DML@SQL¶
はじめに¶
本サイトにつきまして、以下をご認識のほど宜しくお願いいたします。
01. DMLとは¶
テーブル上のレコードを操作するクエリのこと。
02. SELECT¶
はじめに¶
▼ 句の処理の順番¶
FROM ---> JOIN ---> WHERE ---> GROUP BY ---> HAVING ---> SELECT ---> ORDER BY
SELECT¶
▼ なし¶
指定したカラムを取得する。
MySQL では、取得結果の並び順が毎回異なるため、プライマリーキーの昇順で取得したい場合は、ORDER BY を使用して、明示的に並び替えるようにする。
SELECT * FROM <テーブル名>;
▼ SUM() 関数¶
指定したカラムで、『フィールド』の合計を取得する。
SELECT SUM(<カラム名>) FROM <テーブル名>;
▼ AVG() 関数¶
指定したカラムで、『フィールド』の平均値を取得する。
SELECT AVG(<カラム名>) FROM <テーブル名>;
▼ MIN() 関数¶
指定したカラムで、『フィールド』の最小値を取得する。
SELECT MIN(<カラム名>) FROM <テーブル名>;
▼ MAX() 関数¶
指定したカラムで、『フィールド』の最大値を取得する。
SELECT MAX(<カラム名>) FROM <テーブル名>;
▼ COUNT() 関数¶
指定したカラムで、『フィールド』の個数を取得する。
SELECT <カラム名> COUNT(*) FROM <テーブル名>;
※消去法の小技:集合関数を入れ子状にはできない
*実装例*
集合関数を、集合関数のなかへ入れ子状にできない。
SELECT AVG(SUM(<カラム名>)) FROM <テーブル名>;
指定したカラムで、値無しも含む『フィールド』を取得する。
SELECT COUNT(<カラム名>) FROM <テーブル名>;
指定したカラムで、値無しを除いた『フィールド』を取得する。
SELECT COUNT(<カラム名>);
▼ LAST_INSERT_ID() 関数¶
任意のテーブルへ最後に挿入された ID を読み出す。
テーブル名を指定する必要はない。
SELECT LAST_INSERT_ID();
▼ MD5() 関数¶
文字列をハッシュ化
SELECT MD5("foo");
CASE¶
カラム 1 が true だったら、カラム 2 を取得する。
false であったら、カラム 3 を取得する。
SELECT
CASE
WHEN <エイリアス>.<カラム名1> = 1 THEN <エイリアス>.<カラム名2>
ELSE <エイリアス>.<カラム名3>
END AS name
FROM
<テーブル名> AS <エイリアス>;
FROM¶
▼ JOIN の種類¶
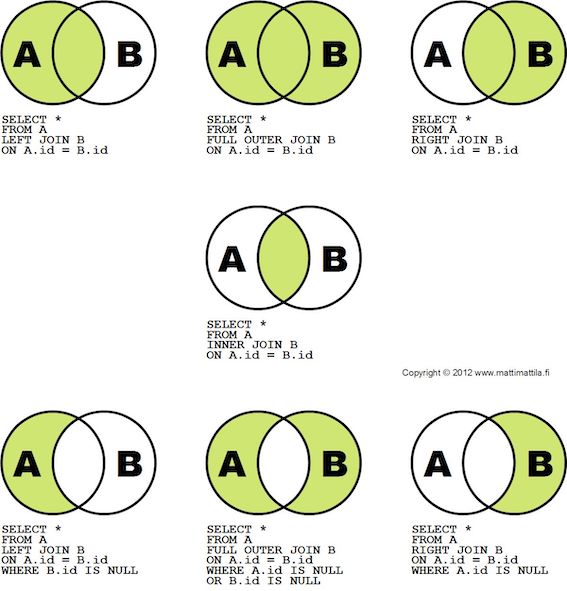
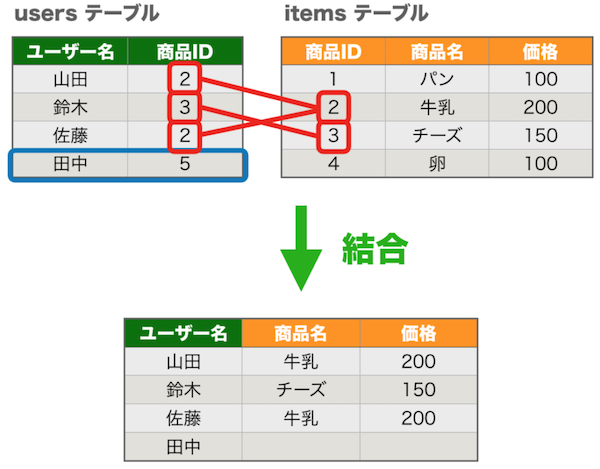
▼ LEFT JOIN (左外部結合)¶
『users』テーブルと『items』テーブルの商品 ID が一致しているデータと、元となる『users』テーブルにしか存在しないデータが、セットで取得される。
▼ INNER JOIN (内部結合)¶
基本情報技術者試験では、内部結合 (A∩B) しか出題されない。
▼ 内部結合に WHERE を使用する場合¶
2 個の WHERE 文が、AND で結びつけられているとき、まず 1 つ目の WHERE を満たすレコードを読み込んだ後、取得したレコードのなかから、2 つ目の WHERE を満たすレコードを読み込む。
*実装例*
-- 『カラム』のみでなく、どの『表』なの物なのかも指定
SELECT
<テーブル名1>.<カラム名1>,
-- 複数の表を指定
FROM
<テーブル名1>,
<テーブル名2>,
-- まず、1つ目のフィールドと2つ目のフィールドが同じレコードを読み込む。
WHERE
-- 次に、上記で取得したレコードのうち、次の条件も満たすレコードのみを取得する。
<レコード名1> = <レコード名2>
AND <レコード名2> = <レコード名3>
▼ 内部結合に INNER JOIN ON を使用する場合¶
*実装例*
-- 『カラム』のみでなく、どの『表』なの物なのかも指定
SELECT
<テーブル名1>.<カラム名1>,
-- 複数の表を指定
FROM
<テーブル名1>
-- 2つ目の表の『レコード』と照合
INNER JOIN <テーブル名2>
ON <テーブル名1>.<カラム名1> = <テーブル名2>.<カラム名2>
-- 3個目の表の『レコード』と照合
INNER JOIN <テーブル名3>
ON <テーブル名1>.<カラム名1> = <テーブル名3>.<カラム名3>
ORDER BY¶
▼ 使い方¶
*実装例*
<?php
$joinedIdList = implode(",", $idList);
// 並び替え条件を設定
$expression = call_user_func(function () use ($orders, $joinedIdList) {
if ($orders) {
foreach ($orders as $key => $order) {
switch ($key) {
case "id":
return sprintf("ss.id %s", $order);
}
}
}
// IN句順の場合
return sprintf("FIELD(ss.id, %s)", $idList);
});
$sql = <<<SQL
SELECT
name
FROM
table
ORDER BY {$expression}
SQL;
IN、ANY の違い¶
▼ IN の使い方¶
指定した値と同じ『フィールド』を取得する。
*実装例*
指定したカラムで、指定した値の『フィールド』を取得する。
SELECT * FROM <テーブル名> WHERE <カラム名> in (foo, bar,...);
指定したカラムで、指定した値以外の『フィールド』を取得する。
SELECT * FROM <テーブル名> WHERE <カラム名> not in (<レコード名1>, <レコード名2>,...);
指定したカラムで、SELECT で読み出した値以外の『フィールド』を取得する。
SELECT * FROM <テーブル名> WHERE <カラム名> not in (SELECT <カラム名> FROM <テーブル名> WHERE <レコード名> >= 160);
【IN句を使用しなかった場合】
SELECT * FROM fruit WHERE name = "みかん" OR name = "りんご";
【IN句を使用した場合】
SELECT * FROM fruit WHERE name IN("みかん", "りんご");
▼ ANY の使い方¶
書き方が異なるのみで、in と同じ出力
SELECT * FROM <テーブル名> WHERE <カラム名> = ANY(foo, bar, baz);
GROUP BY¶
▼ 使い方¶
カラムをグループ化し、集合関数を使用して、フィールドの値を算出する。
*実装例*
指定したカラムをグループ化し、フィールドの値の平均値を算出する。
SELECT <カラム名1> AVG(<カラム名2>) FROM <テーブル名> GROUP BY <カラム名1>;
HAVING¶
▼ 使い方¶
各句の処理の順番から考慮して、GROUP BY でグループ化した結果から、HAVING で『フィールド』を取得する。
SELECT における集計関数が、HAVING における集計関数の結果を指定していることに注意せよ。
*実装例*
-- HAVINGによる集計結果を指定して出力。
SELECT
<カラム名1>,
COUNT(<カラム名2>)
FROM
<テーブル名>
GROUP BY
-- グループ化した結果を集計し、2個以上の『フィールド』を取得する。
<カラム名1>
HAVING
COUNT(*) >= 2;
以下の場合、GROUP BY + HAVING や WHERE を使用しても、同じ出力結果になる。
SELECT <カラム名> FROM <テーブル名> GROUP BY <カラム名> HAVING <レコード名>;
SELECT <カラム名> FROM <テーブル名> WHERE <レコード名> GROUP BY <カラム名>;
WILDCARD¶
▼ 使い方¶
*実装例*
SELECT * FROM <テーブル名> WHERE <カラム名> LIKE "%営業";
SELECT * FROM <テーブル名> WHERE <カラム名> LIKE "_営業";
BETWEEN¶
▼ 使い方¶
*実装例*
指定したカラムで、1 以上 10 以下の『フィールド』を取得する。
SELECT * FROM <テーブル名> BETWEEN 1 AND 10;
SET¶
▼ 使い方¶
*実装例*
SET @X = <パラメーター値>;
SELECT * FROM <テーブル名> WHERE @X
OFFSET、LIMIT¶
▼ OFFSET、LIMIT¶
ページングし、レコードを読み込む。
例えば、アプリケーションの UI から受け取ったページ指定を OFFSET(どこから)と LIMIT(どこまで)の値とし、どのレコードからどのレコードまでを取得するかを決める。
SELECT * FROM <テーブル名> LIMIT <数値> OFFSET <数値>;
▼ OFFSET、LIMIT の問題点¶
ページ数が増えると指定する OFFSET 値が大きくなる。
そのため、『どこから』のレコードまで読み込む処理に負荷がかかり、READ 処理の性能が落ちていく。
代替案として、例えばカーソル方式であれば、前回のページングの位置をキャッシュするため、性能がよりよい。
例えばカーソルによるページングであれば、前回のページングの位置をキャッシュするため、性能がよりよい。
サブクエリ¶
▼ 使い方¶
掛け算と同様に、括弧内から先に処理を実行する。
*実装例*
-- Main-query
SELECT * FROM <テーブル名> WHERE <カラム名> != (
-- Sub-query
SELECT max(<カラム名>) FROM <テーブル名>
);
Tips¶
▼ 各DBサイズの確認¶
SELECT
table_schema,
sum(data_length) / 1024 / 1024 AS mb
FROM
information_schema.tables
GROUP BY
table_schema
ORDER BY
sum(data_length + index_length) DESC;
▼ カラムの検索¶
SELECT table_name, column_name FROM information_schema.columns WHERE column_name = <検索したいカラム名> AND table_schema = <検索対象のDB名>
03. EXPLAIN¶
実行計画¶
設定した SELECT が仮に実行された場合、いずれのテーブルのいずれのカラムを取得することになるか (実行計画) を取得する。
また、想定実行時間も検出できるため、スロークエリの検出に役立つ。
EXPLAIN SELECT
*
FROM
t1,
t2
WHERE
t1.c1 = 1
AND t1.c2 = t2.c3
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: t1
type: ref
possible_keys: index_t1_on_c1_and_c2
key: index_t1_on_c1_and_c2
key_len: 5
ref: const
rows: 10
Extra: Using where; Using index
*************************** 2. row ***************************
id: 1
select_type: SIMPLE
table: t2
type: ref
possible_keys: index_t2_on_c3
key: index_t2_on_c3
key_len: 5
ref: sample.t1.c2
rows: 1
Extra: Using index
読み方¶
▼ select_type¶
SQL の種類が表示される。
サブクエリを含まない SQL は SIMPLE となり、サブクエリを含むと、サブクエリの種類に応じて、PRIMARY、SUBQUERY、DEPENDENT SUBQUERY、UNCACHEABLE SUBQUERY、DERIVED、のいずれかが表示される。
▼ table¶
設定した SELECT が使用するテーブル名が表示される。
▼ type¶
設定した SELECT をテーブルに使用するとき、どの程度の数のカラムを検索するのかが表示される。
検索するカラムが多い SQL ほど、想定実行時間が長くなる。
| 種類 | 条件 | 検索するカラム数 | 補足 |
|---|---|---|---|
| ALL | ・DBインデックスを使用していない。 | すべてのカラム | すべてのカラムを検索するため、実行時間がもっとも長く、改善する必要がある。 |
| index | ・DBインデックスを使用していない。 | すべてのインデックスのカラム | |
| range | ・セカンダリーDBインデックスを使用している。 ・ WHERE に重複したレコード値、IN、BETWEEN を使用している。 |
特定の複数カラム | |
| ref | ・セカンダリーDBインデックスを使用している。 ・ WHERE に重複しないレコード値 |
特定の複数カラム | |
| eq_ref | ・クラスタDBインデックスを使用している。 | 1 個のカラム |
1 個のカラムしか fetch しないため、JOIN を使用したアクセスのなかで、実行時間がもっとも短い。 |
| const | ・クラスタDBインデックスを使用している。 ・ JOIN を使用していない。 |
1 個のカラム |
1 個のカラムしか fetch しないため、実行時間がもっとも短い。 |
▼ possible_keys¶
DB インデックスとして設定されたカラムのうちで、実際に利用できるものの一覧が表示される。
05. INSERT¶
バルクインサート¶
一度の INSERT 文で複数の値を挿入する。
INSERT INTO <テーブル名> VALUES ('<カラム名>','<レコード値>'), ('<カラム名>','<レコード値>'), ('<カラム名>','<レコード値>');
06. SHOW¶
TABLES¶
DB を閲覧する。
主に動作確認使用できる。
SHOW TABLES;
+-------------------------------+
| Tables_in_<DB名> |
+-------------------------------+
...
ENGINES¶
MySQL の InnoDB ストレージエンジンを確認する。
\G をつけると、読みやすく整形してくれる。
SHOW ENGINE INNODB STATUS\G;
07. ANALYZE¶
テーブルの統計情報を更新する。
ANALYZE TABLE foos;
+------------+---------+----------+----------+
| Table | Op | Msg_type | Msg_text |
+------------+---------+----------+----------+
| foos | analyze | status | OK |
+------------+---------+----------+----------+
08. EXEC¶
stored procedure¶
▼ stored procedureとは¶
あらかじめ一連の SQL 文を DB に格納しておき、Call 文でコールする方式。
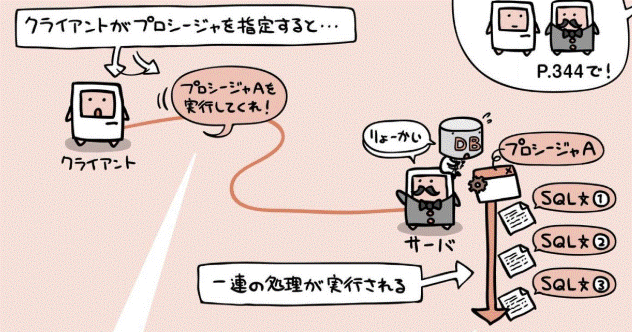
▼ 使い方¶
*実装例*
SELECT 文の stored procedure を作成する例を考える。
-- PROCEDUREを作成し、DBへ格納しておく。
CREATE PROCEDURE SelectContact AS SELECT <カラム名> FROM <テーブル名>
-- PROCEDUREを実行
EXEC SelectContact