オンコールとインシデント管理@監視¶
はじめに¶
本サイトにつきまして、以下をご認識のほど宜しくお願いいたします。
01. オンコール¶
オンコールとは¶
アラートが通知された時に、エラー修正の担当者に連絡できる状態 (メールアドレス、電話番号、SMS、など) にあること。
オンコール対応時間¶
▼ グローバル企業の場合¶
グローバル企業の場合、世界各地にオンコールセンターを配置している。
各オンコールセンターには時差があるため、特定の時間に、どこかの国でオンコールセンターが必ず営業している。
アラートのタイミングで営業しているオンコールセンターに通知を送信するため、『24時間365日対応可能』といったサービスを提供できる。
02. アラートの設定¶
アラート発火の事前検証¶
▼ システムの実際値の変更¶
アラートが発火するように、システムの実際値を調節 (例:負荷を高める) し、アラートが発火するかを検証する。
▼ 閾値の変更¶
必ずアラートが発火するような閾値 (例:ゼロ) に変更し、アラートが発火するかを検証する。
アラートの付加情報¶
▼ イベントの内容¶
- タイムスタンプ
- ログステータス
- ログメッセージ
▼ ラベル¶
- 実行環境名
- リージョン名
- Cluster名
- Node名
- Namespace名
- Pod名
- マイクロサービス名
- コンテナ名
02-02. エラーイベント重要度 (severity) レベル¶
エラーイベント重要度レベルとは¶
全ての事象をエラーイベントとして見なしてしまうと、アラート疲れしてしまう。
そのため、どのようなイベントをエラーイベントと見なしてアラートを通知するか否かを確認するか、を決めておく必要がある。
また、レベルに応じてアラート先のチャンネルを区別すると良い。
| メトリクスの単位 | エラーイベントと見なす閾値例 | 閾値とするメトリクス例 | 補足 |
|---|---|---|---|
| パーセント | 60% |
CPU使用率、メモリ使用率、など | 平常時は30%である仮定し、エラーイベントと見なす閾値を60%に設定することが多い。 |
| カウント | 1〜3個 |
ログステータス、ステータスコード、など | どのログステータスやステータスコードをカウントするかを決める必要がある。 |
| バイト数 | メトリクスによる | メモリの空きサイズ、ストレージのスワップ領域の使用サイズ、など | メトリクスによって、エラーイベントと見なせるバイト数が異なる。 |
カウントする必要があるステータスの判断¶
▼ ステータスの重要度レベルへの変換¶
ステータスは、重要度を判断しやすいように、重要度レベルに変換して考える。
該当の重要度レベルに当てはまるステータスのみを、エラーイベントとしてカウントする。
| 重要度レベルの例 | エラーイベントと見なし、アラートを通知するか否かの判断例 |
|---|---|
| critical | する |
| warning | しない |
| information | しない |
▼ ログステータスの場合¶
エラーイベントと見なすログステータスの目安は以下の通りである。
| ログステータス | 説明 | 重要度レベルへの変換例 |
|---|---|---|
| emergency | システムが使用できない状態にある緊急事態 | critical |
| alert | 早急に対応すべき事態 | critical |
| critical | 対処すべき重要な問題 | critical |
| fatal | 対処すべき重要な問題 | critical |
| error | 何かが失敗している | criticalまたはwarning |
| warn | 普通ではないことが発生したが、心配する必要はない | criticalまたはwarning |
| notice | いたって普通だが、注意すべきことが起こっている | information |
| info | 知っておくといいかもしれない情報 | information |
| debug | 問題が起こっている場所を知るのに有効な情報 | information |
▼ ステータスコードの場合¶
エラーイベントと見なすステータスコードの目安は以下の通りである。
各ステータスコードをバラバラに扱うことは大変なため、系ごとにまとめて扱えるように、レベルを割り当てる。
| ステータスコード | 本番環境のアラートの目安 | 重要度レベルへの変換例 |
|---|---|---|
500系 |
する | critical |
400系 |
どちらでも | warning |
300系 |
しない | information |
200系 |
しない | information |
03. インシデント管理¶
インシデントとは¶
サービスの停止を起こし得る想定外のイベントのこと。
インシデント管理¶
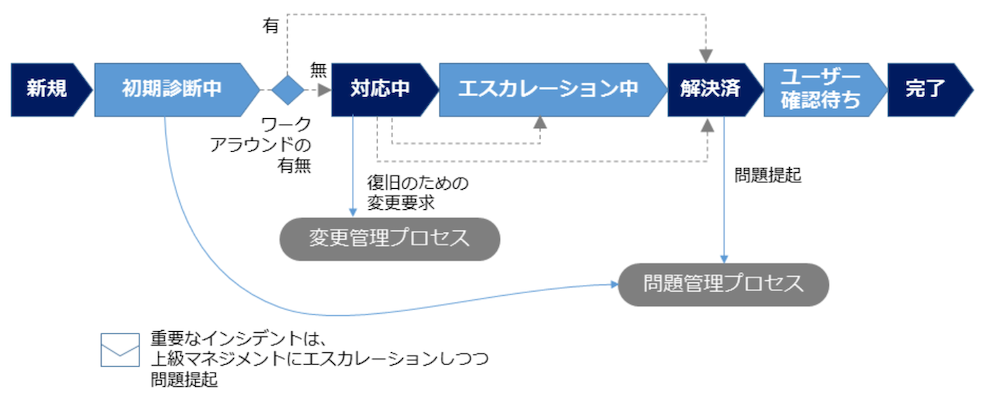
一次オンコール担当は、エラーを解決するためのタスクを作成し、完了させる。
エラーがインシデントの場合、担当者はこれを迅速に解決する必要がある。
また、二次担当者に通知をエスカレーションさせる。
これらを自動化するためのツールがいくつかある。
*技術ツール例*
- PagerDuty
- Splunk
- On-call
インシデントの解決フェーズ¶
▼ 解決フェーズとは¶
インシデントとして見なされたアラートが、どの程度解決できたのかを可視化する必要がある。
▼ 解決フェーズの種類¶
| 解決フェーズ | 説明 |
|---|---|
| 発火 | アラートがインシデントとして見なされ、タスクが作成された。 |
| 認知 | インシデントのタスクに対応中であるが、まだ解決できていない。 |
| 解決済み | インシデントのタスクを解決した。 |
インシデント重要度レベル (severityレベル)¶
▼ インシデント重要度レベルとは¶
全てのインシデントを同じ優先度で対応すると、重要度の高いインシデントの解決が遅れてしまう。
そのため、インシデントの優先度付けが必要がある。
| エラーイベントの重要度レベル | 優先度 |
|---|---|
| high | 即時に解決する必要がある。 |
| medium | 24時間以内に解決する必要がある。 |
| low | いつかは解決する必要がある。 |
| notification | 解決する必要はない。 |
一次オンコール担当者の作業¶
▼ Slackの場合¶
ここでは、Slackをインシデント管理ツールとして、Slackに通知されたアラートをオンコール担当者が作業する。
(1)-
CloudWactchアラームからSlackのチャンネルに、アラートが通知される。ただし、Slackからオンコール担当者に電話をかけることはできない。
(2)-
オンコール担当者は、Slackに通知されたアラートを確認する。
(3)-
アラート名 (例:prd-foo-ecs-container-laravel-log-alarm) から、CloudWatchアラームを探す。
(4)-
アラートがどのロググループに紐づいているかを探す。執筆時点 (2021/12/09) では、AWSの仕様ではこれがわかりにくくなっている。メトリクスフィルターが設定されているロググループは、アラームに紐づいている可能性があり、メトリクスフィルターで作成されているメトリクス名 (例:ErrorCount) がアラームに記載されたものであれば、紐づいているとわかる。
(5)-
Log Insightsを使用して、ロググループの直近のエラーログを抽出する。
-- 小文字と大文字を区別せずに、Errorを含むログを検索する。
fields @timestamp, @message, @logStream
| filter @message like /(?i)(Error)/
| sort @timestamp desc
| limit 100
(6)-
クエリの結果から、アラートの原因になっているエラーを見つける。CloudWatchのタイムスタンプとSlackのアラートの通知時刻には若干のタイムラグがある。
(7)-
クエリの結果をコピーし、アラートのThreadに貼り付ける。
[2021-12-01 00:00:00] request.ERROR: Uncaught PHP Exception *****
(8)-
ログイベントが許容できるものあれば、保留として、その旨をエスカレーションする。
(9)-
ログイベントがインシデントであれば、その旨をエスカレーションする。また、タスク化し、迅速に対応する。
(10)-
ログイベントがインシデントでないエラーイベントであれば、その旨をエスカレーションする。タスク化し、時間のある時に対応する。
04. インシデント管理の組織化¶
インシデントコマンドシステムに基づく役割分離¶
▼ インシデントコマンドシステムとは¶
インシデントの発生時に、組織が混乱せずに問題に対処できるようにするためのマネージメント手法のこと。
▼ 指揮¶
インシデントの状況把握を担当する。
また、インシデント担当チームを組織し、各担当者にタスクを割り振る。
▼ 実行¶
インシデントの解決を担当する。
▼ 計画¶
ステークホルダーへの状況報告やドキュメントの作成を担当する。
▼ 後方支援¶
作業者のサポートを担当する。
作業者間引継ぎの調整、夕食の発注、などがある。
05. アラート、インシデントの通知抑制¶
アラートの通知抑制¶
▼ アラートの抑制とは¶
通知不要なアラートや、実際には重要度の高くないアラートの通知が頻発する場合、アラート疲れしてしまう。
そういった場合は、アラートの通知を抑制する。
▼ エラーイベントの重要度レベルの調節¶
アラートの重要度レベルを調節し、通知する必要があるアラートを選別する。
▼ アラートの一時無効化¶
特定の期間に発生したアラートを無視するようにし、アラートが一定期間だけ通知されないようにする。
▼ アラートのグループ化¶
いくつかのアラートをグループ化するようにし、アラートの通知数を減らす。
▼ アラートの条件の調節¶
アラートの条件となる期間を拡大し、加えてエラーイベントの閾値を緩和するようにし、アラートの通知数を減らす。
インシデントの通知抑制¶
▼ インシデントの抑制とは¶
全てのインシデントを同じ優先度で対応すると、重要度の高いインシデントの解決が遅れてしまう。
そういった場合は、インシデントの通知を抑制する。
▼ 特定のシステムを無視¶
特定のシステムにて、発生したインシデントを全て無視し、インシデントが恒久的に通知されないようにする。
▼ インシデントの一時無効化¶
特定のシステムにて、指定した期間に発生したインシデントを無視し、インシデントが一定期間だけ通知されないようにする。
▼ エラーイベントの重要度レベルの調節¶
特定のシステムにて、インシデントごとに重要度レベルを調節し、インシデントの優先度付けする。
特定のインシデント以外は通知されないようにする。
▼ インシデントのグループ化¶
特定のシステムにて、いくつかのインシデントをグループ化するようにし、インシデントの通知数を減らす。
06. インシデント管理の事後評価¶
MTxxメトリクス¶
▼ MTxxメトリクスとは¶
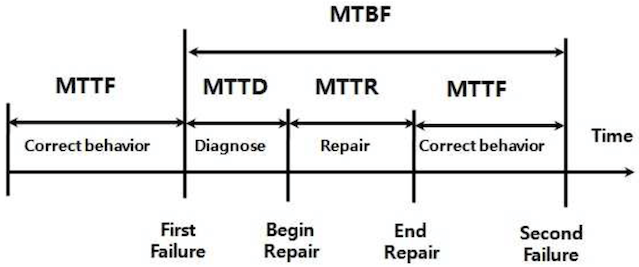
| メトリクス名 | 補足 | |
|---|---|---|
| MTTF:Mean Time To Failure | 稼働開始地点から障害開始地点までの平均稼働時間のこと。どのくらいの間、正常稼働していたのかがわかる。 | ・https://e-words.jp/w/MTTF.html |
| MTBF:Mean Time Between Failure | 特定の障害と次の障害の障害開始地点までの平均稼働時間のこと。正常稼働と異常稼働を合わせた全体の稼働時間がわかる。 | ・https://www.seplus.jp/dokushuzemi/fe/fenavi/easy_calc/availability/ |
| MTTD:Mean Time To Diagnose | 障害の障害開始地点から修復開始地点までの平均障害時間のこと。異常を検出するまでにどのくらいの時間がかかったのかがわかる。 | |
| MTTR:Mean Time To Repair | 障害の復旧開始地点終了から終了地点間までの平均障害時間のこと。どのくらいの間、復旧せずに異常稼働していたのかがわかる。可用性テスト時の目標値のRTOとは異なることに注意する。 | ・https://www.seplus.jp/dokushuzemi/fe/fenavi/easy_calc/availability/ |
▼ 稼働率¶
システムの実際の稼働時間割合を表す。
以下の計算式で算出できる。
(稼働率)
= (動作した時間) ÷ (全体の時間)
この数式は、以下ように書き換えられる。
(稼働率)
= (MTBF) ÷ (MTBF + MTTR)
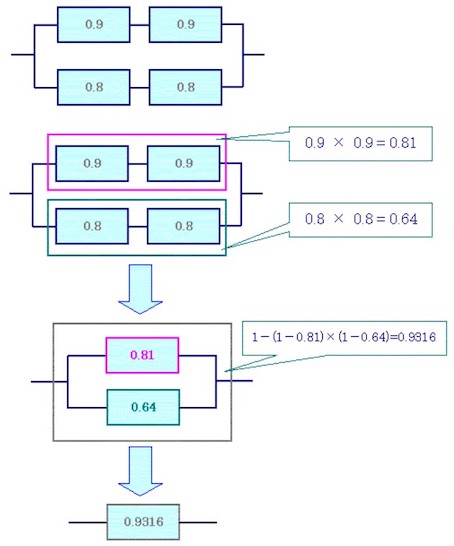
システムが冗長化されている場合、全てのインスタンスの非稼働率をかけて、全体から引くことにより、稼働率を算出できる。
(稼働率)
= 1 - (1 - 稼働率) × (1 - 稼働率)
*例*
システムが冗長化されている例を示す。
すでに稼働率は算出されているものとする。
全てのインスタンスの非稼働率をかけて、全体から引く。
1 - (1-0.81) × (1-0.64) = 0.9316
▼ MTxxメトリクスのインシデント管理への適用¶
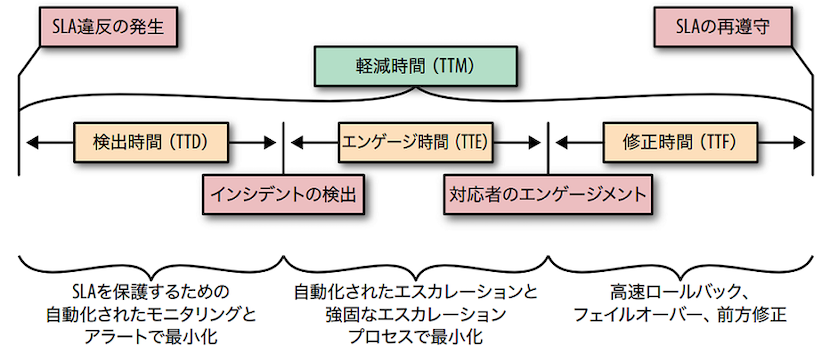
| メトリクス名 | 説明 | |
|---|---|---|
| MTTD | インシデントが起こってから、これがオンコール担当にアラートされるまで。 | |
| MTTE | インシデントがオンコール担当にアラートされ、オンコール担当本人/アサインされたエンジニアがタスクとして着手するまで。 | |
| MTTF | オンコール担当がタスクに着手してから、これを完了するまで。 |
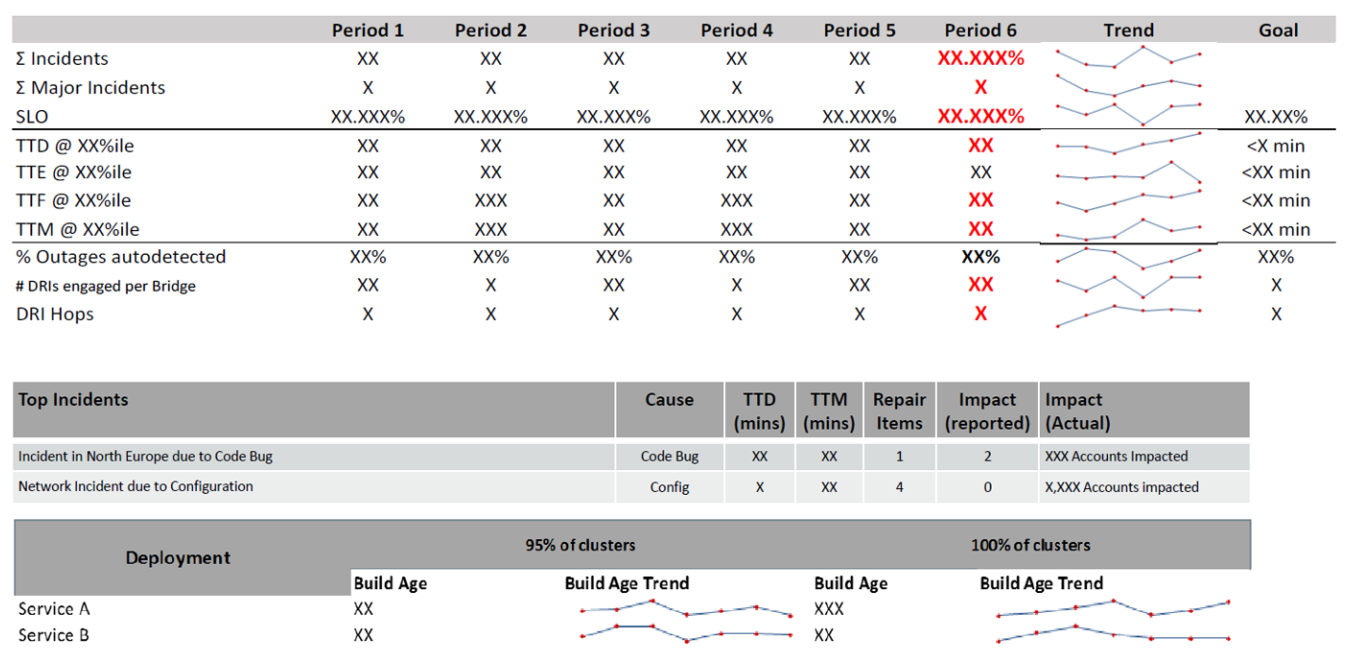
▼ ダッシュボード¶
MTxxメトリクスをダッシュボード化する。
実際に時間と目標時間を比較すれば、今回のインシデント管理の良し悪しを判断できる。
そのため、インシデント管理自体をソフトウェア開発と同様に反復的に改善しやすくになる。
DRI Hops (インシデントの直接的に責任者) の値を使用して人的コストを可視化することにより、エンジニアリングマネージャがインシデント管理を扱いやすくなる。
ポストモーテム¶
▼ ポストモーテムとは¶
アラートで通知されたインシデントがビジネスに大きな影響を与えた場合、振り返りとして、ポストモーテムを作成する。
ポストモーテムは、障害報告書とは異なり、原因特定とシステム改善に重きを置いた報告書である。
障害報告書は、責任の報告の意味合いが強くなってしまう。
▼ 独自テンプレート¶
# ポストモーテム ## タイトル ## 日付 ## 担当者
\*\*※担当者を絶対に責めず、障害は誰のせいでもないという意識を強く持つ。 \*\* ##
原因と対応 **※原因特定とシステム改善を最優先にすること** ##
システム的/収益的な影響範囲 ## 幸運だったこと ## 仕組みの改善策
\*\*※『以後は注意する』ではなく、再発しない仕組み作りになるようにする。 \*\* ##
障害発生から対応までのタイムライン
▼ PagerDutyの事例¶
PagerDuty社が公開しているテンプレートがある。
# ポストモーテム ## 全体の要約 ## 何が発生したか ## 原因 ## 解決方法 ## 影響 -
問題の発生期間 - 影響を受けたユーザー数 - 発生した技術サポートのチケット数 -
未解決のエラーイベント数 ## 担当者 - 担当者名 - 担当補佐名 ## タイムライン -
原因が発生した時刻 - ## 対応結果 - うまくいったこと - うまくいかなかったこと ##
インシデントのタスク ## メッセージ - 社内への周知内容 - 社外への周知内容