RDBMS@DB系ミドルウェア¶
はじめに¶
本サイトにつきまして、以下をご認識のほど宜しくお願いいたします。
01. RDBMS (関係DB管理システム) の仕組み¶
RDBMSの種類¶
| RDBMS | RDB |
|---|---|
| MariaDB | MariaDBのDB |
| MySQL | MySQLのDB |
| PostgreSQL | PostgreSQLのDB |
アーキテクチャ¶
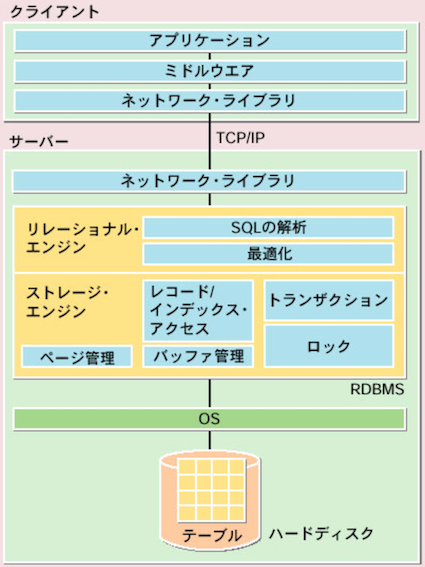
RDBMS は、リレーショナルエンジン、DB エンジン (ストレージエンジン) 、から構成される。
02. RDBMS¶
リレーショナルエンジン¶
記入中...
DBエンジン (ストレージエンジン)¶
▼ DBエンジンとは¶
『ストレージエンジン』ともいう。
RDBMS が DB に対してデータの CRUD の処理を行うために必要なソフトウェアのこと。
▼ DBエンジンの種類¶
RDMS (例:MySQL、PostgreSQL など) によって、対応する DB エンジンが異なる。
- InnoDB
- Memory
- CSV
RDB (関係DB)¶
▼ RDBとは¶
データ同士がテーブル状に関係を持つデータ格納形式で構成されるのこと。
NoSQL とは異なり、データはストレージに保管する。
▼ DBスキーマ¶
DB を論理的に分割する名前空間のこと。
名前空間内には、テーブル、インデックス、ビュー、ストアドプロシージャなどが所属する。
MySQL には B スキーマがなく、DB そのものが DB スキーマに相当する。
▼ DBテーブル¶
行列からなるデータのセットのこと。
▼ DBカラム¶
テーブルの列データのこと。
▼ DBレコード¶
テーブルの行データのこと。
オンディスクDB¶
RDB は、ストレージにデータを保存する。
ストレージ (例:HDD、SSD) 上にデータを保管する DB を、メモリ上に保管することと比較して、オンディスク DB という。
DBパーティション¶
▼ DBパーティションとは¶
DB のテーブルを分割して管理する。
性能の向上のために、DB パーティションを作成する。
分割しても、DBMS クライアントからは単一のテーブルとして扱える。
▼ 水平パーティション (シャーディング)¶
『シャーディング』ともいう。
テーブルをレコード方向に分割して管理する。
▼ 垂直パーティンション¶
テーブルをカラム方向に分割して管理する
DBインデックス¶
▼ DBインデックスとは¶
テーブルから特定のカラムのみを抜き出し、検索しやすいように並び替え、名前を付けて保管しておいたもの。
性能の向上のために、DB インデックを作成しておく。
DB インデックスとして保管したカラムから特定のレコードを直接的に取得できる。
そのため、SQL の実行時間がカラム数に依存しなくなる。
DB インデックスを使用しない場合、SQL の実行時にすべてカラムを取得するため、実行時間がテーブルのカラム数に依存してしまう。
▼ クラスターDBインデックス(自動作成)¶
プライマリーキーあるいはユニークキーのカラムを基準にして、テーブルのカラムを並び替えた DB インデックスのこと。
DB エンジンが自動で作成してくれる。
CREATE INDEX foo_index
ON foo_table (id)
▼ セカンダリーDBインデックス(手動作成が必要)¶
プライマリーキーあるいはユニークキーではないカラムを基準にして、テーブルのカラムを並び替えた DB インデックスのこと。
CREATE INDEX foo_index
ON foo_table (foo_column)
▼ 複合DBインデックス¶
複数のカラムを基準にして、テーブルを並び替えた DB インデックスのこと。
対象としたカラムごとに異なる値のレコード数が計測され、この数が少ない (一意の値の多い) カラムが検出される。
そして、カラムのレコードの昇順で並び替えられ、DB インデックスとして保管される。
CREATE INDEX foo_index
ON foo_table (foo_column, bar_column, ...)
*例*
以下のような foo テーブルがあり、name カラムと address カラムを基準に並び替えた foo_index という複合 DB インデックス名を作成する。
CREATE INDEX foo_index
ON foo_table (name, address)
| id | name | address | old |
|---|---|---|---|
| 1 | Suzuki | Tokyo | 24 |
| 2 | Yamada | Osaka | 18 |
| 3 | Takahashi | Nagoya | 18 |
| 4 | Honda | Tokyo | 16 |
| 5 | Endou | Tokyo | 24 |
各カラムで値の異なるレコード数が計測され、name カラムは address カラムよりも一意のレコードが多いため、name カラムの昇順 (アルファベット順) に並び替えられ、DB インデックスとして保管される。
| id | name | address | old |
|---|---|---|---|
| 5 | Endou | Tokyo | 24 |
| 4 | Honda | Tokyo | 18 |
| 1 | Suzuki | Tokyo | 24 |
| 3 | Takahashi | Nagoya | 18 |
| 2 | Yamada | Osaka | 18 |
▼ DBインデックスのカラム変更¶
DB インデックスのカラム変更によって、DB インデックスの削除と追加が起こる。
次のように DB インデックスの追加と削除を別にすれば、負荷を少しでも抑えられる。
実行例
これは SQL を使用した例である。
- 新しい DB インデックスを追加するリリース <--- ここで中程度の負荷
CREATE INDEX idx_user_org_name_updated ON User (organization_id, user_name, updated_at DESC, status);
CREATE INDEX idx_user_updated_org ON User (updated_at DESC, organization_id, status);
-
一日くらい新旧の DB インデックスを共存させる
-
古い DB インデックスを削除するリリース <--- ここで小程度の負荷
DROP INDEX idx_user_org_name_created ON User;
DROP INDEX idx_user_created_org ON User;
実行例
これは ORM を使用した例である。
ORM を使用する場合、より簡単にカラムを変更できる。
model User {
user_id String @id @default(cuid()) @db.VarChar(127)
organization_id String @db.VarChar(127)
user_name String @db.VarChar(127)
email String @db.VarChar(255)
status String @db.VarChar(31)
created_at DateTime @default(now()) @db.DateTime(3)
updated_at DateTime @updatedAt @db.DateTime(3)
// 古いインデックス(created_atを使用) <--- 共存させた後に削除する
@@index([organization_id, user_name, created_at(sort: Desc), status])
@@index([created_at(sort: Desc), organization_id, status])
// 新しいインデックス(updated_atを使用)
@@index([organization_id, user_name, updated_at(sort: Desc), status])
@@index([updated_at(sort: Desc), organization_id, status])
}
04. RDBMSクライアント¶
クエリ¶
▼ クエリとは¶
RDBMS の種類に応じたクエリが必要になる。
▼ クエリパッケージ¶
クエリの実装の抽象度に応じて、パッケージがある。
| クエリパッケージ | 説明 |
|---|---|
| 生のクエリ | RDB固有のクエリのこと。 |
| クエリビルダー | RDB固有のクエリを実装しやすくしたパッケージのこと。 |
| ORM | アプリケーション側にテーブルに対応したモデルを定義し、これを使用してRDBに固有のクエリを送信するパッケージのこと。 |
DB接続¶
▼ DB接続とは¶
アプリから RDBMS へのクエリ送信時の通信のこと。
TCP/IP プロトコルを使用する。
▼ DBセッション¶
ログインに成功した DB 接続のこと。
セッションを確立できると、クエリを送信できるようになる。
1 つのセッション中では、1 つのトランザクション (複数のクエリからなる) を実行する。
▼ 接続プロキシ¶
アプリケーションと DB の間に、接続プールプロキシ (例:ProxySQL、PgBouncer など) を配置する。
これにより、アプリケーションサーバーの接続プールの処理を接続プロキシに委譲する。
注意点として、プリペアードステートメントでは既存の接続を再利用する必要があるが、接続プロキシでは別の接続を使用してしまうことがある。
そのため、接続プロキシの採用時には、プリペアードステートメントを使用できない。
▼ 接続プール¶
アプリから DB へのクエリ送信時に新しく作成した接続を、非アクティブ状態として保持しておき、以降のクエリ送信時に再利用する。
一定回数再利用されたり、一定期間使用されていない接続は削除される。
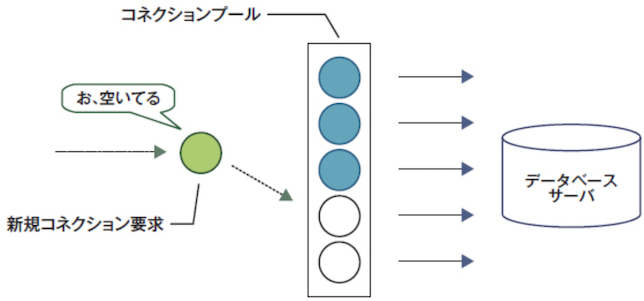
▼ 接続プールに対する待機キュー¶
もし接続プール上の接続がすべて使用されてしまった場合、いずれかの接続が解放されるまで待機する必要がある。
このときに、送信されたリクエストは待機キューで解放を待つ。