Amazon RDS@AWSリソース¶
はじめに¶
本サイトにつきまして、以下をご認識のほど宜しくお願いいたします。
01. Amazon RDSとは¶
記入中...
02. セットアップ (コンソールの場合)¶
2-02. セットアップ (Terraformの場合)¶
# 記入中...
他のDBエンジンの比較¶
▼ DBMSに対応するRDB¶
| DBMS | RDB | 互換性 |
|---|---|---|
| Amazon Aurora MySQL | Amazon RDS | MySQL/PostgreSQL |
| MariaDB | Amazon RDS | MariaDB |
| MySQL | Amazon RDS | MySQL |
| PostgreSQL | Amazon RDS | PostgreSQL |
▼ 機能の違い¶
RDB が Amazon Aurora か Amazon RDS かで機能に差があり、Amazon Aurora のほうが耐障害性や可用性が高い。
ただし、その分費用が高いことに注意する。
OSの隠蔽¶
▼ OSの隠蔽とは¶
Amazon RDS は、EC2 内に DBMS が稼働したものであるが、このほとんどが隠蔽されている。
そのため DB サーバーのようには操作できず、OS のバージョン確認や SSH 公開鍵認証を行えない。
▼ 確認方法¶
Linux x86_64 (AMD64) が使用されているところまでは確認できるが、Linux のバージョンは隠蔽されている。
Amazon Aurora でも確認方法は同じである。
-- Amazon RDSの場合
SHOW VARIABLES LIKE '%version%';
+-------------------------+------------------------------+
| Variable_name | Value |
+-------------------------+------------------------------+
| innodb_version | 5.7.0 |
| protocol_version | 10 |
| slave_type_conversions | |
| tls_version | TLSv1,TLSv1.1,TLSv1.2 |
| version | 5.7.0-log |
| version_comment | Source distribution |
| version_compile_machine | x86_64 |
| version_compile_os | Linux |
+-------------------------+------------------------------+
04. メンテナンスウインドウ¶
メンテナンスウインドウ¶
DB クラスター/DB インスタンスの設定の変更をスケジューリングさせる。
メンテナンスの適切な曜日/時間帯¶
Amazon CloudWatch Metrics の DatabaseConnections メトリクスから、DB の接続数が低くなる時間帯を調査し、その時間帯にメンテナンスウィンドウを設定する。
また、メンテナンスウィンドウの実施曜日が週末であると、サイトが停止したまま休日を迎える可能性があるため、週末以外になるように設定する (メンテナンスウィンドウが UTC であることに注意) 。
『保留中の変更』『保留中のメンテナンス』¶

ユーザーが予定した設定変更は『保留中の変更』として表示される一方で、AWS によって定期的に行われるハードウェア/OS/DB エンジンのバージョンを強制アップグレードは『保留中のメンテナンス』として表示される。
『次のメンテナンスウィンドウ』を選択すれば、実行タイミングをメンテナンスウィンドウ内に設定できる。ただし、これを選択しない場合は『日付の適用』に表示された時間帯で強制実行される。
補足として保留中のメンテナンスは、アクションの『今すぐアップグレード』と『次のウィンドウでアップグレード』からも操作できる。
保留中のメンテナンスの状態¶
| 状態 | 説明 |
|---|---|
| 必須 | アクションは実行可能かつ必須である。実行タイミングは未定であるが、適用期限日には必ず実行され、これは延期できない。 |
| 利用可能 | アクションは実行できるが、推奨である。実行タイミングは未定である。 |
| 次のウィンドウ | アクションの実行タイミングは、次回のメンテナンスウィンドウである。あとでアップグレードを選択することにより、『利用可能』の状態に戻すことも可能。 |
| 進行中 | 現在時刻がメンテナンスウィンドウに含まれており、アクションを実行中である。 |
『次のウィンドウ』状態の取り消し¶
設定の変更が『次のウィンドウ』状態にある場合、画面上からは『必須』や『利用可能』といった実行タイミングが未定の状態に戻せない。
しかし、CLI を使用すると戻せる。
$ aws rds describe-pending-maintenance-actions --output=table
-----------------------------------------------------------------------------------
| DescribePendingMaintenanceActions |
+---------------------------------------------------------------------------------+
|| PendingMaintenanceActions ||
|+---------------------+---------------------------------------------------------+|
|| ResourceIdentifier | arn:aws:rds:ap-northeast-1:<AWSアカウントID>:db:prd-foo-instance ||
|+---------------------+---------------------------------------------------------+|
||| PendingMaintenanceActionDetails |||
||+--------------------------+--------------------------------------------------+||
||| Action | system-update # 予定されたアクション |||
||| AutoAppliedAfterDate | 2022-01-31T00:00:00+00:00 |||
||| CurrentApplyDate | 2022-01-31T00:00:00+00:00 |||
||| Description | New Operating System update is available |||
||| ForcedApplyDate | 2022-03-30T00:00:00+00:00 |||
||+--------------------------+--------------------------------------------------+||
|| PendingMaintenanceActions ||
|+---------------------+---------------------------------------------------------+|
|| ResourceIdentifier | arn:aws:rds:ap-northeast-1:<AWSアカウントID>:db:prd-bar-instance ||
|+---------------------+---------------------------------------------------------+|
||| PendingMaintenanceActionDetails |||
||+--------------------------+--------------------------------------------------+||
||| Action | system-update |||
||| AutoAppliedAfterDate | 2022-01-31T00:00:00+00:00 |||
||| CurrentApplyDate | 2022-01-31T00:00:00+00:00 |||
||| Description | New Operating System update is available |||
||| ForcedApplyDate | 2022-03-30T00:00:00+00:00 |||
||+--------------------------+--------------------------------------------------+||
$ aws rds apply-pending-maintenance-action \
--resource-identifier arn:aws:rds:ap-northeast-1:<AWSアカウントID>:db:prd-foo-instance \
--opt-in-type undo-opt-in \
--apply-action <取り消したいアクション名>
『保留中の変更』の取り消し¶
保留中の変更を画面上からは取り消せない。
しかし、CLI を使用すると戻せる。
$ aws rds modify-db-instance \
--db-instance-identifier prd-foo-instance \
<変更前の設定項目> <変更前の設定値> \
--apply-immediately
05. ダウンタイム¶
ダウンタイムの発生条件¶
| 変更する項目 | ダウンタイムの有無 | 補足 |
|---|---|---|
| インスタンスクラス | あり | ・2 個のインスタンスで同時にインスタンスクラスを変更すると、次のようなイベントを確認できる。インスタンスが複数回再起動することからわかるとおり、長いダウンタイム (約 6~8 分) が発生する。そのため、フェイルオーバーを利用したダウンタイムの最小化を行う。・https://dev.classmethod.jp/articles/rds-scaleup-instancetype/ ・プライマリーインスタンスのイベント 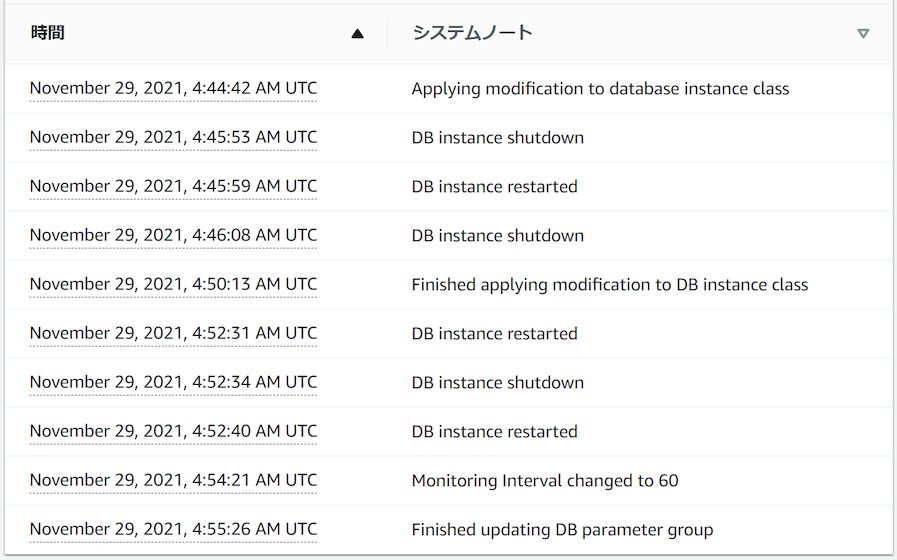 ・リードレプリカのイベント 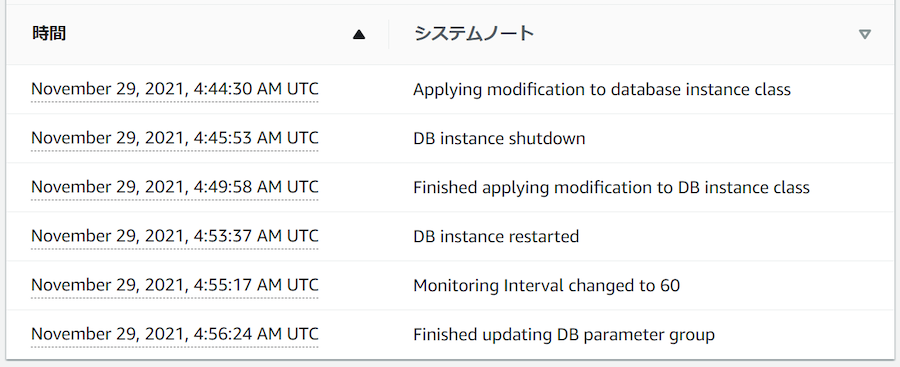 |
| サブネットグループ | あり | |
| メンテナンスウィンドウ | 条件付きでなし | ダウンタイムが発生する操作が保留中になっている状態で、メンテナンス時間を現在が含まれるように変更すると、保留中の操作がすぐに適用される。そのため、ダウンタイムが発生する。 |
| パフォーマンスインサイト | 条件付きでなし | パフォーマンスインサイトの有効化ではダウンタイムが発生しない。ただし、有効化のためにパラメーターグループの performance_schema を有効化する必要がある。パラメーターグループの変更をDBインスタンスに反映させるうえで再起動が必要なため、ここでダウンタイムが発生する。 |
| バックアップウインドウ | 条件付きでなし | 0 から 0 以外の値、0 以外の値から 0 に変更した場合、ダウンタイムが発生する。 |
| パラメーターグループ | なし | パラメーターグループ自体の変更ではダウンタイムは発生しない。また、静的パラメーターはパラメーターグループの変更に合わせて適用される。ただし、動的パラメーターを変更した場合は、これをDBインスタンスに反映させるために再起動が必要であり、ここでダウンタイムが発生する。 https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/USER_WorkingWithParamGroups.html |
| セキュリティグループ | なし | |
| マイナーバージョン自動アップグレード | なし | エンジンバージョンの変更にはダウンタイムが発生するが、自動アップグレードの設定にはダウンタイムが発生しない。 |
| ストレージのAutoScaling | なし |
06. フェイルオーバー¶
Amazon RDSのフェイルオーバーとは¶
スタンバイレプリカがプライマリーインスタンスに昇格する。
フェイルオーバーによるダウンタイムの最小化¶
DB インスタンスがマルチ AZ 構成の場合、以下の手順を使用してダウンタイムを最小化できる。
(1)-
アプリケーションの接続先をプライマリーインスタンスにする。
(2)-
特定の条件下のみで、フェイルオーバーが自動的に実行される。
(3) Amazon RDS の Amazon RDS では条件に当てはまらない場合、リードレプリカを手動でフェイルオーバーさせる。
(4) フェイルオーバー時に約 1~2 分のダウンタイムが発生する。
フェイルオーバーを使用しない場合、DB インスタンスの再起動でダウンタイムが発生するが、これよりは時間が短いため、相対的にダウンタイムを短縮できる。
07. イベント¶
コンソール画面ではイベントが英語で表示されているため、リファレンスも英語でイベントを探したほうがよい。
08. Amazon RDSプロキシ¶
Amazon RDSプロキシとは¶
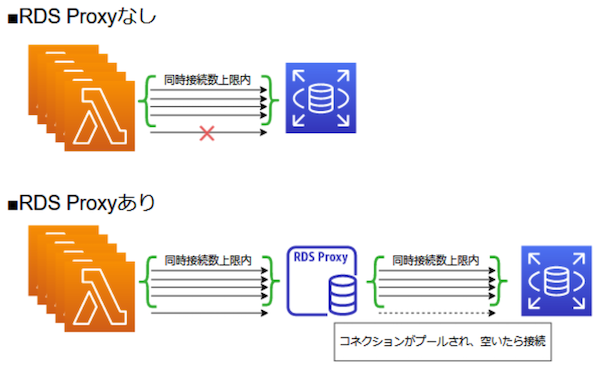
クラウド DB プロキシとして働く。
接続プールの管理¶
アプリから Amazon RDS にクエリが送信されたとき、接続を新しく作成せずに、接続プール内の非アクティブな接続を再利用し、Amazon RDS にフォワーディングする。
アプリから DB のインスタンスに直接的にクエリを送信する場合、アプリケーションは Amazon RDS の同時接続の上限数 (インスタンスタイプで決まる) を考慮しない。
そのため、接続数が多くなりやすいアプリ (例:AWS Lambda、マルチスレッド) を使用していると、アプリケーションが無制限に接続を新しく作成することになる。
その結果、アプリケーションの接続が Amazon RDS の同時接続の上限数を超えて接続してしまい、Amazon RDS がエラーを返却してしまう。
Amazon RDS プロキシは、Amazon RDS の同時接続の上限数を考慮しつつ、接続プールから非アクティブな接続を再利用するため、アプリケーションが Amazon RDS の同時接続の上限数を超えて接続することがない。
ユースケース¶
▼ AWS LambdaのデータベースにAmazon RDSを使用する場合¶
リクエスト駆動型アプリケーションの場合、複数のリクエストに対して単一の DB 接続を再利用できる。
一方で、イベント駆動型アプリケーションの場合、単一リクエストに対して単一の DB 接続を使用する。
Amazon RDS には DB 接続の上限数があり、前段に Amazon RDS プロキシーがないとすぐに上限数に達してしまう。