システムテスト@ブラックボックステスト¶
01. システムテスト (総合テスト)¶
システムテストとは¶
『総合テスト』ともいう。
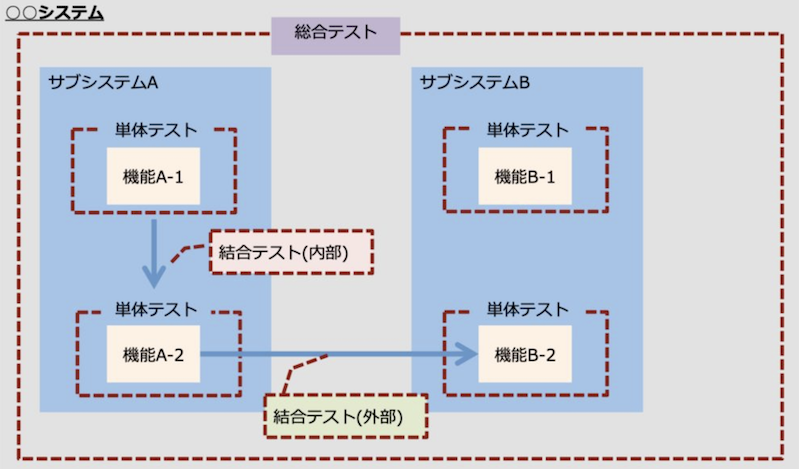
既存機能/追加/変更を含むすべてのコンポーネントを組み合わせ、すべてのコンポーネント間の連携が正しく動作しているかを検証する。
システムテストの種類¶
▼ 機能テスト¶
システムが機能的な品質を満たしているかを検証する。
| テストの種類 | 検証内容 |
|---|---|
| 正常系 (成功で終わる操作) | 操作の種類 (登録、参照、更新、削除) 、画面遷移、ステートマシン、セキュリティなど |
| 異常系 (エラーで終わる操作) | 操作の種類 (登録、参照、更新、削除) など |
| 組み合わせ | 同時操作、割り込み操作、排他制御に関わる操作など |
| 業務シナリオ | シナリオに沿ったユーザーによる一連の操作 |
| 開発者シナリオ | シナリオに沿った開発者による一連の操作 (例:手動コマンドなど) |
| 外部ソフトウェア連携 | 外部のAPIとの連携処理に関わる操作 |
▼ 非機能テスト¶
システムが非機能的な品質を満たしているかを検証する。
| テストの種類 | 各非機能的な品質との対応関係 |
|---|---|
| ストレステスト | 耐久性 |
| ロードテスト | 耐久性 |
| 可用性テスト | 可用性 |
| 耐障害性テスト | 耐障害性 |
| Testing in production | 耐久性 |
| ペネトレーションテスト | 安全性 |
テスト結果の可視化¶
▼ テストレポート¶
ツールによっては、テスト結果からテストレポートを作成してくれる。
▼ バグ管理図¶
プロジェクトのとき、残存テスト数と不良摘出数 (バグ発見数) を縦軸にとり、時間を横軸にとることにより、バグ管理図を作成する。
それぞれの曲線の状態から、プロジェクトの進捗状況を読み取られる。
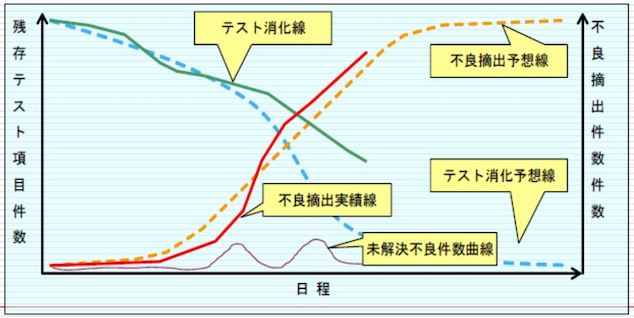
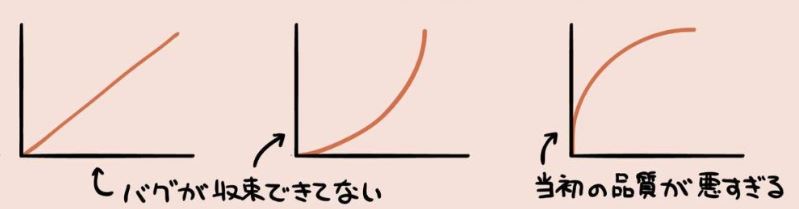
不良摘出実績線 (信頼度成長曲線) は、プログラムの品質の状態を表し、S 字型でないものはプログラムの品質がよくないことを表す。
02. 機能テスト¶
機能テストとは¶
機能的な品質を満たせているかを検証する。
ホワイトボックスでの機能テストとは意味合いが異なるので注意する。
テストケース¶
ユーザー操作の前提や検証内容をまとめたドキュメントのこと。
| 前提条件 | 操作の種類 | 検証方法 | 期待値 | OK/NG |
|---|---|---|---|---|
| ... | 参照 | ... | ... | ... |
| ... | 作成 | ... | ... | ... |
| ... | 更新 | ... | ... | ... |
| ... | 削除 | ... | ... | ... |
03. 性能テスト¶
性能テストとは¶
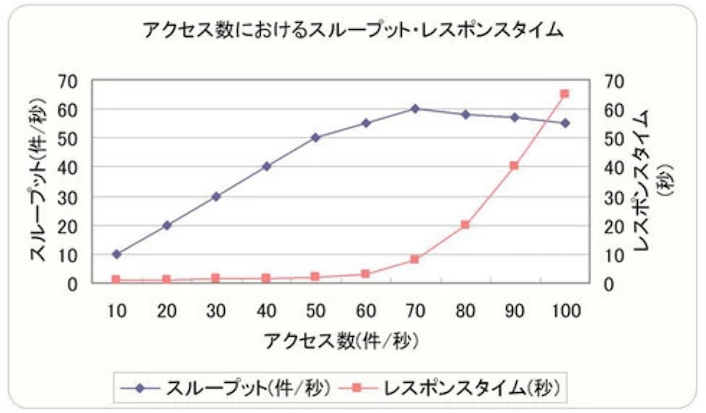
一定時間内に、ユーザーが一連のリクエスト (例:ログイン、参照、登録、ログアウト) を行ったとき、あらかじめ定めた指標にどのような変化があるかを検証する。
具体的にはテスト時、アクセス数を段階的に増加させて、テストレポートとしてグラフ化する。
テストレポートを元に、想定されるリクエスト数が現在の性能にどの程度の負荷をかけるのかを確認し、加えて最大負荷の場合でも性能目標を満たしているかを確認する。
これらを運用時の監視の参考値にする。
性能テストの種類¶
- ストレステスト
- ロードテスト
- 耐久テスト
- スパイクテスト
- 拡張性テスト
性能指標¶
- 平均スループット
- 平均レスポンスタイム
- 平均ハードウェア使用率
- 時間当たり平均トランザクション数 (TPS:Transaction Per Second)
機能別の性能目標値¶
KPI (組織内の合意) に基づいて、各機能ごとに性能指標の目標値を決める。
SLA (顧客との合意) に基づいた SLO とは区別したい。
例えば、1 秒間に 50 人のユーザーからリクエスト (50 個/秒のリクエスト) があり、このときのとある機能でレスポンスタイム目標値は 3 秒以内であるとする。
この場合、平均スループットの目標値は 50 (個/秒) 、平均レスポンスタイムの目標値は 3 秒以内、となる。
| 項目 | 平均スループット目標値 (件/秒以上) | 平均レスポンス目標値 (秒以内) | ハードウェア使用率目標値 (最大率) |
|---|---|---|---|
| 機能A | 50 |
3 |
60% |
| 機能B | ... | ... | ... |
| 機能C | ... | ... | ... |
- https://gihyo.jp/dev/serial/01/tech_station/0008
- https://qiita.com/s9910553/items/ca3dae561489844da646
- https://engineering.dena.com/blog/2021/10/healthcare-load-testing/#%E8%B2%A0%E8%8D%B7%E3%83%86%E3%82%B9%E3%83%88%E3%81%AE%E7%9B%AE%E6%A8%99%E5%80%A4%E8%A8%AD%E5%AE%9A
- https://xtech.nikkei.com/it/article/COLUMN/20101101/353654/
ユースケース¶
オートスケーリングがある場合とない場合で、ネットワークの性能指標 (スループット、レスポンスタイムなど) にどの程度の違いがあるかを確認する。
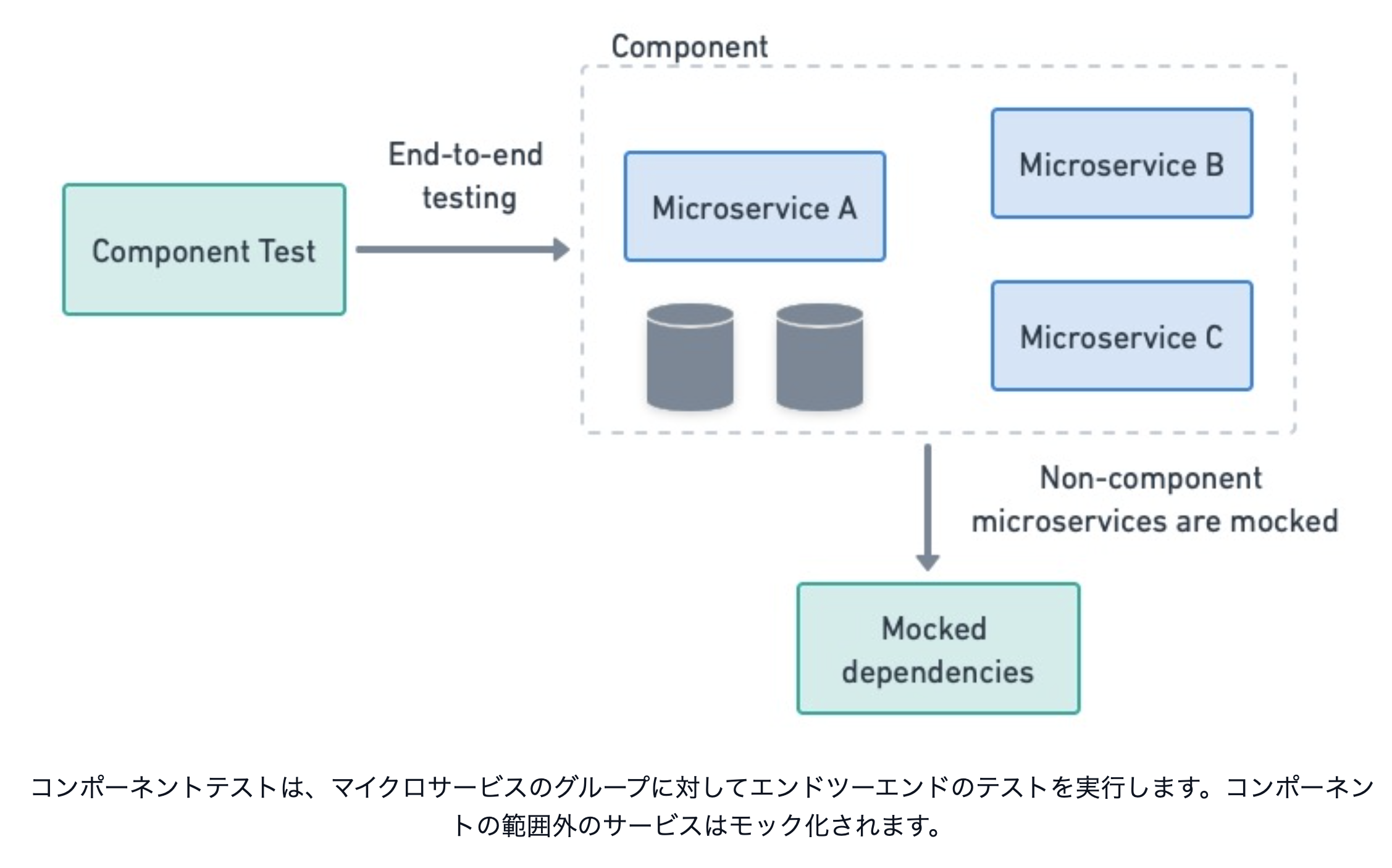
外部APIのモックサーバー¶
システムが外部 API と接続する場合、外部 API に影響を与えないようにモックサーバーを用意する。
ブラックボックステスト時は、外部 API へのドメインをモックサーバーのドメインに切り替える。
マイクロサービスアーキテクチャの場合、モックマイクロサービスを用意する。
03-02. ロードテスト (負荷テスト)¶
ロードテストとは¶
実地を再現した (許容の限界値を含む) 負荷をシステムに与えたとき、どのように動作するかを確認する。
許容以上の負荷を与えるストレステストとは区別すること。
ユースケース¶
▼ 例¶
実地的な負荷状況で、オートスケーリングが品質を満たしているか (有効に機能するか) を確認する。
▼ 例¶
性能の限界値に達するほどのリクエスト数が送信されたとき、障害回避処理 (例:アクセスが込み合っている旨のページを表示) が実行されるかを検証する。
具体的にはテスト時、障害回避処理以外の動作 (エラー、間違った処理、障害回復後にも回復できない、システムダウン) が起こらないか否かを確認する。
設計規約¶
▼ ロードテストツール¶
- Jenkins
- Grafana k6 (JavaScript でシナリオ定義できる)
- Gatling (Scala でシナリオ定義できる)
- Taurus (他のロードテストツールのラッパー)
▼ 事前作業¶
- トラフィックピークに相当するリクエスト数を見積もる
- 土日
- お盆
- ゴールデンウィーク
- 年末年始
- ロードテスト前にアラートを無効化して
- 実行環境を占有させてもらうことになるため、関係者と実施日を調整する。
▼ 実行環境¶
ロードテストの実行環境の性能が低いと、リクエストの送信速度が落ちてしまう。
そのため、ローカル PC などではなく、専用のサーバーなどで実行したほうがよい。
▼ シナリオの種類¶
- 一定数のリクエストを数分間送信し続ける。
- 送信するリクエスト数を増加 (直線的、指数関数的など) させていく。
- 最初は一定数のリクエストを送信し、途中からリクエスト数を増加させていく。
▼ テストレポートによる評価¶
該当機能のエンドポイントにおいて、レスポンスの 95%が SLO の目標値を満たすことを確認する。
| 機能のエンドポイント | 区分 | トランザクション回数/秒間 | SLOの目標値 |
|---|---|---|---|
/api/v1/foo |
平常時 (トラフィックピークでない) | 10 tps |
10 tps の負荷時に、99 パーセンタイルが 1 秒以内に完了する |
/api/v1/bar |
平常時 (トラフィックピークでない) | 20 tps |
20 tps の負荷時時に、99 パーセンタイルが 1 秒以内に完了する |
/api/v1/baz |
平常時 (トラフィックピークでない) | 15 tps |
15 tps の負荷時時に、99 パーセンタイルが 1 秒以内に完了する |
/api/v1/qux |
性能上限相当の負荷 | 20 tps |
20 tps の負荷時時に、99 パーセンタイルが 1 秒以内に完了する |
ロードテストのテストケース¶
▼ 背景¶
アプリで、開始からピークまでに次のようにリクエスト数が増し、障害が発生した。
今回、障害に耐えられるようにスペックを向上させた。
障害時のデータに基づいてロードテストを実施し、障害時と同じ負荷に十分耐えられるかどうかを検証する。
| 障害発生期間 | 合計閲覧ページ数(PV数/min) |
平均ユーザー数(UA数/min) |
ユーザー当たり閲覧ページ数(PV数/UA数) |
|---|---|---|---|
13:00 ~13:05 (開始) |
300 |
100 |
3 |
13:05 ~13:10 |
600 |
200 |
3 |
13:10 ~13:15 (ピーク) |
900 |
300 |
3 |
| ランキング | URL | 割合 |
|---|---|---|
| 1 | /aaa/bbb/* |
40% |
| 2 | /ccc/ddd/* |
30% |
| 3 | /eee/fff/* |
20% |
| 4 | /ggg/hhh/* |
10% |
▼ テストケース¶
ユーザー当たりの閲覧ページ数はループ数に置き換わるため、ループ数は『3 回』になる。
障害発生期間の閲覧ページ数はスレッド数に置き換わるため、スレッド数は『1800 個 (300 + 600 + 900) 』になる。
障害発生期間は、ランプアップに置き換わるため、ランプアップ期間は『900 秒 (15 分間) 』になる。
| スレッド数 (個) | ループ数 (回) | ランプアップ期間 (秒) |
|---|---|---|
1800 |
3 |
900 |
03-03. ストレステスト (限界テスト)¶
ストレステスト¶
許容以上の負荷をシステムに与えたとき、どのように動作するかを確認する。
また、テストレポートから次の範囲を導く必要がある。
- 安全範囲 (青信号)
- 危険範囲 (黄色信号)
- 限界値 (赤信号)
これらは、運用時の監視で参考にする。
実地を再現した (許容の限界値を含む) 負荷を与えるロードテストとは区別すること。
設計規約¶
▼ ストレステストツール¶
- Jenkins
- Grafana k6 (JavaScript でシナリオ定義できる)
- Gatling (Scala でシナリオ定義できる)
- Taurus (他のロードテストツールのラッパー)
▼ 事前作業¶
- ストレステスト前にアラートを無効化しておく。
- 実行環境を占有させてもらうことになるため、関係者と実施日を調整する。
▼ シナリオの種類¶
- 一定数のリクエストを送信し続ける。
- 送信するリクエスト数を増加 (直線的、指数関数的など) させていく。
- 最初は一定数のリクエストを送信し、途中からリクエスト数を増加させていく。
▼ テストレポートによる評価¶
%を判断基準に使用する。レスポンスの95%が、ネットワークの性能指標 (スループット、レスポンスタイムなど) で一定水準以下の値であることを確認する。
03-03. 耐久テスト¶
耐久テストとは¶
長時間の大量リクエストが送信されたとき、短時間では検出できないどのような問題が存在するかを検証する。
具体的にはテスト時、長時間の大量リクエストを処理させ、問題 (例:メモリリークによってメモリを圧迫、セッションデータが蓄積してメモリやストレージを圧迫、ログが蓄積してストレージを圧迫、ヒープやトランザクションログが CPU や I/O 処理を圧迫) を発生させる。
これにより、どんな問題が起こるか否かを確認する。
04. 可用性テスト¶
可用性テストとは¶
システムで意図的に障害を起こし、そのときに可用性の仕組みが正しく発動し、非機能的な品質を満たしているかを検証する。
目標値の指標¶
▼ RPO (目標回復時点)¶
障害が発生したとき、どの時点まで遡ってデータを回復させるかの目標値のこと。
もし RPO が 5 分間だとすると、5 分間のデータ欠損は回復できず、これを許容することになる。
▼ RTO (目標回復時間)¶
障害が発生したとき、障害後どの時間以内にデータを回復させるかの目標値のこと。
言い換えると、ダウンタイムの最大許容時間である。
もし RTO が 1 時間だとすると、1 時間は障害が起こったまま (ダウンタイム) になり、これを許容することになる。
可用性テストのテストケース¶
▼ 背景¶
今回、Kubernetes の Node 上で、Kubernetes リソースとアプリケーションが稼働するシステムを開発した。
可用性テストを実施し、障害が起こっても利用可能な時間を確保できるかどうかを検証する。
| 項目 | 技術 |
|---|---|
| 仮想サーバー | Amazon EC2 (オートスケーリングあり) |
| アプリ | Go |
| リバースプロキシ | Nginx |
| コンテナオーケストレーション | Kubernetes |
| サービスメッシュ | Istio |
| メトリクスの監視バックエンド | Prometheus |
| ログの収集 | Fluentd |
| 分散トレースの監視フロントエンド | Jaeger |
| メッシュトポロジーの監視フロントエンド | Kiali |
▼ テストケース¶
各テストケースで、カオスエンジニアリングやフォールトインジェクションを実施する。
障害発生時にシステムが高い可用性を発揮できるかを確認する。
| 障害名 | フォールトインジェクション | 検証方法 | 検証方法のコマンド | 期待動作 |
|---|---|---|---|---|
| Nodeの停止障害 | Amazon EC2を停止させる。 | Node内でroot権限でカーネルパニックを意図的に起こし、その状態でもシステム全体として稼働し続けられるか否かを確認する。 | ・aws ec2 stop-instances --instance-ids <インスタンスID>・ echo 1 > /proc/sys/kernel/sysrq && echo c > /proc/sysrq-trigger |
・冗長化された稼働中のNode上で、レプリカ数を維持できるだけのPodが起動する。 ・オートスケーリングによって、停止したNodeに代わり新しいNodeが起動する。 ・Nodeのヘルスチェックが正常である。 |
| Podの停止障害 | GoのPodを停止させる。 | kubectl コマンドでPodを強制的に終了し、その状態でもシステム全体として稼働し続けられるか否かを確認する。 |
・kubectl delete pod <Pod名> --grace-period=0 --force |
・オートスケーリングによって、停止したPodに代わり新しいPodが起動する。 ・アプリケーションが正しく動作している。 |
| NginxのPodを停止させる。 | 同上 | 同上 | ・オートスケーリングによって、停止したPodに代わり新しいPodが起動する。 ・アプリケーションが正しく動作している。 |
|
| kube-state-metricsのPodを停止させる。 | 同上 | 同上 | ・オートスケーリングによって、停止したPodに代わり新しいPodが起動する。 ・データをすべて収集できている。 |
|
| PrometheusのPodを停止させる。 | 同上 | 同上 | ・オートスケーリングによって、停止したPodに代わり新しいPodが起動する。 ・データをすべて収集できている。 |
|
| FluentdのPodを停止させる。 | 同上 | 同上 | ・オートスケーリングによって、停止したPodに代わり新しいPodが起動する。 ・ログをまさしくルーティングできている。 |
|
| GrafanaのPodを停止させる。 | 同上 | 同上 | ・オートスケーリングによって、停止したPodに代わり新しいPodが起動する。 ・ダッシュボードにログインできる。 ・データをまさしく可視化できている。 |
|
| AlertmanagerのPodを停止させる。 | 同上 | 同上 | ・オートスケーリングによって、停止したPodに代わり新しいPodが起動する。 ・ダッシュボードにログインできる。 ・アラートをまさしくルーティングできている。 |
|
| KialiのPodを停止させる。 | 同上 | 同上 | ・オートスケーリングによって、停止したPodに代わり新しいPodが起動する。 ・ダッシュボードにログインできる。 ・アラートをまさしくルーティングできている。 |
|
| JaegerのPodを停止させる。 | 同上 | 同上 | ・オートスケーリングによって、停止したPodに代わり新しいPodが起動する。 ・ダッシュボードにログインできる。 ・アラートをまさしくルーティングできている。 |
|
| Istioでフォールトインジェクションを実施する。 | Istioの機能を使用する。 | 可用性テストのときだけ、マニフェストにフォールトインジェクションの設定を追加する。 | ・オートスケーリングによって、停止したPodに代わり新しいPodが起動する。 ・ダッシュボードにログインできる。 ・アラートをまさしくルーティングできている。 |
05. 耐障害性テスト¶
Fault tolerance (耐障害性)¶
耐障害性テストとは¶
システムで意図的に障害を起こし、そのときの耐障害性が非機能的な品質を満たしているかを検証する。
06. Testing in production¶
Testing in productionとは¶
本番環境にて実際のユーザーの手を借り、非機能的な品質を実地的に検証する (例:該当のエラーメトリクスが基準値を満たすか) 。
- カナリアリリース中のテスト
- カオスエンジニアリング
カオスエンジニアリング¶
▼ カオスエンジニアリングとは¶
実験的に、本番環境のマイクロサービスアーキテクチャなシステムにランダムな『カオス』を意図的に注入し、高負荷な状態に至らせる。
そのテストレポートから、システムに潜む想定外の問題を表面化させる。
カオスエンジニアリングは、実地的なテストであり (例:該当のエラーメトリクスが基準値を満たすか) 、今まさに実際のユーザーが使用しているソフトウェアに対して実施することになるため、ビジネスサイドの理解が必要になる。
ただし、必ずしも本番環境でしか使用できるわけではない。
テスト環境で実施し、起こりうる障害を洗い出すように使用してもよい。
対象となるシステムは、マイクロサービスアーキテクチャであっても、モノリシックアーキテクチャであっても、問題ない。
本格的なカオスエンジニアリングを採用している日系企業は少なく、国内事例はまだ少ない。
障害の発生対象に合わせて、ツールを選ぶ必要がある。
| ツール | 発生先 |
|---|---|
| Chaos Mesh | AWS、Google Cloud、Kubernetes |
| Chaos Monkey | AWS |
▼ フォールトインジェクション¶
カオスエンジニアリングの一種である。
マイクロサービスアーキテクチャなシステムの一部分にランダムな障害を意図的に注入し、高負荷な状態に至らせる。
障害の発生対象に合わせて、ツールを選ぶ必要がある。
| ツール | 発生先 |
|---|---|
| Istio | Kubernetes |
| AWS Fault Injection Simulator | AWS |
▼ 手順¶
(1)-
本番環境のシステムからさまざまなテレメトリーを収集し、安定している通常状態 (定常状態) を定義する。
(2)-
定常状態を対照群、またカオスエンジニアリングが実施された状態を実験群とする。『実験群では障害が起こる』という仮説の下、これを反証することを目指す。
(3)-
実験群でカオスエンジニアリングを実施する。
(4)-
対照群と比較し、『障害は起こる』という仮説を反証する。
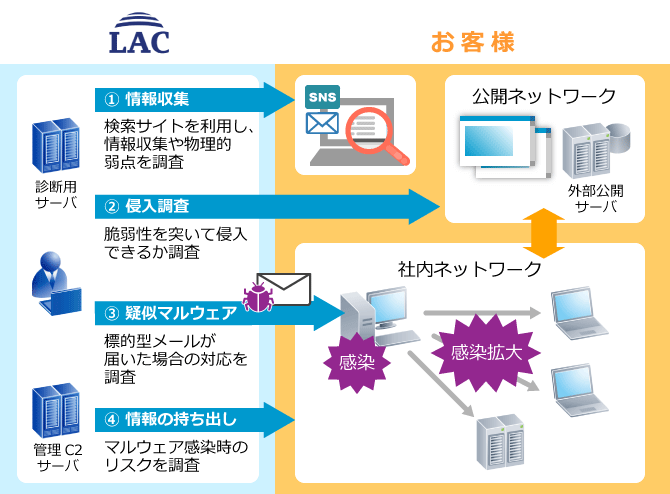
07. ペネトレーションテスト¶
既知のサイバー攻撃を意図的に行い、システムの脆弱性を確認するテストのこと。
*例*
株式会社 LAC によるペネトレーションテストサービス
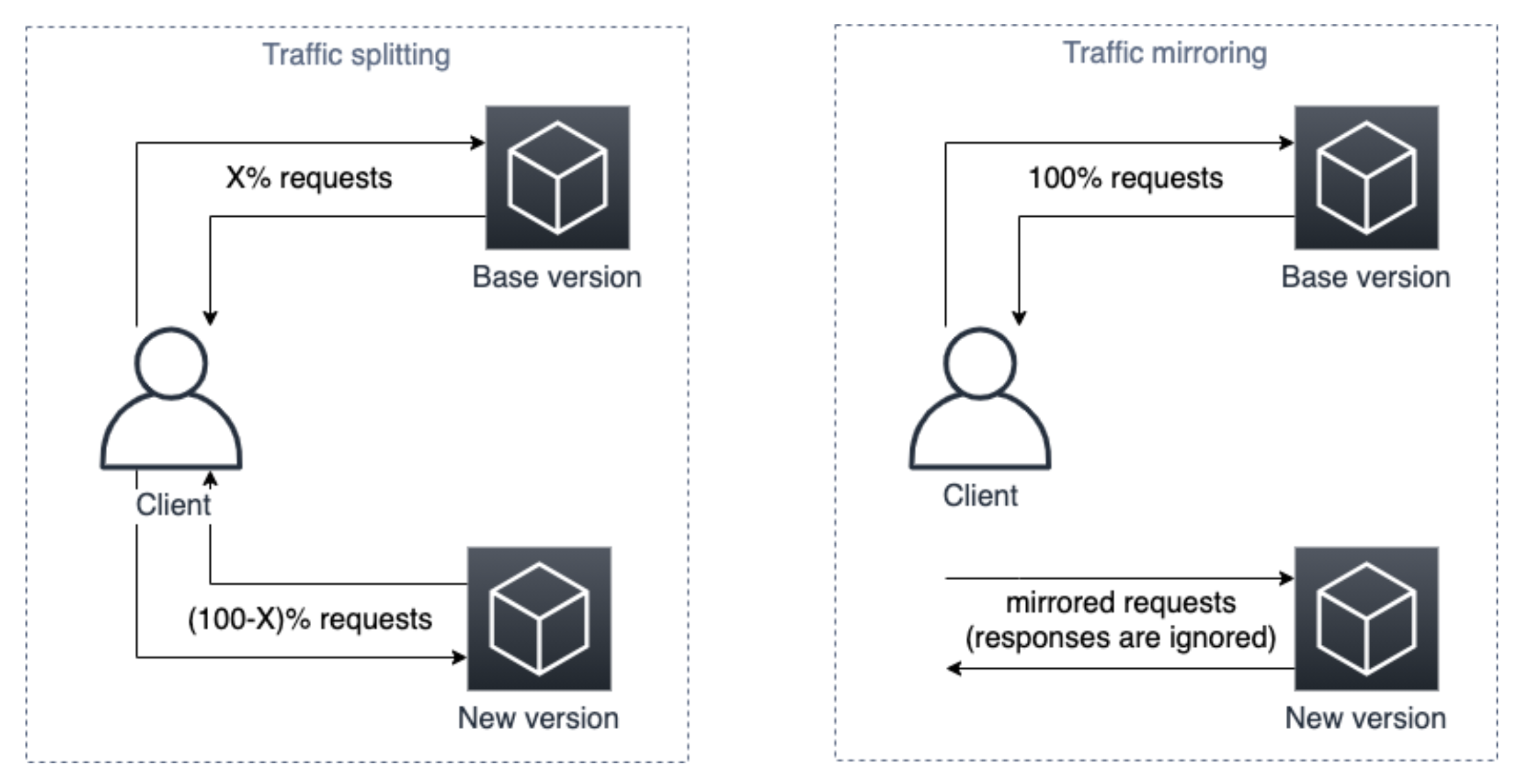
08. ポートミラーリング (ミラーリング、トラフィクミラーリング、トラフィックシャドーイング)¶
『ミラーリング』『トラフィックミラーリング』『トラフィックシャドーイング』ともいう。
特定のポートで送受信されるパケットをコピーし、別のポートに送信する。
本番環境に対するリクエストのコピーをテスト環境にミラーリングし、テスト環境を検証できる。
テスト環境からのレスポンスは破棄されるので、ユーザーに影響がない。