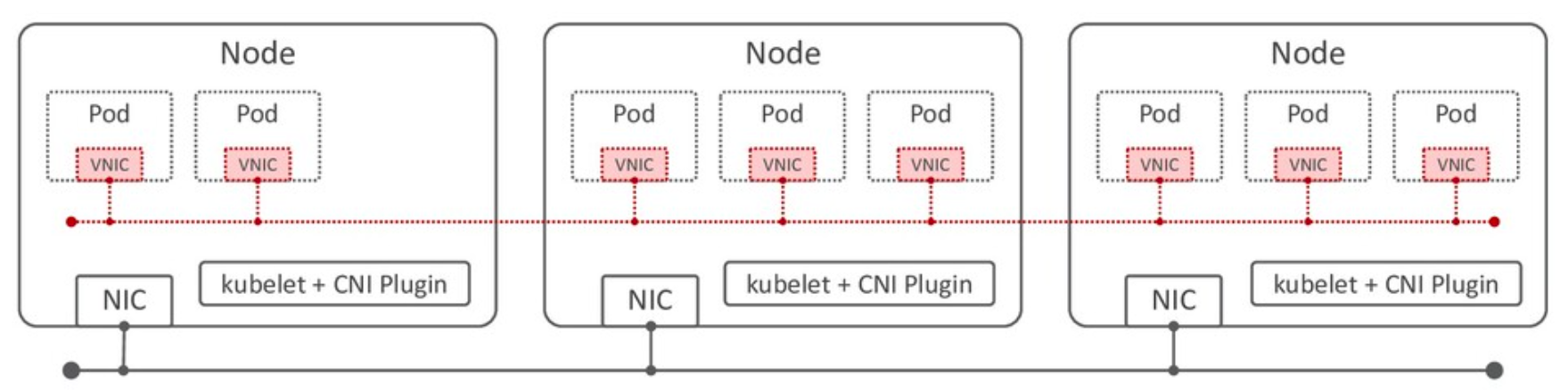
同じ Cluster ネットワーク内にある Pod の仮想 NIC (veth) 間を接続するネットワーク。
Cluster ネットワークの作成は、CNI が担う。
04. Podネットワーク¶
Podネットワークとは¶
Pod 内のネットワークのみを経由して、他のコンテナにリクエストを送信する。
Pod ごとにネットワークインターフェースが付与され、また IP アドレスが割り当てられる。
名前空間¶
▼ 名前空間の種類¶
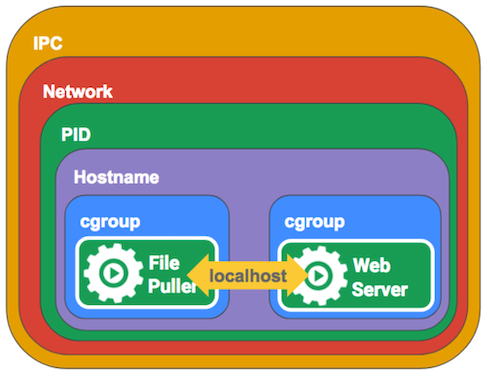
Pod のネットワークは複数の種類の名前空間から構成される。
ネットワークの範囲に応じて、コンテナが同じ Node 内のいずれのコンポーネントのプロセスと通信できるようになるのかが決まる。
注意点として、Docker とは名前空間の種類が異なる。
▼ IPC名前空間¶
プロセスは、同じ IPC 名前空間に属するほかのプロセスと通信できる。
Kubernetes のセキュリティ上の理由から、デフォルトでは Pod 内のコンテナはホスト (Node) とは異なる IPC 名前空間を使用し、ネットワークを分離している。
そのため、コンテナのプロセスは Node のプロセスと通信できないようになっている。
Network名前空間¶
PID名前空間¶
Hostname名前空間¶
cgroup名前空間¶
05. ネットワークレイヤー¶
Ingress Controller由来の L7 ロードバランサーの場合¶
Ingress Controller の場合、L7 ロードバランサーをプロビジョニングする。
Ingress Controller による L7 ロードバランサーは、受信した通信を Service にルーティングする。
Service は L4 ロードバランサーとして、インバウンド通信を Pod にルーティングする。
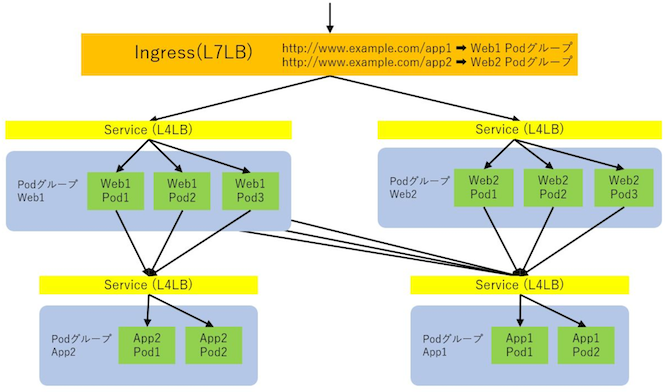
LoadBalancer Service由来の L4 ロードバランサーの場合¶
LoadBalancer Service の場合、L4 ロードバランサーをプロビジョニングする。
06. Pod間通信¶
Pod間通信の経路¶
Pod 内のコンテナから宛先の Pod にリクエストを送信する。
このとき、Pod をスケジューリングさせている Node が同じ/異なるかのいずれの場合で、経由するネットワークが異なる。
| 条件 | 経由するネットワーク |
|---|---|
| Nodeが異なる場合 | Nodeネットワーク + Clusterネットワーク + Serviceネットワーク |
| Nodeが同じ場合 | Clusterネットワーク + Serviceネットワーク |
通信方法¶
同じ Pod 内のコンテナ間は『localhost:<ポート番号>』で通信できる。
# Pod内のコンテナに接続する。
$ kubectl exec -it <Pod名> -c <コンテナ名> -- bash
[root@<Pod名>:~] $ curl -X GET http://127.0.0.1:<ポート番号>
PodのIPアドレスを指定する場合¶
▼ 仕組み¶
Pod 内のコンテナで、宛先の Pod の IP アドレスやポート番号を直接的に指定する。
ただし、Pod の IP アドレスは動的に変化するため、現実的な方法ではない。
*例*
foo-pod から、IP アドレス (11.0.0.1) とポート番号 (80) を指定して、bar-pod にパケットを送信してみる。
$ kubectl exec \
-it foo-pod \
-n foo-namespace \
-- bash -c "traceroute 11.0.0.1 -p 80"
traceroute to 11.0.0.1 (11.0.0.1), 30 hops max, 46 byte packets
1 *-*-*-*.prometheus-kube-proxy.kube-system.svc.cluster.local (*.*.*.*) 0.007 ms 0.022 ms 0.005 ms
2 *-*-*-*.prometheus-node-exporter.prometheus.svc.cluster.local (*.*.*.*) 1.860 ms 1.846 ms 1.803 ms
3 11.0.0.1.bar-service.bar-namespace.svc.cluster.local (11.0.0.1) 1.848 ms 1.805 ms 1.834 ms # 宛先のPod
$ kubectl exec \
-it foo-pod \
-n foo-namespace \
-- bash -c "traceroute -n 11.0.0.1 -p 80"
traceroute to 11.0.0.1 (11.0.0.1), 30 hops max, 46 byte packets
1 *.*.*.* 0.007 ms 0.022 ms 0.005 ms
2 *.*.*.* 1.860 ms 1.846 ms 1.803 ms
3 11.0.0.1 1.848 ms 1.805 ms 1.834 ms # 宛先のPod
ServiceのIPアドレスを指定する場合¶
▼ 仕組み¶
kubelet は、Pod 内のコンテナに Service の宛先情報 (プロトコル、IP アドレス、ポート番号) を出力する。
Pod 内のコンテナは、これを使用し、Service を介して Pod にリクエストを送信する。
*実装例*
foo-service という Service を作成した場合の環境変数を示す。
$ kubectl exec -it foo-pod -- printenv | sort -n
FOO_APP_SERVICE_PORT=tcp://10.110.235.51:80
FOO_APP_SERVICE_PORT_80_TCP=tcp://10.110.235.51:80
FOO_APP_SERVICE_PORT_80_TCP_ADDR=10.110.235.51
FOO_APP_SERVICE_PORT_80_TCP_PORT=80
FOO_APP_SERVICE_PORT_80_TCP_PROTO=tcp
FOO_APP_SERVICE_SERVICE_HOST=10.110.235.51
FOO_APP_SERVICE_SERVICE_PORT=80
FOO_APP_SERVICE_SERVICE_PORT_HTTP_ACCOUNT=80
Serviceの完全修飾ドメイン名を指定する場合¶
▼ 仕組み¶
Kubernetes に採用できる権威 DNS サーバー (kube-dns、CoreDNS、HashiCorp Consul など) は、Service の NS レコードを管理し、Service の完全修飾ドメイン名で名前解決できるようになる。
Pod のスケジューリング時に、kubelet は Pod 内のコンテナの /etc/resolv.conf ファイルに権威 DNS サーバーの IP アドレスを設定する。
Pod 内のコンテナは、自身の /etc/resolv.conf ファイルで権威 DNS サーバーの IP アドレスを確認し、DNS サーバーから宛先 Pod の IP アドレスを正引きする。
レスポンスに含まれる宛先の Pod の IP アドレスを使用して、Pod にリクエストを送信する。
# Pod内のコンテナに接続する。
$ kubectl exec -it <Pod名> -c <コンテナ名> -- bash
# コンテナのresolv.confファイルの中身を確認する
[root@<Pod名>] $ cat /etc/resolv.conf
# 権威DNSサーバーのIPアドレス
nameserver 10.96.0.10
search default.svc.cluster.local svc.cluster.local cluster.local
# 名前解決時のローカルドメインの優先度
options ndots:5
▼ ndots¶
宛先コンテナの名前解決時のドット数を設定する。
ドット数が多ければ多いほど、ローカルドメインから網羅的に名前解決を実施するため、ハードウェアリソースの消費が高くなる。
例えば、ndots:5 とした Pod が example.com を名前解決する場合、ドット数は 5 になる。
そのため、最初は example.com.default.svc.cluster.local. から名前解決を始め、example.com. で終わる。
(1)-
example.com.default.svc.cluster.local. (2)-
example.com.svc.cluster.local. (3)-
example.com.cluster.local. (4)-
example.com.ec2.internal. (5)-
example.com.
07. 通信のデバッグ¶
Podのアウトバウンド通信のデバッグ¶
▼ kubectl run コマンド¶
kubectl exec コマンドが運用的に禁止されているような状況がある。
そのような状況下で、シングル Node の場合は、kubectl run コマンドで --rm オプションを有効化する。そして、Cluster ネットワーク内に curl コマンドによる検証用の Pod を一時的に新規作成する。
# シングルNodeの場合
# curl送信用のコンテナを作成する。
# rmオプションを指定し、使用後に自動的に削除されるようにする。
$ kubectl run \
-n default \
-it multitool \
--image=praqma/network-multitool \
--rm \
--restart=Never \
-- /bin/bash
# curlコマンドでデバッグする。
[root@<Pod名>:~] $ curl -X GET https://<Serviceの完全修飾ドメイン名やIPアドレス>
# tcptracerouteコマンドでデバッグする。
[root@<Pod名>:~] $ tcptraceroute <Serviceの完全修飾ドメイン名やIPアドレス>
# mtrコマンドでデバッグする。
[root@<Pod名>:~] $ mtr <Serviceの完全修飾ドメイン名やIPアドレス>
▼ kubectl debug node コマンド¶
マルチ Node の場合は、指定した Node 上で Pod を作成できない。
(たぶん) 名前が一番昇順の Node 上で Pod が作成されてしまい、Node を指定できない。
そのため、代わりに kubectl debug コマンドを使用する。
ただし、kubectl debug コマンドで作成された Pod は、使用後に手動で削除する必要がある。
# マルチNodeの場合
# Podが稼働するNodeを確認する。
$ kubectl get pod <Pod名> -o wide
# 指定したNode上で、curl送信用のコンテナを作成する。
# rmオプションはない。
$ kubectl debug node/<Node名> \
-n default \
-it \
--image=praqma/network-multitool
[root@<Pod名>:~] $exit
# 使用後は手動で削除する。
$ kubectl delete -n default node-debugger-*****
▼ デバッグ用Podを起動しておく¶
デバッグ用 Pod を起動しておく方法もある。
curl コマンド専用イメージを使用する場合、コンテナ起動後に curl コマンドを実行し、すぐに終了してしまう。
そのため、CrashLoopBackOff になってしまう。
これを防ぐために、sleep infinity コマンドを実行し、ずっとスリープするようにしておく。
apiVersion: apps/v1
kind: Deployment
metadata:
name: foo
spec:
replicas: 1
selector:
matchLabels:
app: foo
template:
metadata:
labels:
app: foo
spec:
containers:
- name: foo-curl
image: curlimages/curl:8.5.0
imagePullPolicy: IfNotPresent
command:
- sleep
- infinity