Prometheus@CNCF¶
はじめに¶
本サイトにつきまして、以下をご認識のほど宜しくお願いいたします。
01. Prometheusの仕組み¶
アーキテクチャ¶
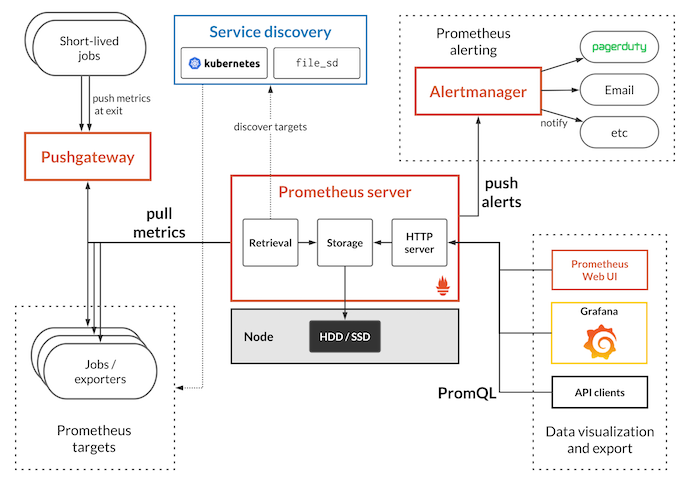
Prometheusは、prometheusサーバー (Retrieval、ローカルの時系列ストレージ、HTTPサーバー) から構成されている。
Kubernetesリソースに関するメトリクスのデータポイントを収集し、分析する。
また設定された条件下でアラートを作成し、Alertmanagerに送信する。
02. prometheusサーバー¶
prometheusサーバーとは¶
メトリクスのデータポイントを収集し、管理する。
またPromQLに基づいて、データポイントからメトリクスを分析できるようにする。
9090番ポートで、メトリクスのデータポイントをプルし、加えてGrafanaのPromQLによるアクセスを待ち受ける。
例えば、prometheus-operatorを使用した場合は、各コンポーネントのデフォルト値は、/etc/prometheus/prometheus.ymlファイルで定義する。
02-02. Retrieval¶
Retrievalとは¶
監視対象からデータポイントを定期的に収集する。
設定ファイル¶
設定ファイルは.yamlファイルで定義する。セットアップ方法によって設定ファイルが配置されるディレクトリは異なる。
例えば、prometheus-operatorを使用した場合は、prometheusコンテナの/etc/prometheus/rulesディレクトリ配下に配置される。
$ ls -1 /etc/prometheus
certs/
console_libraries/
consoles/
prometheus.yml # グローバルの設定ファイル
rules/ # ルールの設定ファイル
$ ls -1 /etc/prometheus/rules/prometheus-prometheus-kube-prometheus-prometheus-rulefiles-0
prometheus-eks-worker-rule.yaml
prometheus-prometheus-kube-prometheus-alertmanager.rules.yaml
prometheus-prometheus-kube-prometheus-general.rules.yaml
...
prometheus-prometheus-kube-prometheus-node.rules.yaml
prometheus-prometheus-kube-prometheus-prometheus-operator.yaml
prometheus-prometheus-kube-prometheus-prometheus.yaml
02-03. HTTP server¶
HTTP serverとは¶
データポイントを参照するためのエンドポイントを公開する。
PromQLをリクエストとして受信し、ローカルストレージからデータポイントをメトリクスとして返却する。
エンドポイント¶
▼ /metrics¶
Prometheusで使用できるメトリクスの一覧を取得できる。
$ curl http://localhost:3000/metrics
02-04. ローカルストレージ¶
ローカルストレージとは¶
Prometheusは、dataディレクトリ配下をTSDBとして、収集した全てのメトリクスを保管する。
dataディレクトリ¶
▼ dataディレクトリとは¶
Prometheusは、収集したデータポイントをデフォルトで2時間ごとにブロック化し、dataディレクトリ配下に配置する。
現在処理中のブロックをメモリ上に保持し、同時にストレージの/data/walディレクトリにもバックアップとして保存する (補足としてRDBMSでは、これをジャーナルファイルという) 。
これにより、Prometheusで障害が発生し、メモリ上のブロックが削除されてしまっても、ストレージからブロックを復元できる。
data/
├── 01BKGV7JC0RY8A6MACW02A2PJD/ # ブロック
│ ├── chunks/
│ │ └── 000001
│ │
│ ├── tombstones
│ ├── index
│ └── meta.json
│
├── chunks_head/
│ └── 000001
│
└── wal # WALによるバックアップ
├── 000000002
└── checkpoint.00000001/
└── 00000000
Prometheusの稼働するコンテナやNodeに接続すれば、dataディレクトリを確認できる。
$ kubectl exec -it prometheus -n prometheus -- sh
/data $ ls -la
drwxrwsr-x 3 1000 2000 4096 Jul 6 05:00 01BKGV7JC0RY8A6MACW02A2PJD # ブロック
drwxrwsr-x 3 1000 2000 4096 Jul 8 11:00 01BKTKF4VE33MYEEQF0M7YERFA
...
▼ 注意点¶
TSDBのディレクトリはNodeにマウントされるため、Nodeのストレージサイズに注意する必要がある。
ストレージサイズが大きすぎると、Prometheusのコンテナが起動できなくなることがあり、その場合はNode側でメトリクスのブロックを削除する必要がある。
対処方法として、データポイント数を減らし、データポイント全体のデータサイズを小さくすると良い。
独自TSDB¶
▼ 独自TSDBとは¶
Prometheusでは、TSDB (dataディレクトリ配下) を採用している。
▼ データソース型モデル (仮定)¶
データソース型モデルとメトリクス型モデルがあり、Prometheusではいずれを採用しているのかの記載が見つかっていない。
そのため、データソース型モデルと仮定してテーブル例を示す。
| timestamp | cluster | namespace | ... | cpu | memory |
|---|---|---|---|---|---|
2022-01-01 |
foo-cluster |
foo-namespace |
... | 10 |
10 |
2022-01-02 |
foo-cluster |
foo-namespace |
... | 20 |
30 |
02-05. リモートストレージ¶
リモートストレージとは¶
Prometheusは、ローカルストレージにメトリクスを保管する代わりに、TSDBとして動作するリモートストレージ (AWS Timestream、Google Cloud Bigquery、VictoriaMetrics、...) に保管できる。
remote-write-receiverを有効化すると、リモートストレージの種類によらず、エンドポイントが『https://<IPアドレス>/api/v1/write』になる (ポート番号はリモートストレージごとに異なる) 。
Prometheusと外部のTSDBの両方を冗長化する場合、冗長化されたPrometheusでは、片方のデータベースのみに送信しないと、メトリクスが重複してしまうGrafanaのようにリアルタイムにデータを取得し続けることはできない。
リモート読み出しを使用する場合、Prometheusのダッシュボード上でPromQLを使用することなく、Grafanaのようにリアルタイムにデータを取得できるようになる。

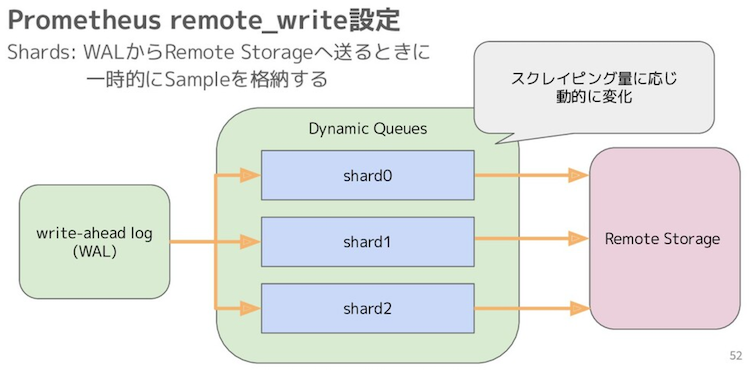
ダイナミックキュー¶
リモートストレージにメトリクスを送信する場合、送信されたメトリクスをキューイングする。
ダイナミックキューは、メトリクスのスループットの高さに応じて、キューイングの実行単位であるシャードを増減させる。
性能設計¶
Prometheusは、現在処理中のブロックをメモリ上に保持し、同時にストレージの/data/walディレクトリにもバックアップとして保存する
そのため、十分量のメモリの割り当てが必要である。
レコーディングルール¶
事前に定義したPromQLの結果をTSDBに保管できる。
TSDBのデータ量がむやみに増えないように、最低限のレコーディングルールを定義する。
03. Alertmanager¶
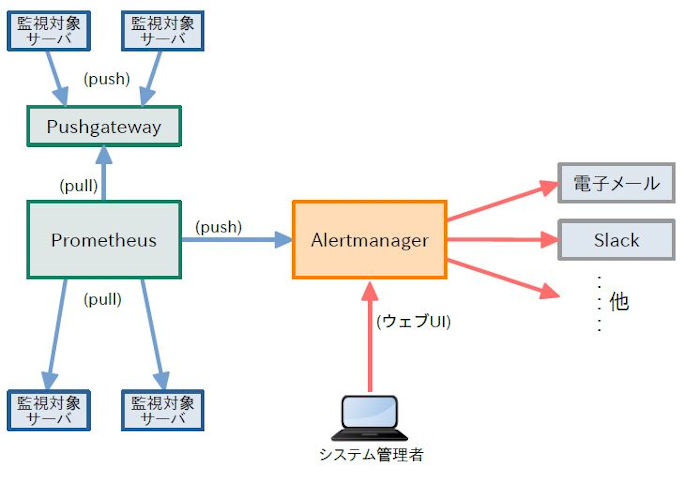
Alertmanagerとは¶
Prometheusのアラートを受信し、特定の条件下で通知する。
受信したアラートは、AlertmanagerのUI上に表示される。
Storage¶
Alertmanagerのデータを永続化する。
# Node内 (AWS EKSのEC2ワーカーNodeの場合)
$ ls -la /var/lib/kubelet/plugins/kubernetes.io/aws-ebs/mounts/aws/ap-northeast-1a/vol-*****/alertmanager-db/
Silence¶
受信したアラートの通知を一時的に無効化する。
Silenceされている期間、無効化されたアラートはAlertmanagerのUI上から削除され、通知されなくなる。
04. PushGateway¶
PushGatewayとは¶
PrometheusがPush型メトリクスを対象から収集するためのエンドポイントとして動作する。
05. ServiceDiscovery¶
ServiceDiscoveryとは¶
Pull型通信の宛先のIPアドレスが動的に変化する (例:スケーリングなど) 場合、宛先を動的に検出し、データポイントを収集し続けられるようにする。
06. マネージドPrometheus¶
Prometheusのコンポーネントを部分的にマネージドにしたサービス。
執筆時点 (2023/05/16時点) では、リモートストレージ、Alertmanager、をマネージドにしてくれる。