信頼性@AWS¶
はじめに¶
本サイトにつきまして、以下をご認識のほど宜しくお願いいたします。
01. 障害の対策¶
インシデント管理¶
インシデント管理ツール (例:PagerDuty、Grafana OnCall、AWS Incident Manager、Slack Apps) を採用し、障害をオンコール担当者に迅速に通知する。
冗長化¶
▼ マルチAZ¶
マルチ AZ を採用する。
それぞれの AZ に Amazon EC2/ECS を冗長化する。
特定の AZ で障害が発生した場合、AWS ALB を起点として、インバウンド通信の向き先を正常な AZ の Amazon EC2/ECS に切り替える。
▼ AWS NAT Gateway¶
AWS NAT Gateway を冗長化する。
AWS NAT Gateway を AZ 別に用意する。これにより、特定の AZ で障害が起こっても、他の AZ のアウトバウンド通信へ影響しないようにする。
▼ Auto Scaling Group¶
Auto Scaling Group を採用する。
Amazon EC2 で障害が発生した場合、AWS ALB を起点にして、正常な Amazon EC2 に切り替える。
▼ Amazon EKS マネージドNodeグループ¶
Amazon EKS マネージド Node グループを採用する。
Amazon EC2 Node で障害が発生した場合、AWS ALB を起点にして、正常な Amazon EC2 に切り替える。
▼ Amazon Aurora¶
Amazon Aurora でフェイルオーバーを採用する。
プライマリーインスタンスで障害が発生した場合、フェイルオーバーにより、リードレプリカがプライマリーインスタンスに昇格します。
スケーリング¶
▼ Amazon EKS マネージドNodeグループ¶
Amazon EC2 Node のスケールアップには、Cluster Autoscaler、Amazon EKS マネージド Node グループを採用する。
Cluster Autoscaler と Amazon EKS マネージド Node グループ、では、Pod による Amazon EC2 Node の負荷に応じて Amazon EC2 Node をスケーリングする。
▼ Auto Scaling Group¶
Amazon EC2 のスケールアップには、Auto Scaling Group を採用する。
Auto Scaling Group では、Amazon EC2 のハードウェアリソース (CPU、メモリ) の消費率に応じて、自動水平スケーリングします。
02. 災害の対策¶
DRリージョン (BCPリージョン) とは¶
『BCP リージョン』ともいう。
メインリージョンで災害が起こった場合に、システムの障害にならないように、災害回復用リージョンを用意しておく。
バックアップリストア構成¶
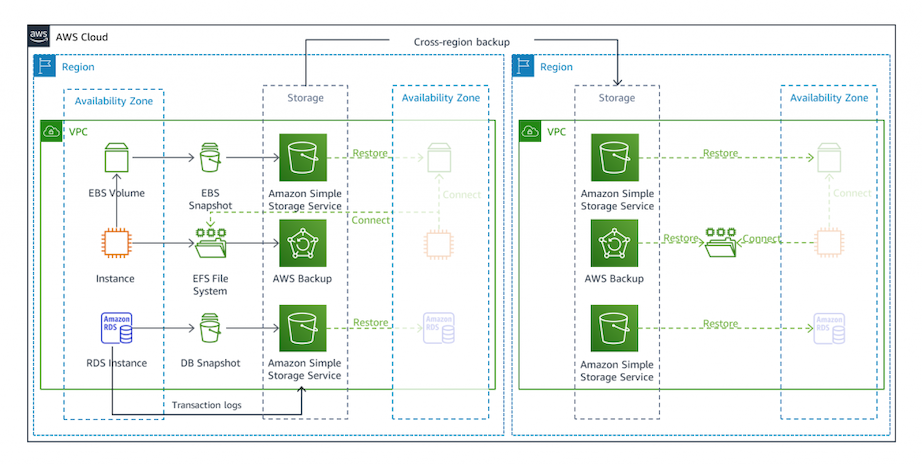
DR リージョンにメインリージョンの AWS リソース (例:EBS ボリューム、RDS) のスナップショットを定期的に作成しておく。
メインリージョンで障害が起こった場合は、スナップショットを使用して、DR リージョンに AWS リソースを復元する。
DR リージョンの準備が完了次第、DR リージョンにリクエストをルーティングできるようにする。
障害が起こってから対応することが多いため、RTO が長くなってしまう。
RPO は最後のバックアップ時点である。
一方で金銭的コストが低い。
パイロットライト構成¶
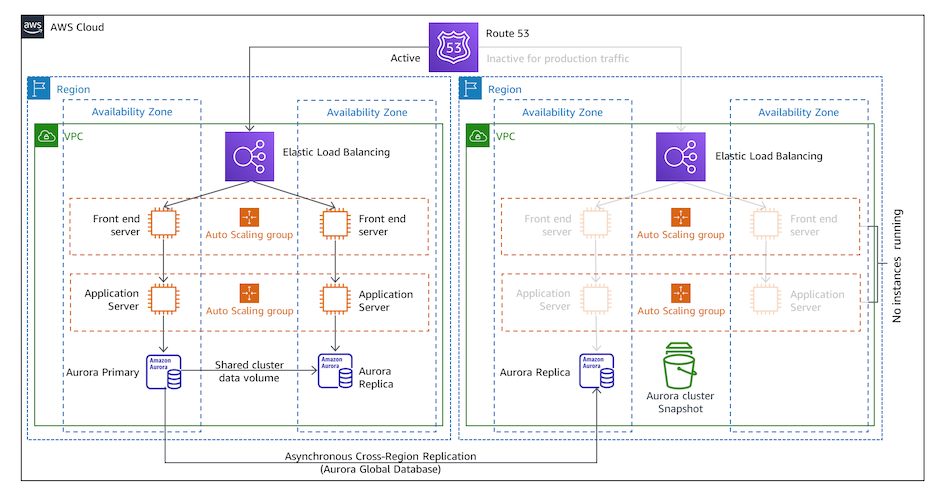
DR リージョンに低スペックな DB を作成しておき、メインリージョンと DR リージョンの DB を定期的に同期しておく。
メインリージョンで障害が起こった場合は、DR リージョンで DB 以外のインフラコンポーネント (例:アプリケーション部分など) を作成し、また DB のスペックをメインリージョンと同等に上げる。
DR リージョンの準備が完了次第、DR リージョンにリクエストをルーティングできるようにする。
障害が起こってから対応することが多いため、RTO がやや長くなってしまう。
RPO は最後の同期時点である。
一方で金銭的コストが低い。
ウォームスタンバイ構成¶
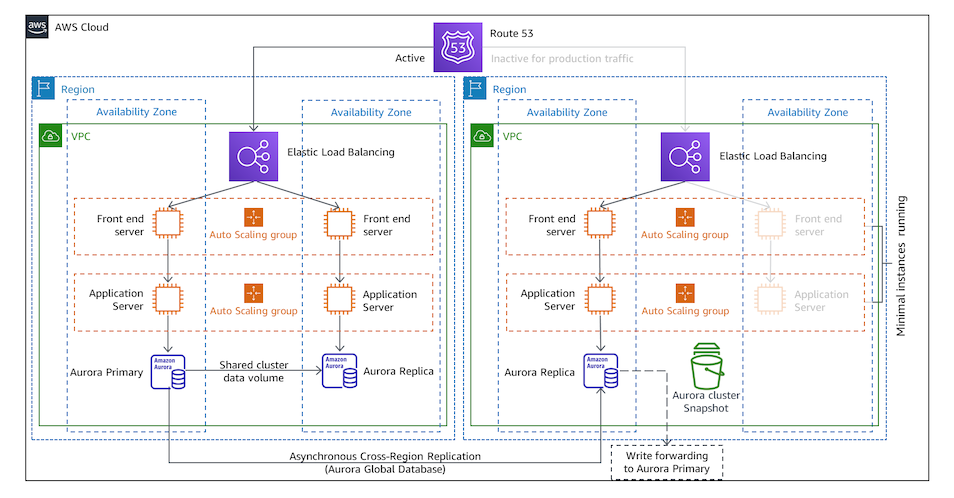
DR リージョンにメインリージョンよりも低スペックなアプリケーションと DB を作成しておき、メインリージョンと DR リージョンの DB を定期的に同期しておく。
メインリージョンで障害が起こった場合は、DR リージョンでアプリケーションと DB のスペックをメインリージョンと同等に上げる。
DR リージョンの準備が完了次第、DR リージョンにリクエストをルーティングできるようにする。
障害が起こった後、スペックを向上させ、またルーティング先を切り替えるのみで回復できるため、RTO が短い。
RPO は最後の同期時点である。
一方で、金銭的コストが高い。
マルチサイトアクティブ構成¶
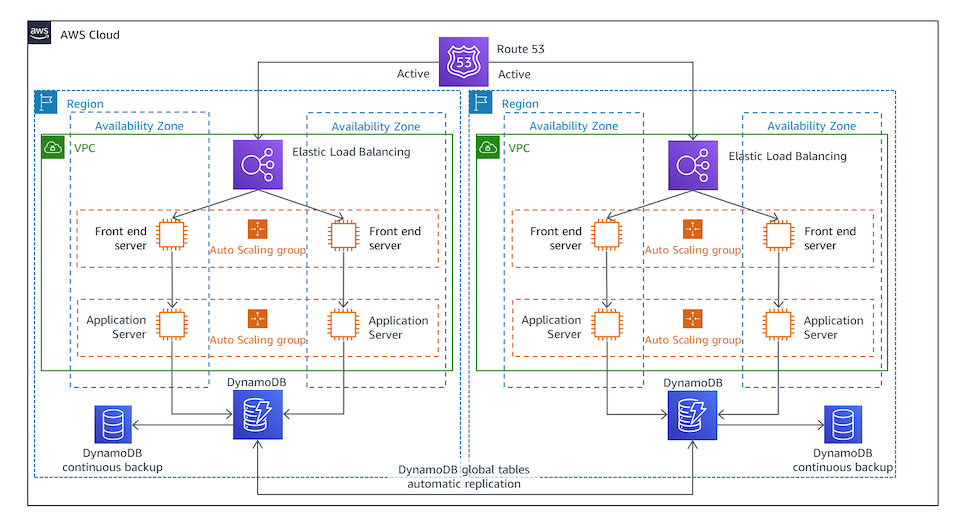
DR リージョンにメインリージョンと同等のアプリケーションと DB を作成しておき、メインリージョンと DR リージョンの DB を定期的に同期しておく。
メインリージョンで障害が起こった場合は、DR リージョンにリクエストをルーティングできるようにする。
障害が起こった後、ルーティング先を切り替えるのみで回復できるため、RTO が短い。
RPO は最後の同期時点である。
一方で、金銭的コストが高い。