回復性管理@マイクロサービス領域¶
はじめに¶
本サイトにつきまして、以下をご認識のほど宜しくお願いいたします。
01 回復性管理の設計¶
複数の回復性管理のパターンを組み合わせる。
02. タイムアウト¶
タイムアウトとは¶
何らかの処理 (例:通信など) を実行した後に結果の返却を待機する最大時間である。
タイムアウト時間¶
▼ マイクロサービスだけに着目する場合¶
送信元マイクロサービスよりも宛先マイクロサービスのタイムアウト時間を短くする。
マイクロサービス # 45秒
⬇⬆️︎
⬇⬆️︎︎︎
マイクロサービス # 30秒
⬇⬆️︎
⬇⬆️︎
マイクロサービス # 15秒
▼ サイドカープロキシにも着目する場合¶
送信元マイクロサービスよりもサイドカーのタイムアウト時間を短くする。
また、サイドカーよりも宛先マイクロサービスのサイドカーのタイムアウト時間を短くする。
アプリ # 45秒
⬇⬆️︎
⬇⬆️︎
サイドカー # 44秒
⬇⬆️︎
-------------- # マイクロサービス間の境界
⬇⬆️︎
サイドカー # 31秒
⬇⬆️︎
⬇⬆️︎
アプリ # 30秒
⬇⬆️︎
⬇⬆️︎
サイドカー # 29秒
⬇⬆️︎
-------------- # マイクロサービス間の境界
⬇⬆️︎
サイドカー # 16秒
⬇⬆️︎
⬇⬆️︎
アプリ # 15秒
タイムアウトの種類¶
▼ 接続タイムアウト (Connection timeout)¶
『オープンタイムアウト (Open timeout) 』ともいう
処理の中でも、特にリクエストの到達を待機する最大時間である。
これの場合、サーバーにリクエストを送信できていない。
▼ 読み取りタイムアウト (Read timeout)¶
処理の中でも、リクエストが到達した後に特にレスポンスの返信を待機する最大時間である。
これの場合、サーバーにリクエストを送信できており、サーバーがレスポンスを返信できない状態にある。
HTTPプロトコルのステータスコードでは、Gateway Timeout (504) が相当する。
▼ セッションタイムアウト (Session timeout)¶
記入中...
▼ アイドルタイムアウト (Idle timeout)¶
TCP接続中の無通信状態 (パケットの送受信がない状態) を許可する時間である。
03. リトライ¶
リトライとは¶
記入中...
04. ヘルスチェック¶
アクティブ¶
- HTTP (HTTPS)
- DNS
- TCP (UDP)
- 独自プロトコル
パッシブ¶
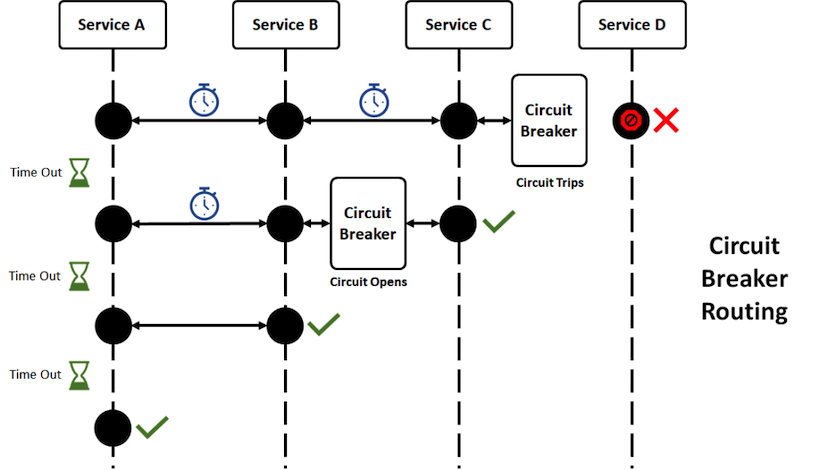
▼ サーキットブレイカー¶
マイクロサービス間の通信方式がリクエストロプライパターンの場合の障害対策である。
宛先マイクロサービスからのレスポンスに外れ値 (500系ステータス、Gateway系ステータスなど) の閾値を設定しておく。
運用中にこれを超過すると、送信元マイクロサービスはタイムアウトになるまで処理を待機する。
その間、送信元マイクロサービスは他の処理を実行できなくなってしまうため、これを防ぐ。
- 宛先マイクロサービスに障害 (あるいは設定した閾値の超過) が発生する
- 宛先マイクロサービスへのルーティングを停止し、エラーステータス (
503など) のレスポンスを送信元マイクロサービスに返信する。 - 障害が回復次第、ルーティングを再開する。
blast-radiusを最小限にできる。
06. フォールバック¶
▼ フォールバックとは¶
リトライの失敗やサーキットブレイカーで宛先マイクロサービスからデータを取得できなかった場合に、代わりにデータを返信する。
▼ 実装¶
- 静的ファイルの返信
- キャッシュを使用した前回の処理結果の返信
- ユーザーによらないデータ (広告、ランキングなど) の返信
- https://engineering.mercari.com/blog/entry/2018-12-23-150000/
- https://www.geeksforgeeks.org/microservices-resilience-patterns/#properly-explain-common-resilience-patterns
- https://learn.microsoft.com/ja-jp/dotnet/architecture/microservices/implement-resilient-applications/implement-circuit-breaker-pattern
07. バルクヘッド¶
マイクロサービスごとにハードウェアリソースや接続プールの上限を設け、他のマイクロサービスへの影響を防ぐ。
08. レートリミット¶
09 .DBデータのキャッシュ¶
頻繁に使用するデータをマイクロサービスのメモリに保存し、他のマイクロサービスやDBへの接続を最小限に抑える。
10. エラーとエラーハンドリング¶
エラーとは¶
プログラムの実行が強制的に停止されるランタイムエラー (実行時エラー) 、停止せずに続行される非ランタイムエラー、に分類される。
エラーハンドリングの意義¶
▼ DBにとって¶
DB更新系の処理の途中にエラーが発生すると、DBが中途半端な更新状態になってしまう。
そのため、メソッドコールしたクラスでエラーを検出し、これをきっかけにロールバック処理を実行する必要がある。
注意点として、下層クラスのエラーの内容自体は握りつぶさずに、スタックトレースとしてメソッドコールしたクラスでロギングしておく。
▼ ソフトウェア開発者にとって¶
エラーが画面上に返却されたとしても、これはソフトウェア開発者にとってわかりにくい。
そのため、エラーをメソッドコールしたクラスで検出し、ソフトウェア開発者にわかる言葉に変換した例外としてスローする必要がある。
注意点として、下層クラスのエラー自体は握りつぶさずに、スタックトレースとしてメソッドコールしたクラスでロギングしておく。
▼ ユーザーにとって¶
エラーが画面上に返却されたとしても、ユーザーにとっては何が起きているのかわからない。
また、エラーをメソッドコールしたクラスで検出し、例外としてスローしたとしても、ソフトウェア開発者にとっては理解できるが、ユーザーにとっては理解できない。
そのため、例外スローを別の識別子 (例:boolean値) に変えてメソッドコールしたクラスに持ち上げ、最終的には、これをポップアップなどでわかりやすく通知する必要がある。
これらは、サーバーサイドのtry-catch-finally文や、フロントエンドのポップアップ処理で実現する。
注意点として、子クラスのエラー自体は握りつぶさずに、スタックトレースとしてメソッドコールしたクラスでロギングしておく。
エラーハンドリングのステップ¶
エラーハンドリングは以下の4ステップからなる。
(1)-
エラー検出
(2)-
例外スロー
(3)-
例外キャッチ
(4)-
ロギング
エラーのエスカレーション¶
▼ マイクロサービス内¶
マイクロサービス内では、例外でエラーをエスカレーションする。
各レイヤーでは例外をスローするだけに留まり、スローされた例外を対処する責務は、より上位レイヤーに持たせる。
より上位レイヤーでは、そのレイヤーに合った例外に詰め替えて、これをスローする。
▼ マイクロサービス間¶
マイクロサービス間では、ステータスコードでエラーをエスカレーションする。
宛先のマイクロサービスから受信したステータスコードは、送信元にそのまま返信するように設計する。
最終的に、フロントエンドアプリでステータスコードをユーザーにわかるメッセージに変換する。

▼ フロントエンド領域とマイクロサービス領域間¶
フロントエンドは、マイクロサービスからエスカレーションされたステータスコードを取得し、画面上のポップアップで警告文として表示する。