Amazon Aurora@AWSリソース¶
はじめに¶
本サイトにつきまして、以下をご認識のほど宜しくお願いいたします。
01. Amazon Auroraとは¶
Amazon RDS をよりマネージドにした AWS リソースである。
02. セットアップ (コンソールの場合)¶
2-02. セットアップ (Terraformの場合)¶
# 記入中...
DBエンジン¶
| 設定項目 | 説明 | 補足 |
|---|---|---|
| エンジンタイプ | ミドルウェアのDBMSの種類を設定する。 | |
| エディション | エンジンバージョンでAmazon Auroraを選択した場合の互換性を設定する。 | |
| エンジンバージョン | DBエンジンのバージョンを設定する。DBクラスター内のすべてのDBインスタンスに適用される。 | ・Amazon Auroraであれば、SELECT AURORA_VERSION() を使用して、エンジンバージョンを確認できる。 |
▼ Amazon AuroraのDBクラスター¶
ベストプラクティスについては、以下のリンクを参考にせよ。
| 設定項目 | 説明 | 補足 |
|---|---|---|
| レプリケーション | 単一のプライマリーインスタンス (シングルマスター) または複数のプライマリーインスタンス (マルチマスター) とするかを設定する。 | フェイルオーバーを利用したダウンタイムの最小化時に、マルチマスターであれば変更の順番を気にしなくてよくなる。ただし、Amazon AuroraのDBクラスターをクローンできないなどのデメリットもある。 https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/aurora-multi-master.html#aurora-multi-master-terms |
| Amazon AuroraのDBクラスター識別子 | Amazon AuroraのDBクラスター名を設定する。 | インスタンス名は、最初に設定できず、Amazon RDSの作成後に設定できる。 |
| VPCとサブネットグループ | Amazon AuroraのDBクラスターを配置するVPCとサブネットを設定する。 | DBが配置されるサブネットはプライベートサブネットにする、これには、data storeサブネットと名付ける。アプリケーション以外は、踏み台サーバー (Amazon EC2) 経由でしかDBにリクエストできないようにする。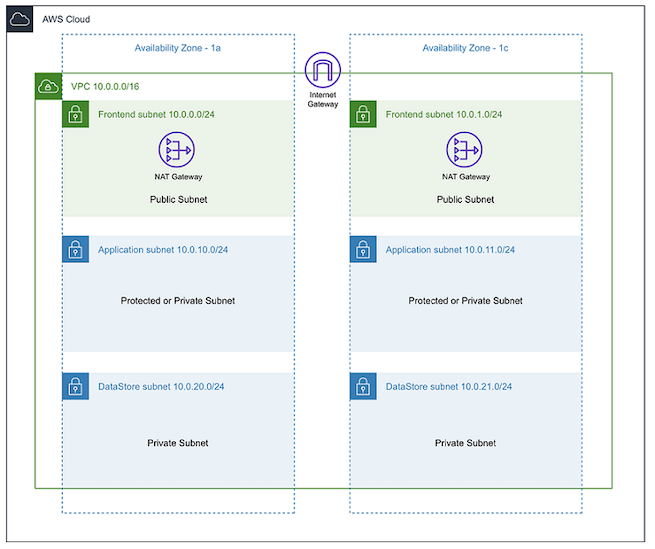 |
| パラメーターグループ | グローバルオプションを設定する。 | デフォルトを使用せずに自前定義する場合、事前に作成しておく必要がある。クラスターパラメーターグループとインスタンスパラメーターグループがあるが、すべてのインスタンスに同じパラメーターループを設定する必要があるなため、クラスターパラメーターを使用すればよい。各パラメーターに適用タイプ (dynamic/static) があり、dynamicタイプは設定の適用に再起動が必要である。新しく作成したクラスタパラメーターグループにて以下の値を設定するとよい。 ・ time_zone=Asia/Tokyo・ character_set_client=utf8mb4・ character_set_connection=utf8mb4・ character_set_database=utf8mb4・ character_set_results=utf8mb4・ character_set_server=utf8mb4・ server_audit_logging=1 (監査ログをAmazon CloudWatchに送信するか否か) ・ server_audit_logs_upload=1・ general_log=1 (通常クエリログをAmazon CloudWatchに送信するか否か) ・ slow_query_log=1 (スロークエリログをAmazon CloudWatchに送信するか否か) ・ long_query_time=3 (スロークエリと見なす最短秒数) |
| DB認証 | DBに接続するための認証方法を設定する。 | Amazon Auroraの各DBインスタンスに異なるDB認証を設定できるが、すべてのAmazon AuroraのDBインスタンスに同じ認証方法を設定すべきなため、Amazon AuroraのDBクラスターでこれを設定すればよい。 |
| マスタユーザー名 | DBのroot権限の実行ユーザーを設定 | |
| マスターパスワード | DBのroot権限の実行ユーザーのパスワードを設定 | |
| 暗号化キー | AWS KMSを使用して、データを暗号化して保管する。 | |
| バックアップ保管期間 | Amazon AuroraのDBクラスター がバックアップを保管する期間を設定する。 | 7 日間にしておく。 |
| ログのエクスポート | Amazon CloudWatch Logsに送信するデータエンジン (例:MySQL) のログを設定する。DBエンジンの一般ログ、エラーログ、スロークエリログ、監査ログなどを選択できる。 | すべてのログを選択するとよい。 |
| セキュリティグループ | Amazon AuroraのDBクラスターのセキュリティグループを設定する。 | コンピューティングからのリクエストのみを許可するように、これらのプライベートIPアドレス (*.*.*.*/32) を設定する。 |
| 認証機関 | Amazon AuroraのDBクラスターに紐づけるサーバー証明書を署名するルート認証局を設定する。 | アプリケーションがAmazon AuroraのDBクラスターにHTTPSで通信する場合に必要である。 |
| 削除保護 | Amazon AuroraのDBクラスターの削除を防ぐ。 | Amazon AuroraのDBクラスターを削除するとクラスターボリュームも削除されるため、これを防ぐ。補足として、Amazon AuroraのDBクラスターの削除保護になっていてもAmazon AuroraのDBインスタンスは削除できる。Amazon AuroraのDBインスタンスを削除しても、再作成すればクラスターボリュームに接続されて元のデータにリクエストを送信できる。 https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/USER_DeleteCluster.html#USER_DeletionProtection |
▼ Amazon AuroraのDBインスタンス¶
ベストプラクティスについては、以下のリンクを参考にせよ。
| 設定項目 | 説明 | 補足 |
|---|---|---|
| インスタンスクラス | Amazon AuroraのDBインスタンスのスペックを設定する。サーバーレス、メモリ最適化、バースト可能などを選択できる。 | バースト可能クラスを選択するとよい。補足として、Amazon AuroraのDBサイズは自動的にスケーリングするため、設定する必要がない。 |
| パブリックアクセス | Amazon AuroraのDBインスタンスにIPアドレスを割り当てるか否かを設定する。 | |
| キャパシティタイプ | ||
| マルチAZ配置 | プライマリーインスタンスとは別に、リードレプリカをマルチAZ配置で追加するか否かを設定する。 | 後からでもリードレプリカを追加できる。また、フェイルオーバー時にリードレプリカが存在していなければ、昇格後のプライマリーインスタンスが自動的に作成される。 |
| 最初のDB名 | Amazon AuroraのDBインスタンスに自動的に作成されるDB名を設定 | |
| マイナーバージョンの自動アップグレード | Amazon AuroraのDBインスタンスのDBエンジンのバージョンを自動的に更新するかを設定する。 | 開発環境では有効化、本番環境とステージング環境では無効化しておく。開発環境で新バージョンに問題が起こらなければ、ステージング環境と本番環境にも適用する。 |
OSの隠蔽¶
▼ OSの隠蔽とは¶
Amazon Aurora は、EC2 内に DBMS が稼働したものであるが、このほとんどが隠蔽されている。
そのため DB サーバーのようには操作できず、OS のバージョン確認や SSH 公開鍵認証を行えない。
▼ 確認方法¶
Linux x86_64 (AMD64) が使用されているところまでは確認できるが、Linux のバージョンは隠蔽されている。
Amazon RDS でも確認方法は同じである。
-- Amazon Auroraの場合
SHOW VARIABLES LIKE '%version%';
+-------------------------+------------------------------+
| Variable_name | Value |
+-------------------------+------------------------------+
| aurora_version | 2.09.0 |
| innodb_version | 5.7.0 |
| protocol_version | 10 |
| slave_type_conversions | |
| tls_version | TLSv1,TLSv1.1,TLSv1.2 |
| version | 5.7.12-log |
| version_comment | MySQL Community Server (GPL) |
| version_compile_machine | x86_64 |
| version_compile_os | Linux |
+-------------------------+------------------------------+
02-02. 踏み台サーバーをパブリックサブネットに置く場合の接続方法¶
SSH公開鍵認証を使用する場合¶
▼ この方法について¶
SSH 公開鍵認証を使用する場合、ユーザーが自前で DB 接続者を管理する必要がある。
この場合、踏み台サーバー (Amazon EC2) をパブリックサブネットに置く必要があり、プライベートサブネットには置けない。
▼ セットアップ¶
$ ssh -o serveraliveinterval=60 -f -N -L 3306:<Amazon Auroraのリーダーエンドポイント>:3306 -i "~/.ssh/foo.pem" <踏み台サーバーの実行ユーザー>@<踏み台サーバー (Amazon EC2) のホスト> -p 22
02-03. 踏み台サーバーをプライベートサブネットに置く場合の接続方法¶
AWS SSM Session Managerを使用したSSHセッション¶
▼ この方法について¶
この場合、AWS SSM Session Manager を使用するため、踏み台サーバー (Amazon EC2) をプライベートサブネットに置ける。
AWS SSM Session Managerを使用したリモートホストへのポートフォワーディング (StartPortForwardingSessionToRemoteHost)¶
▼ この方法について¶
AWS SSM Session Manager の認証を使用する場合、AWS IAM で DB 接続者を管理する。
この場合、AWS SSM Session Manager を使用するため、踏み台サーバー (Amazon EC2) をプライベートサブネットに置ける。
▼ 前提条件¶
事前に、踏み台サーバー (Amazon EC2) のセキュリティグループのインバウンドルールでポート番号を開放しておく。
以下のツールをインストールすること
- AWS CLI (セットアップ時点で最新のもの)
- Session Managerプラグイン (使用中の PC の OS に合わせること)
▼ セットアップ¶
ローカル PC の好きなポート番号を使用して、ポートフォワーディングを実施する。
ローカル PC では、コンテナなどが 3306 番ポートをすでに使用している可能性があり、他のポート番号がおすすめである。
# ポートフォワーディングのコマンドを実行する (事前にAWS Session Managerプラグインをインストールしないとエラーになる)
$ aws ssm start-session --target <踏み台サーバー (Amazon EC2) インスタンスID> \
--document-name AWS-StartPortForwardingSessionToRemoteHost \
--parameters '{"host":["<Amazon Auroraのリーダーエンドポイント>"],"portNumber":["<Amazon Auroraのポート番号>"], "localPortNumber":["<ローカルPCのポート番号>"]}'
別ターミナルを開き、Amazon Aurora の DB にログインする。
AWS Secrets Manager の DB のユーザー名やパスワードを確認できる。
$ docker exec -it <DBコンテナ名> bash
bash# mysql -h host.docker.internal -P <前の手順で設定したローカルPCの好きなポート番号> -u <ユーザー名> -p<パスワード> <DB名>
mysql> SHOW TABLES;
+-------------------------------+
| Tables_in_<DB名> |
+-------------------------------+
...
- https://dev.classmethod.jp/articles/ssm-session-manage-port-forwarding/#toc-1
- https://docs.aws.amazon.com/systems-manager/latest/userguide/session-manager-working-with-sessions-start.html#sessions-remote-port-forwarding
- https://docs.aws.amazon.com/systems-manager/latest/userguide/install-plugin-macos-overview.html
02-04. 踏み台PodをAmazon EKSクラスター内に置く場合の接続方法¶
踏み台Podとは¶
これは、Amazon EKS を使用している場合に使用できる。
DB に接続したい場合、ポートフォワーディング用の踏み台 Pod を Amazon EKS 内に作成する。
Helm チャートを作成しておくと、簡単にセットアップできる。
troubleshootingリポジトリ¶
troubleshooting/
├── README.md
├── .gitignore
├── chart/
│ ├── Chart.yaml
│ ├── templates
│ │ └── deployment.yaml
│ │
│ ├── .helmignore
│ ├── values.example.yaml
│ └── values.yaml
└── helmfile.yaml
.gitignore ファイルでは、values.example.yaml ファイルのコピーから作成される values.yaml ファイルのバージョン管理を無視するように実装する。
**/**/values.yaml
values.example.yaml¶
.env ファイルのように、バージョン管理しない values.example.yaml ファイルを用意しておく。
各開発者がローカル PC で values.example.yaml ファイルから values.yaml ファイルを作成する。
$ cp chart/values.example.yaml values.yaml
name: port-forward-for-aws-aurora
remote:
# Amazon Auroraのリーダーエンドポイントを設定する
host: <ここに自分で値を設定する>
# Amazon Auroraのポート番号を設定する
port: <ここに自分で値を設定する>
▼ pod.yaml¶
apiVersion: apps/v1
kind: Deployment
metadata:
name: {{.Values.name}}
spec:
replicas: 1
selector:
matchLabels:
name: {{.Values.name}}
template:
metadata:
labels:
name: {{.Values.name}}
spec:
containers:
- name: {{.Values.name}}
image: marcnuri/port-forward:latest
ports:
- containerPort: 443
env:
- name: LOCAL_PORT
value: "443"
- name: REMOTE_HOST
value: {{.Values.remote.host}}
- name: REMOTE_PORT
value: {{.Values.remote.port | quote}}
$ helmfile -f helmfile.yaml diff
$ helmfile -f helmfile.yaml apply
▼ コマンド¶
ローカル PC の好きなポート番号を使用して、Amazon Aurora にポートフォワーディングを実行する。
ローカル PC では、コンテナなどが 3306 番ポートをすでに使用している可能性があり、他のポート番号がおすすめである。
$ kubectl port-forward deployment/port-forwarding-for-aws-aurora -n <Namespace名> <ローカルPCの好きなポート番号>:443
別ターミナルを開き、Amazon Aurora の DB にログインする。
AWS Secrets Manager の DB のユーザー名やパスワードを確認できる。
$ docker exec -it <DBコンテナ名> bash
bash# mysql -h host.docker.internal -P <前の手順で設定したローカルPCの好きなポート番号> -u <ユーザー名> -p<パスワード> <DB名>
mysql> SHOW TABLES;
+-------------------------------+
| Tables_in_<DB名> |
+-------------------------------+
...
02-05. Amazon ECS Fargateをプライベートサブネットに置く場合の接続方法¶
記入中...
03. Amazon AuroraのDBクラスター¶
Amazon AuroraのDBクラスターとは¶
DB エンジンに Amazon Aurora を選択した場合にのみ使用できる。
Amazon Aurora の DB インスタンスとクラスターボリュームから構成されている。
コンピューティングとして動作する Amazon Aurora の DB インスタンスと、ストレージとして動作するクラスターボリュームが分離されているため、Amazon Aurora の DB インスタンスが誤ってすべて削除されてしまったとしても、データを守れる。
また、両者が分離されていないエンジンタイプと比較して、再起動が早いため、再起動に伴うダウンタイムが短い。
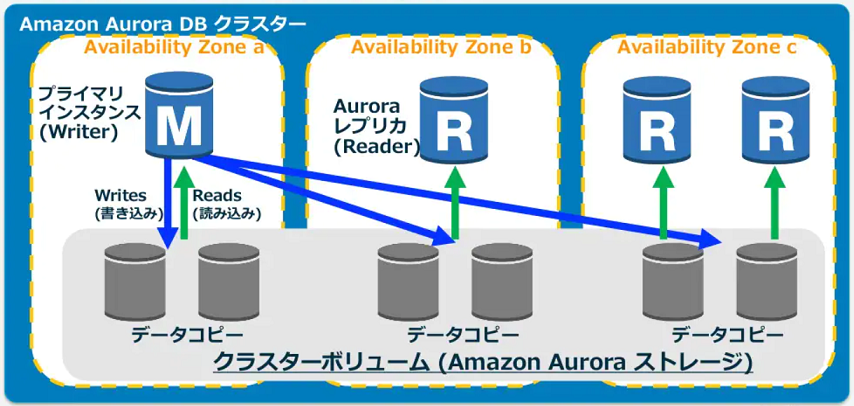
空のAmazon AuroraのDBクラスター¶
▼ 空のAmazon AuroraのDBクラスターとは¶
コンソール画面にて、Amazon Aurora の DB クラスター内のすべての Amazon Aurora の DB インスタンスを削除すると、Amazon Aurora の DB クラスターも自動的に削除される。
一方で、AWS-API をコールしてすべての Amazon Aurora の DB インスタンスを削除する場合、Amazon Aurora の DB クラスターは自動的に削除されずに、空の状態になる。
例えば、Terraform を使用して Amazon Aurora の DB クラスターを作成するときに、インスタンスの作成に失敗すると Amazon Aurora の DB クラスターが空になる、
これは、Terraform が AWS-API をコールして作成しているためである。
04. Amazon AuroraのDBインスタンス¶
Amazon AuroraのDBインスタンスとは¶
コンピューティング機能を持ち、クラスターボリュームを操作できる。
Amazon AuroraのDBインスタンスの種類¶
| プライマリーインスタンス | リードレプリカ | |
|---|---|---|
| ロール | 読み出し/書き込みインスタンス | 読み出しオンリーインスタンス |
| CRUD制限 | 制限なし。アカウントの認可スコープに依存する。 | アカウントの認可スコープに関係なく、READしか実行できない。 |
| エンドポイント | Amazon Auroraの各DBインスタンスに、リージョンのイニシャルに合わせたエンドポイントが割り振られる。 | Amazon Auroraの各Amazon AuroraのDBインスタンスに、リージョンのイニシャルに合わせたエンドポイントが割り振られる。 |
| データ同期 | Amazon AuroraのDBクラスターに対するデータ変更を受けつける。 | 読み出し/書き込みインスタンスのデータの変更が同期される。 |
エンドポイント¶
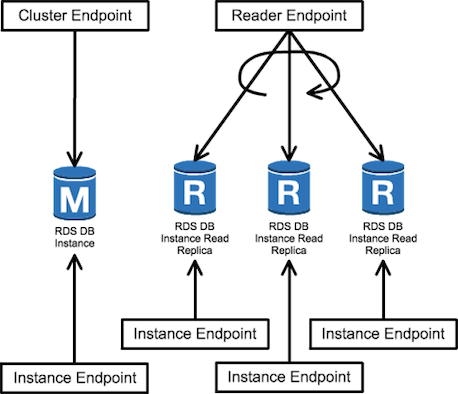
| エンドポイント名 | 役割 | 送信先 | エンドポイント:ポート番号 | 説明 |
|---|---|---|---|---|
| クラスターエンドポイント | 書き込み/読み出し | プライマリインスタンスのみ | <Amazon AuroraのDBクラスター名>.cluster-<id>.ap-northeast-1.rds.amazonaws.com:<ポート番号> |
プライマリーインスタンスに通信できる。プライマリーインスタンスがダウンし、フェイルオーバーによってプライマリーインスタンスとリードレプリカが入れ替わった場合、エンドポイントのフォワーディング先は新しいプライマリーインスタンスに変更される。 https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/Amazon Aurora.Overview.Endpoints.html#Amazon Aurora.Endpoints.Cluster |
| リーダーエンドポイント | 読み出し | 複数のリードレプリカに分散 | <Amazon AuroraのDBクラスター名>.cluster-ro-<id>.ap-northeast-1.rds.amazonaws.com:<ポート番号> |
リードレプリカに通信できる。Amazon AuroraのDBインスタンスが複数ある場合、クエリが自動的に割り振られる。フェイルオーバーによってプライマリーインスタンスとリードレプリカが入れ替わった場合、エンドポイントのフォワーディング先は新しいプライマリーインスタンスに変更される。もしリードレプリカがすべてダウンし、プライマリーインスタンスしか稼働していない状況の場合、プライマリーインスタンスにフォワーディングするようになる。 https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/Amazon Aurora.Overview.Endpoints.html#Amazon Aurora.Endpoints.Reader |
| インスタンスエンドポイント | 書き込み/読み出し (指定したAmazon AuroraのDBインスタンスによる) | 特定のAmazon AuroraのDBインスタンス | <Amazon AuroraのDBインスタンス名>.cwgrq25vlygf.ap-northeast-1.rds.amazonaws.com:<ポート番号> |
選択したAmazon AuroraのDBインスタンスに通信できる。フェイルオーバーによってプライマリーインスタンスとリードレプリカが入れ替わっても、エンドポイントそのままなため、アプリケーションが影響を付ける。非推奨である。 |
| カスタムエンドポイント |
DBエンジンのログ¶
▼ スロークエリログ¶
Amazon CloudWatch Logs の /aws/rds/cluster/<Amazon AuroraのDBクラスター名>/slowquery というロググループにスロークエリログが出力される。
▼ エラークエリログ¶
Amazon CloudWatch Logs の /aws/rds/cluster/<Amazon AuroraのDBクラスター名>/error というロググループにエラーログが出力される。
05. アップグレード¶
ZDP (ゼロダウンタイムパッチ適用)¶

Amazon Aurora をエンジンバージョンとして選択した場合に使用でき、パッチバージョンとマイナーバージョンの更新で、条件を満たせば適用される。
特定の条件下のみで、アプリケーションとプライマリーインスタンスの接続を維持したまま、プライマリーインスタンスのパッチバージョンをアップグレードできる。
ゼロダウンタイムパッチ適用が発動した場合、Amazon RDS のイベントが記録される。
ただし、この機能に頼り切らないほうがよい。
ゼロダウンタイムパッチ適用の発動は AWS から事前にお知らせされるわけでもなく、ユーザーが条件を見て発動の有無を判断しなければならない。
ただ、実際に発動していても、ダウンタイムが発生した事例も報告されている。
ゼロダウンタイムパッチ適用時、以下の手順でエンジンバージョンがアップグレードされる。
(1)-
プライマリーインスタンスのエンジンがアップグレードされ、このときにダウンタイムが発生しない代わりに、
5秒ほどプライマリーインスタンスの性能が低下する。 (2)-
リードレプリカが再起動され、このときに
20~30秒ほどダウンタイムが発生する。これらの仕組みのため、アプリケーションでは読み出しエンドポイントを接続先として使用しないようにする必要がある。
アップグレード可能かのバリデーション¶
アップグレードに伴う問題を静的解析で検出する。
Amazon Aurora に SSH 接続したうえで、DB に対して以下のコマンドを実行すると、v5.7 から v8 系へのアップグレードで問題が起こるかを解析できる
ただ、アプリ側の SQL のロジックは解析できない。あくまで MySQL の設定値のみを解析でき、廃止予定のロジックを使っているかまでは見つけられない。
$ mysqlsh util.checkForServerUpgrade()
ダウンタイム¶
▼ ダウンタイムとは¶
Amazon Aurora では、設定値 (例:OS、エンジンバージョン、MySQL) のアップグレード時に、Amazon Aurora の DB インスタンスの再起動が必要である。
再起動に伴ってダウンタイムが発生し、アプリケーションから DB に接続できなくなる。
この間、アプリケーションの利用者に与える影響を小さくできるように、計画的にダウンタイムを発生させる必要がある。
▼ ダウンタイムの発生条件¶
Amazon RDS にはダウンタイムに関する情報が多いが、Amazon Aurora には情報が少ない。
ただし、経験上同じ項目でダウンタイムが発生しているため、他の項目についても Amazon RDS のダウンタイムも参考になる。
| 変更する項目 | ダウンタイムの有無 | 補足 |
|---|---|---|
| エンジンバージョン | あり | メジャーバージョンのアップグレードでは、ダウンタイムが起こる。パッチバージョンの場合は、ZDPでダウンタイムが起こらない可能性がある。では 20~30 秒のダウンタイムが発生する。この時間は、ワークロード、クラスターサイズ、バイナリログデータのサイズ、ゼロダウンタイムパッチ適用の発動可否、によって変動する。・https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/AuroraMySQL.Updates.html ・https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/AuroraMySQL.Updates.Patching.html#AuroraMySQL.Updates.AMVU また、メジャーバージョンのアップグレードには 10 分のダウンタイムが発生する。https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/USER_UpgradeDBInstance.MySQL.html#USER_UpgradeDBInstance.MySQL.Major.Overview |
▼ エンジンタイプによるダウンタイムの最小化¶
コンピューティングとストレージが分離している Amazon Aurora はエンジンタイプのなかでもダウンタイムが短い。
▼ ダウンタイムの計測例¶
アプリケーションにリクエストを送信する方法と、Amazon RDS にクエリを直接的に送信する方法がある。
レスポンスと Amazon RDS イベントログから、ダウンタイムを計測する。
*実装例*
Amazon Aurora MySQL のアップグレードに伴うダウンタイムを計測する。
踏み台サーバー (Amazon EC2) を経由して Amazon RDS に接続し、現在時刻を取得する SQL を送信する。
このとき、for 文や watch コマンドを使用する。
ただし、watch コマンドはプリインストールされていない可能性がある。
平常アクセス時のも同時に実行することにより、より正確なダウンタイムを取得する。
また、ヘルスチェックの時刻をまさしくロギングできるように、ローカルマシンから時刻を取得する。
#!/bin/bash
set -x
BASTION_HOST=""
BASTION_USER=""
DB_HOST=""
DB_PASSWORD=""
DB_USER=""
SECRET_KEY="~/.ssh/foo.pem"
SQL="SELECT NOW();"
ssh -o serveraliveinterval=60 -f -N -L 3306:${DB_HOST}:3306 -i ${SECRET_KEY} ${BASTION_USER}@${BASTION_HOST} -p 22
# 約15分間コマンドを繰り返す。
for i in {1..900}; do
echo "---------- No. ${i} Local PC: $(date +"%Y-%m-%d %H:%M:%S") ------------" >> health_check.txt
echo "$SQL" | mysql -u "$DB_USER" -P 3306 -p"$DB_PASSWORD" >> health_check.txt 2>&1
# 1秒待機する。
sleep 1
done
#!/bin/bash
set -x
BASTION_HOST=""
BASTION_USER=""
DB_HOST=""
DB_PASSWORD=""
DB_USER=""
SECRET_KEY="~/.ssh/foo.pem"
SQL="SELECT NOW();"
ssh -o serveraliveinterval=60 -f -N -L 3306:${DB_HOST}:3306 -i ${SECRET_KEY} ${BASTION_USER}@${BASTION_HOST} -p 22
# 1秒ごとにコマンドを繰り返す。
watch -n 1 'echo "---------- No. ${i} Local PC: $(date +"%Y-%m-%d %H:%M:%S") ------------" >> health_check.txt && \
echo ${SQL} | mysql -u ${DB_USER} -P 3306 -p${DB_PASSWORD} >> health_check.txt 2>&1'
上記のシェルスクリプトにより、例えば次のような MySQL のログを取得できる。
このログからは、15:23:09 〜 15:23:14 の間で、接続に失敗していることを確認できる。
---------- No. 242 Local PC: 2021-04-21 15:23:06 ------------
mysql: [Warning] Using a password on the command line interface can be insecure.
NOW()
2021-04-21 06:23:06
---------- No. 243 Local PC: 2021-04-21 15:23:07 ------------
mysql: [Warning] Using a password on the command line interface can be insecure.
NOW()
2021-04-21 06:23:08
---------- No. 244 Local PC: 2021-04-21 15:23:08 ------------
mysql: [Warning] Using a password on the command line interface can be insecure.
ERROR 2026 (HY000): SSL connection error: error:00000000:lib(0):func(0):reason(0)
---------- No. 245 Local PC: 2021-04-21 15:23:09 ------------
mysql: [Warning] Using a password on the command line interface can be insecure.
ERROR 2013 (HY000): Lost connection to MySQL server at 'reading initial communication packet', system error: 0
---------- No. 246 Local PC: 2021-04-21 15:23:10 ------------
mysql: [Warning] Using a password on the command line interface can be insecure.
ERROR 2013 (HY000): Lost connection to MySQL server at 'reading initial communication packet', system error: 0
---------- No. 247 Local PC: 2021-04-21 15:23:11 ------------
mysql: [Warning] Using a password on the command line interface can be insecure.
ERROR 2013 (HY000): Lost connection to MySQL server at 'reading initial communication packet', system error: 0
---------- No. 248 Local PC: 2021-04-21 15:23:13 ------------
mysql: [Warning] Using a password on the command line interface can be insecure.
ERROR 2013 (HY000): Lost connection to MySQL server at 'reading initial communication packet', system error: 0
---------- No. 249 Local PC: 2021-04-21 15:23:14 ------------
mysql: [Warning] Using a password on the command line interface can be insecure.
ERROR 2013 (HY000): Lost connection to MySQL server at 'reading initial communication packet', system error: 0
---------- No. 250 Local PC: 2021-04-21 15:23:15 ------------
mysql: [Warning] Using a password on the command line interface can be insecure.
NOW()
2021-04-21 06:23:16
---------- No. 251 Local PC: 2021-04-21 15:23:16 ------------
mysql: [Warning] Using a password on the command line interface can be insecure.
NOW()
2021-04-21 06:23:17
アップグレード時のプライマリーインスタンスの Amazon RDS イベントログは以下の通りで、ログによるダウンタイムは、再起動からシャットダウンまでの期間と一致することを確認する。

補足として、リードレプリカは再起動のみを実行していることがわかる。

フェイルオーバー¶
▼ Amazon Auroraのフェイルオーバーとは¶
プライマリーインスタンスで障害が起こった場合に、リードレプリカをプライマリーインスタンスに自動的に昇格する。
Amazon Aurora の DB クラスター内のすべての Amazon Aurora の DB インスタンスが同じ AZ に配置されている場合、あらかじめ異なる AZ にリードレプリカを新しく作成する必要がある。
また、フェイルオーバー時に、もし Amazon Aurora の DB クラスター内にリードレプリカが存在していない場合、異なる AZ に昇格後のプライマリーインスタンスが自動的に作成される。
リードレプリカが存在している場合、これがプライマリーインスタンスに昇格する。
- https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/Concepts.AuroraHighAvailability.html#Amazon Aurora.Managing.FaultTolerance
▼ フェイルオーバーによるダウンタイムの最小化¶
Amazon Aurora の DB インスタンスがマルチ AZ 構成の場合、以下の手順を使用してダウンタイムを最小化できる。
(1)-
アプリケーションの接続先をプライマリーインスタンスにする。
(2)-
リードレプリカにダウンタイムの発生する変更を適用する。
Amazon Auroraではフェールオーバーが自動的に実行される。
(3)-
フェイルオーバー時に約
1~2分のダウンタイムが発生する。フェイルオーバーを使用しない場合、Amazon AuroraのDBインスタンスの再起動でダウンタイムが発生する。
ただし、これよりは時間が短いため、相対的にダウンタイムを短縮できる。
▼ Amazon AuroraのDBインスタンスの昇格優先順位¶
Amazon Aurora の場合、フェイルオーバーによって昇格する Amazon Aurora の DB インスタンスは次の順番で決定される。
Amazon Aurora の DB インスタンスごとにフェイルオーバーの優先度 (0~15) を設定でき、優先度の数値の小さい Amazon Aurora の DB インスタンスほど優先され、昇格対象になる。
優先度が同じだと、インスタンスクラスが大きい Amazon Aurora の DB インスタンスが昇格対象になる。
インスタンスクラスが同じだと、同じサブネットにある Amazon Aurora の DB インスタンスが昇格対象になる。
(1)-
優先度の順番
(2)-
インスタンスクラスの大きさ
(3)-
同じサブネット
▼ ダウンタイムを最小化できない場合¶
エンジンバージョンのアップグレードは両方の Amazon Aurora の DB インスタンスで同時に実行する必要があるため、フェイルオーバーを使用できず、ダウンタイムを最小化できない。
B/G式アップグレード¶
アップグレード時に、新しいバージョンからなる Amazon Aurora の DB クラスター (グリーン環境) を作成する。
クラスターエンドポイントを起点として、アプリケーションのクエリの向き先を既存の Amazon Aurora の DB クラスター (ブルー環境) から新 Amazon Aurora の DB クラスター (グリーン環境) に切り替える。
グリーン環境でアプリケーションが問題なく動作すれば、既存の Amazon Aurora の DB クラスター (ブルー環境) を削除する。
06. 負荷対策¶
エンドポイントの使い分け¶
Amazon Aurora の DB インスタンスに応じたエンドポイントが用意されている。
アプリケーションからの CRUD の種類に応じて、宛先を振り分けることにより、負荷を分散させられる。
読み出しオンリーエンドポイントに対して、READ 以外の処理を行うと、以下の通り、エラーとなる。
/* SQL Error (1290): The MySQL server is running with the --read-only option so it cannot execute this statement */
リードレプリカの手動追加、AWS Auto Scalingグループ¶
リードレプリカの手動追加もしくは AWS Auto Scaling グループによって、Amazon Aurora に関するメトリクス (例:平均 CPU 使用率、平均 DB 接続数など) がターゲット値を維持できるように、リードレプリカの自動水平スケーリング (リードレプリカ数の増減) を実行する。
注意点として、Amazon RDS のスケーリングは、ストレージサイズを増加させる垂直スケーリングであり、Amazon Aurora のスケーリングとは仕様が異なっている。
クエリキャッシュの利用¶
MySQL や Redis のクエリキャッシュ機能を利用する。
ただし、MySQL のクエリキャッシュ機能は、バージョン 8 で廃止されることになっている。
ユニークキーまたはインデックスの利用¶
スロークエリを検出し、その SQL で対象としているカラムにユニークキーやインデックスを設定する。
スロークエリを検出する方法として、Amazon RDS の long_query_time パラメーターによる閾値や、EXPLAIN による予想実行時間の比較などがある。
CloudWatch Logs インサイト上で、閾値以上の実行時間のスロークエリを実行時間の昇順で取得できる。
fields @timestamp, @message
| parse @message /Query_time:\s*(?<Query_time>[0-9]+(?:\.[0-9]+)?)\s*[\s\S]*?;/
| display @timestamp, Query_time, @message
| sort Query_time desc
| limit 100
テーブルを正規化し過ぎない¶
テーブルを正規化すると保守性が高まるが、アプリケーションの SQL で JOIN が必要になる。
しかし、JOIN を含む SQL は、含まない SQL と比較して、実行速度が遅くなる。
そこで、戦略的に正規化し過ぎないようにする。
インスタンスタイプのスケールアップ¶
インスタンスタイプをスケールアップさせることにより、接続過多のエラー (ERROR 1040 (HY000): Too many connections) に対処する。
補足として現在の最大接続数はパラメーターグループの値から確認できる。
コンソール画面からはおおよその値しかわからないため、SQL で確認したほうがよい。
SHOW GLOBAL VARIABLES LIKE 'max_connections';
+-----------------+-------+
| Variable_name | Value |
+-----------------+-------+
| max_connections | 640 |
+-----------------+-------+
1 row in set (0.00 sec)
07. イベント¶
コンソール画面ではイベントが英語で表示されているため、リファレンスも英語でイベントを探したほうがよい。
08. Amazon Aurora Global DB¶
Amazon Aurora Global DBとは¶
リージョン間に跨いだ Amazon Aurora の DB クラスターから構成されている。
メインリージョンにあるプライマリークラスターのクラスターボリュームと、DR リージョンのセカンダリークラスターのクラスターボリュームのデータは、定期的に同期される。
プライマリーインスタンスは、プライマリークラスターのみに存在している。
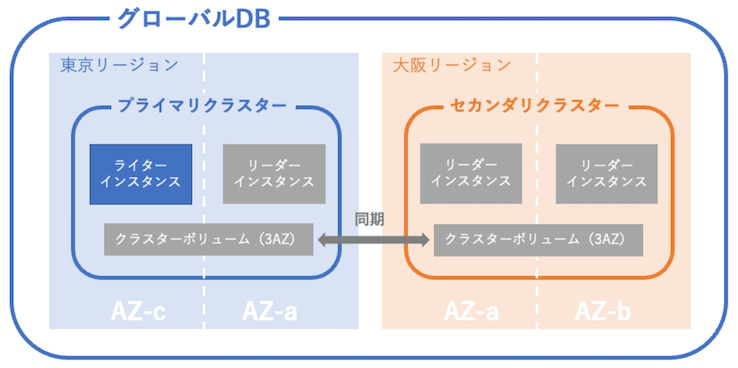
クラスターボリュームのみのセカンダリーDBクラスター (ヘッドレスセカンダリーAmazon AuroraのDBクラスター)¶
『ヘッドレスセカンダリーDB クラスター』ともいう。
コスト削減などを目的として、クラスターボリュームのみのセカンダリ Amazon Aurora の DB クラスターがある。
セカンダリーDB クラスターのリードレプリカを削除すると、ヘッドレスセカンダリーDB クラスターを作成できる。
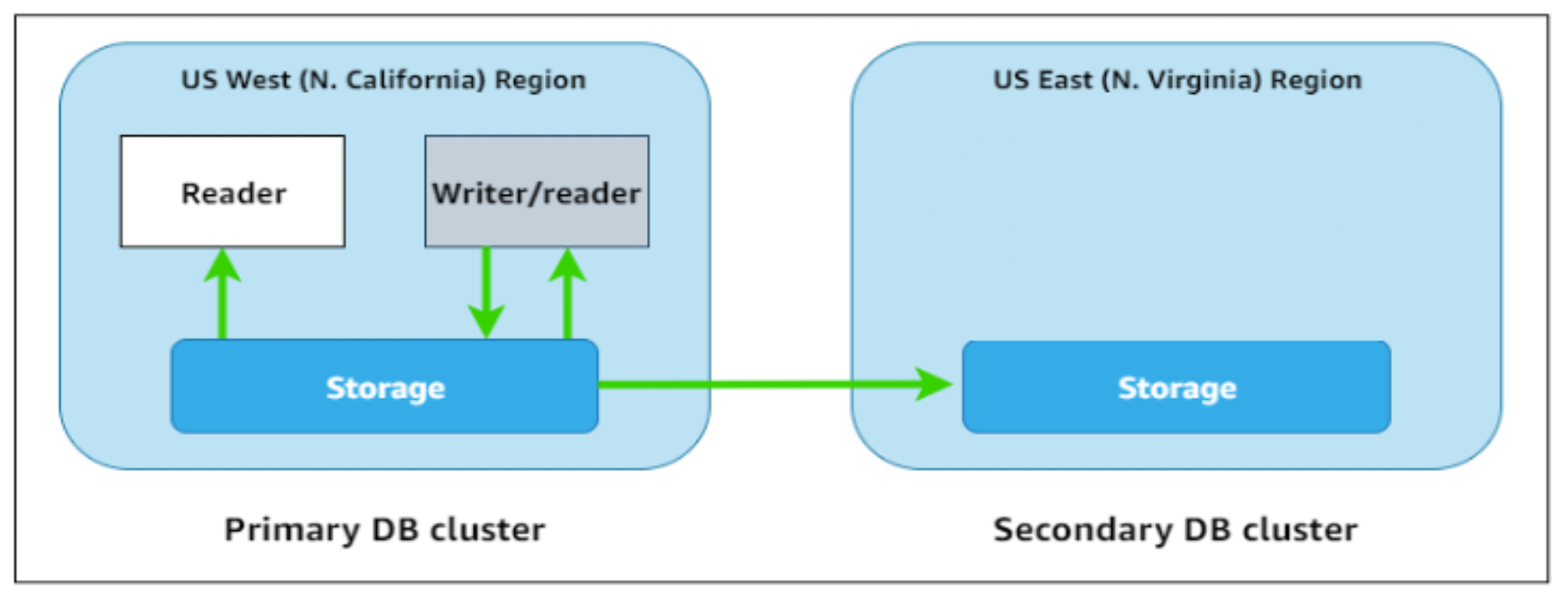
- https://aws.amazon.com/blogs/database/achieve-cost-effective-multi-region-resiliency-with-amazon-aurora-global-database-headless-clusters/_
- https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/aurora-global-database-getting-started.html#aurora-global-database-attach.console.headless
- https://aws.amazon.com/blogs/database/achieve-cost-effective-multi-region-resiliency-with-amazon-aurora-global-database-headless-clusters/
仕組み¶
▼ ウォームスタンバイ構成¶
ウォームスタンバイ構成の場合、メインリージョンにはプライマリーインスタンスとリードレプリカ (クラスターボリュームを含む) がおり、DR リージョンにはリードレプリカ (クラスターボリュームを含む) のみがいる。
メインリージョンで障害が起こった場合は、DR リージョンのリードレプリカがプライマリインスタンスに昇格する。
(1)-
メインリージョンで障害が発生する。
(2)-
DR リージョンのセカンダリークラスターがプライマリークラスターに昇格し、クラスター内のリードレプリカインスタンスがプライマリーインスタンスになる。
(3)-
メインリージョンのプライマリーインスタンスをフェイルオーバーさせる。
各種エンドポイントが無効化され、アクセスできなくなる (
NXDOMAINになる) 。 (4)-
メインリージョンの障害が回復する。
(5)-
DR リージョンをフェイルオーバーさせる。
メインリージョンのクラスターがプライマリークラスター、DRリージョンのクラスターがセカンダリークラスターになる。
注意点として、通常の Amazon Aurora の DB クラスターと比較して、機能が制限される。
▼ コールドスタンバイ構成¶
コールドスタンバイ構成の場合、メインリージョンにはプライマリーインスタンスとリードレプリカがおり、DR リージョンにクラスターボリュームのみがいる。
つまり、DR リージョンに Amazon Aurora の DB インスタンスがない。
アップグレード¶
Amazon Aurora Global DB では、プライマリークラスターとセカンダリークラスターを同時にアップグレードできない。
マイナーバージョンのアップグレードの場合は、セカンダリーDB クラスターからアップグレードする。
メジャーバージョンのアップグレードの場合は、Amazon Aurora Global DB 自体をアップグレードする。
スナップショット¶
Amazon Aurora Global DB では、リージョン間でデータをコピーしている。
そのため、メインリージョンのプライマリークラスターでスナップショットを作成し、これを DR リージョンへコピーするようにする。